
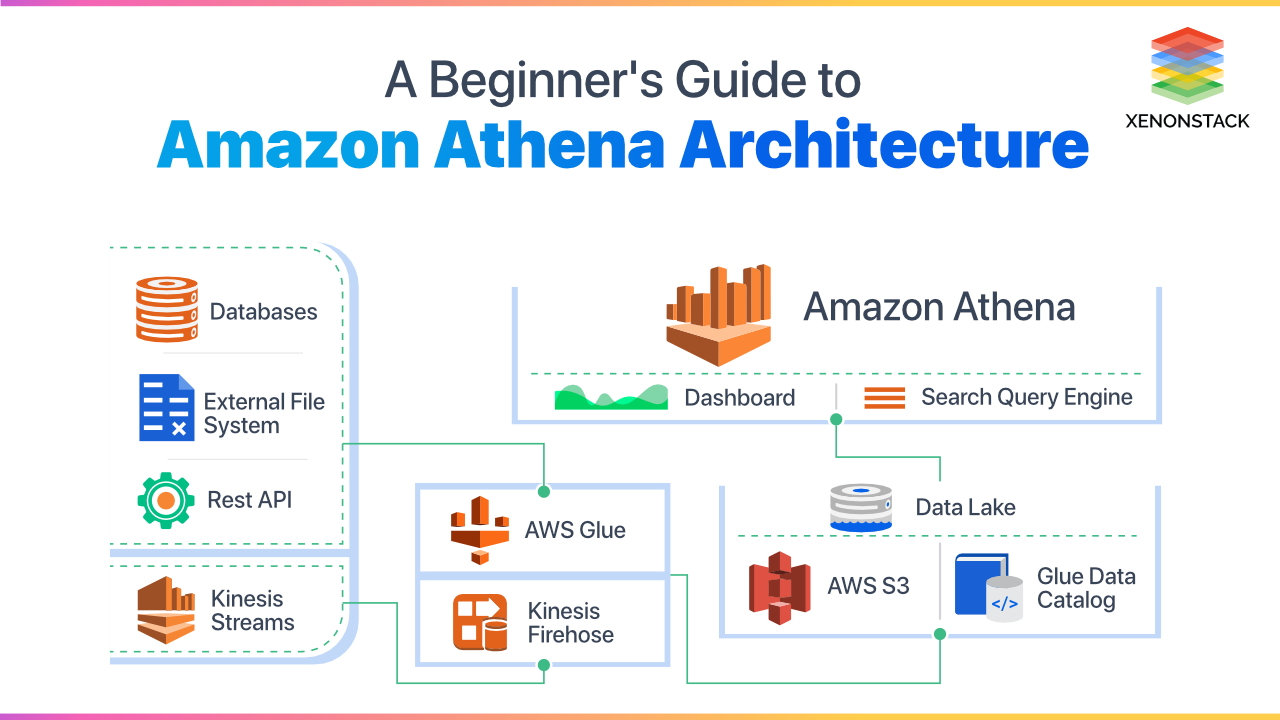
Introduction to Amazon Athena
Amazon Athena is a serverless interactive query service or interactive data analysis tool which is used for processing complex queries and in a lesser amount of time. Due to its serverless feature, it needs no infrastructure to manage or to setup. It can quickly analyze the data with the help of Amazon S3 using standard SQL. It even does not need to load the data in Athena.
All we require to do is to point to the data in Amazon S3, define the particular schema and start querying using the standard SQL. With the help of Amazon Athena, we can process any of data, whether it is structured, semi-structured or unstructured data, i.e., it can handle the data in CSV, avro or in columnar formats like parquet and orc.
A type of data warehouse service in the Cloud which is fully managed, reliable, scalable and fast and is a part of Amazon’s Cloud Computing. Click to explore about, Guide to Amazon Redshift
Why Choose Amazon Athena?
One of the best reasons for choosing Amazon Athena is that it provides serverless Querying of the data which is stored in Amazon S3 with the help of standard SQL. It also provides support to various data formats like structured, semi-structured and unstructured. Some of the other reasons for choosing Athena over others can be
Data Formats
Amazon Athena service works with several different data formats as discussed above. Athena also supports data types like arrays and objects, but when comparing it with Redshift, it does not give support to such data types. So, here Athena edges out as compare to Redshift.
