What is a Data Lake?
The data lake is Storing petabytes of data on a repository system in its natural form without any transformation, analytics or any data left behind on data source. In other words, Data lake is a repository for storing raw data in an untransformed way, and all data must be retrieved from source data location.- In the case of databases, data is always inserted, updated or retrieved. So It will become inefficient to apply transformations on it to obtain some logic behind the whole data set.
- Data lakes are helpful in this case as they aren’t being used as a back end for any application or software. So it will provide more freedom to apply transformation and have analytics on data in it.
- Also, Data present on data lakes is in raw object format. We can use stream events to load data from sources to Data lakes and then apply schedulers that complete the required job.
- We can perform analytics as well as Machine learning on data available at Data Lake.
What is Azure Data Lake?
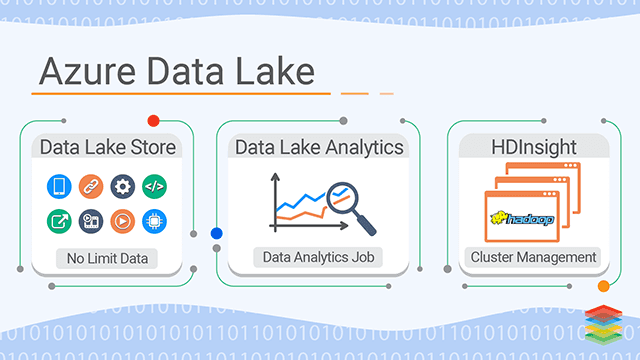
Microsoft also Provides Data Lake support to Azure cloud. Azure supports data from almost every Data sources such as databases, NoSQL, Files and so on.Azure Data Lake contains the following components -- Data Lake Store – This includes the Data in raw object form with no particular schema type defined. It is based on Apache Hadoop File System (HDFS). It is a no limit data store.
- Analytics Job Service – This is built upon YARN cluster to manage analytics via Spark, clusters and U-SQL
- Data is ingested from distinct and various data sources at Azure Data lake.
- That data is then prepared for some transformations to be loaded for Data warehouse and to analyze it.
- That Analyzed data later can be published by using software like PowerBI etc. to consume it into reports, presentations, insights and so on.
Learn about Azure's Data Catalog Services
What are the advantage Of Azure Data Lake?
- Highly flexible and scalable
- Allows streamlining data storage for enterprise's needs.
- A massive amount of data can be processed simultaneously, providing quick access to actionable insights.
- Data Lake stores can store every kind of Data like multimedia, logs, XML, sensor data, social data, binary, chat, and people data.
- Unlimited data storage and file size.
- Effortlessly massive analytics workloads for in-depth analytics.
- It supports schema-less storage.
What is Azure Data Lake Storage?
Azure has Data lake storage based on Hadoop File system and with fast test modules. Azure Data Lake Storage Gen 2 storage is based on Azure Blob storage with Azure Data Lake Storage Gen 1 capabilities support such as file system Semantics, File level security, etc. Gen2 of Azure data lake storage has following benefits over Gen1 -
- Hadoop compatible access to the file system by using open source platforms such as Hdinsights, Hadoop, Cloudera, etc.
- It has security as a superset of POSIX permissions.
- It is using Blob storage, so it is more cost effective than Gen1 Storage.
- ADFS (HDFS compatible file system for azure data lake) drivers are more optimized for data analytics purposes.
What are the types of storage format in Azure Data Lake?
Azure supports the following file formats type -- Text Format
- JSON Format
- Parquet Format
- ORC Format
- AVRO Format
- GZIP
- Deflate
- Bzip2
- ZipDeflate
What is the Storage Capacity of Azure Data Lake?
Azure plays big in terms of data storage capacity on the data lake store. One file size can be One petabyte which is higher than other cloud solutions. Moreover, we are allowed to store trillions of files with each file size of one petabyte. This is massive or huge or whatever you call it. Isn’t it? Once you have stored that much data you don’t have to worry about writing code again and generate that much information again. You can use that data until you want to use and access.
What are the Restrictions on Data Storage on Azure Data Lake?
The big Question that arises for storage and analytics is What data formats are supported and Is There any restriction on it? So, the answer to these questions in Azure context is -
- Data of structured, unstructured and Semi-structured form is supported by Azure Data lake store
- There are no restrictions on data, i.e. data of every time and from any source can be loaded to Azure storage and can be processed by using frameworks such as Spark, Hive, etc
What is Azure Data Lake Analytics and its capabilities ?
As of now, We knew that we could analyze the data for analytics purpose and we don’t have to worry about data sizes also. Now, the next thing is what the capabilities of Azure are in terms of analytics? So, Azure is capable of doing many things, such as -- It can start the job within seconds with as there are no virtual machines or cluster loading like stuff to wait for.
- We have to pay for only job processing.
- U-SQL is used to parallelize the scaled job massively. U-SQL is simple and has some advanced azure functions support for data loading and transformations.
- In-built intelligence that provides insights related to improve performance and debug while the job is still running. It helps in reducing cost.
- Integrations with Hdinsights provide a commonplace to monitor all cluster as an obvious solution.
- Streaming, interactive querying, and ETL are some concepts that can be used via analytics frameworks such as Hdinsights and Spark
What are the features of Azure Data Lake Analytics ?
- Azure provides high throughput on data lake for raw or any other given data format for analytics and real-time reporting and monitoring.
- It is highly scalable and auto-scalable with the flexibility of payment for processing.
- U-SQL can process any data with SQL like syntax and additional ADFS driver functions defined by Azure custom functions.
- Highly available data warehouse service from premise where many-on tools can be used to investigate on data for analytics, reporting, monitoring, and Business Intelligence.
Conclusion
Let’s review about Azure services Data lake and Analytics capabilities -- We can store almost unlimited data
- Instant job processing without waiting for cluster to load
- Business Intelligence and Analytics can be performed with Microsoft powered engines to run those operations
- No source data loading restriction, and much more
All these points conclude that Azure has excellent capabilities to fulfill almost any data or more precisely big data-related needs. Azure has high analytical power and low-cost service that one can do the same work on Azure with up to 95% less cost with in-built intelligence debugging support and can help to improve more by applying analytics on data.
What's Next?- Wondering how to get started, talk to our expert.
- Choose the Right cloud-based storage solution for your business