User Experience
Coming to the user interface, Amazon Athena provides a simple UI.Getting started with Athena is much more comfortable, all need to do is create a database, select the table name and specify the location of the data on Amazon S3. We can easily add columns in bulk and also easily do the partitioning of the table in Athena, whereas Redshift requires to configure all the cluster properties, and also it takes much time for a cluster to get active.
Speed and Performance
As Amazon Athena is serverless, which makes it quicker and easier to execute the queries on Amazon S3 without taking care of the server and the cluster to set up or manage. Another thing is the initialization time, in Athena, we can straight away query the data on Amazon S3, but in Redshift, we have to wait for the cluster to get active and once the cluster is activated, only then we are allowed to query the data.
AWS SageMaker uses Jupyter Notebook and Python with boto to connect with the s3 bucket, or it has its high-level Python API for model building. Click to explore about, Amazon SageMaker
When to Use Amazon Athena and not Other Big Data Services?
When comparing to a data warehouse like Amazon Redshift, it should be best chosen when the data is to be taken from several different sources, like retail sales the system, financial systems or any other sources and we have to store the data for a A more extended period to build any report based on that data. The query the engine in Amazon Redshift has been optimized for performing well especially in the use cases where we need to run several complex queries like joining several large datasets.
So, when we need to run the queries against extensive structured data and need to apply lots of joins across the tables, and then we should go for Amazon Redshift. But services like Amazon Athena makes it easier to run the interactive queries against the extensive data by directly uploading them in Amazon S3 and don’t worry about managing the infrastructure and handling the data. Athena is best suited when we need to run the queries against some weblogs for troubleshooting the issues in the site. In this type of service, we need to define the tables for our data and start querying with standard SQL. Although we can use both the services(i.e., Amazon RedShift and Amazon Athena) Together. This can only be done by keeping the data on Amazon S3 before loading it to Redshift.
The process of managing and prevising computer data centers through machine-readable definition. Click to explore about, Infrastructure as Code on AWS
Athena and QuickSight Combo for Cloud
Here is the solution for the self-service BI application which can build interactive visualizations on the top of several sources that are hosted on Amazon Cloud Infrastructure. For this there would be an external data source, it can be any website or any application from where the data can be imported. After taking the data, it should be stored in Amazon S3, to be used by Amazon Athena. Following are the steps to be used for using Athena and Amazon QuickSight to give the best solution for any BI - Uploading the data to Amazon S3 - For uploading the data to Amazon S3, follow the below-mentioned steps-
- Upload the file to S3, and then select the S3 services from the menu.
- Select an existing S3 bucket or create a new S3 bucket.
- After creating an S3 bucket, create the folders and upload the data in it
- Create tables in Athena: Once the data is uploaded on Amazon S3 when it comes onto the Athena for querying it.
- Open the Amazon Web Services management console for Amazon Athena on the browser.
- With the help of Query editor, run the create database database_name.
- After that, a new database list will be available on the screen.
- After that create a new table for the file which is uploaded in S3 with the partition clause, and once the table is created verify it by browsing it in the panel available on the screen.
- Load all the partitions of the table with the help of the MSCK REPAIR TABLE
- Database_name.table_name.
- After this, we can easily query the table and view the data. This will complete the work of Amazon Athena for querying the data and will move to QuickSight for visualizing the data.
- On the home page of Amazon QuickSight, click on the Manage data option.
- After that select the new dataset option available and choose Athena.
- In the field of data source name, enter the name of the database created in Athena.
- Then for validating, click on the validate button, once the validation is done, click on create data source option for completing the data source creation.
- After that for previewing or editing the data select the table and an edit option.
- After the editing is done, click on save and visualize button for analyzing the data the data.

A Comprehensive Strategy
We provide AWS Services for building a Unified Cloud Computing Platform for fast, cost effective analysis of data, generating insights in Real Time.To know more about AWS Services we advice taking the subsequent steps -- Get an Insight about Amazon Redshift with QuickSight
- Understand How DevOps on AWS Works?



