
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Introduction to EtLT
This is the process of extraction, transformation, and loading, an outdated but fundamental process in moving and processing data. The inclusion of such a process would entail extraction from sources, probable transformation, and then loading into the Data Warehouse that is focused on use.
However, when those volumes began to increase and receive real-time processing, some common ETL issues emerged. In modern data, ETL pipes will never be able to handle the volume or velocity pressure that is put on them.
Nowadays, the trend is towards following EtLT-Extract, Light Transform, Load, and Transform. Rather than going on to do all of the transformations from the very first step of the process, it makes it possible for a two-step loading of data where a preliminary light transformation takes place at the very beginning of it, followed by processing complex transformation after loading.
This change in architecture, therefore, leaves more options on how to handle the data in real-time as it streams or even in batches. As a principle, it does pretty well with cloud storage, which is key in scaling. Due to this, EtLT has become quite welcomed and is generally believed to be the new way of doing systems in modern data processing.
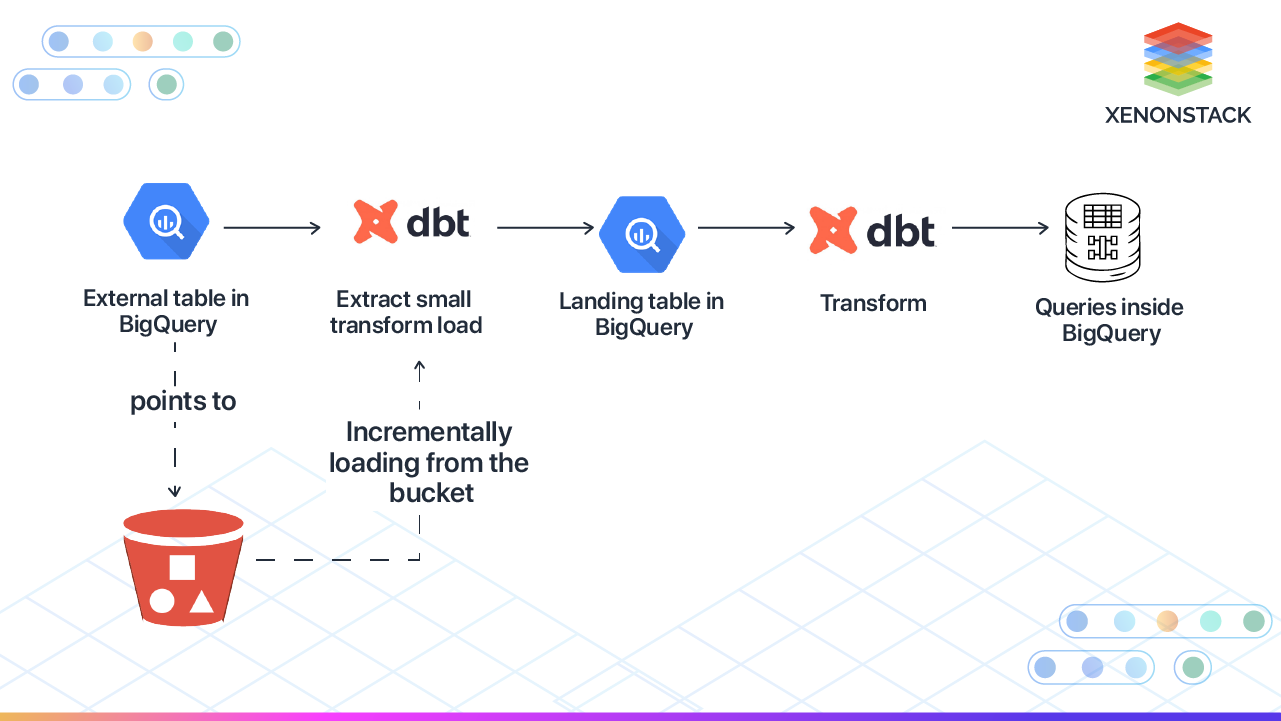
Breaking Down EtLT
Now, let’s examine each stage of the EtLT process and explain how it works and why it is effective. It is time to consider the whole process of the EtLT to understand the working of the model and its efficiency at the same time.
E (Extract)
This is the first step in data gathering from a large number of sources available today. It can run the whole setup, from normal Structured Databases to Structured APIs and more contemporary and fast real-time streaming sources like Apache Kafka. Here, the objective remains just that—one thing and only one: it has not really focused on great data collection without loading until this present time.
t (tweak light transform)
After extraction, this data is only slightly pre-processed. In other words, they could remove a few unnecessary fields, adjust the fields’ order, or modify the structure itself. The fact is that it is only a method to prepare data for other analyses with minimal possible complexity without overcomplicating everything. This also enables the process to be shortened while preserving the data that needs to be processed at a later stage.
L - Load
This means data ingestion to storage architecture. The concept of big data ingestion makes this distinction possible by feeding data into storage infrastructure. It can be the data warehouse, snowflake architecture, AWS S3 cloud storage, or data lake in Delta Lake. Even more so, the user who would like to make queries has the data uploaded into the system which has been prepared in such a manner that data can already be processed with speed at the same time.
T - Transform
Perform any computation-intensive transformations as a final touch after the data is stored in the storage system. Some of such transformations include aggregation, business-specific logic, or joining two or more datasets. Delay intricate transformations up to this stage of the pipeline since they present a very small risk of slowing down the initial processing pipeline.
EtLT: Why It Fits Data Demands Today
Compared to traditional ETL, in today's high-velocity data environment, EtLT offers the following principal advantages:
-
Scalability
It is perhaps the most often cited advantage of EtLT that storage and computation resources increase or scale separately.
ETL, in its traditional sense, uses very heavy transformations, slowing down the data pipeline, especially when dealing with volume. However, EtLT emphasizes that raw data or only slightly processed data are stored up front. This storage ability is scalable and does not experience bottlenecking instances arising from the complexity of the transformation process. Transformations can then be done if and when needed with full consistency in the performance and scalability of your pipeline matched up against the growth of your data.
- Supports Real-Time and Batch Processes
Real-time data processing within traditional ETL is fairly tough, as the nature of the steps used for transformation makes it delayed.
Still, with EtLT, we can take real-time data, such as weblogs, sensor readings, or social media feeds, lightly transform that information, and load it into your system without creating latency.
Meanwhile, batch data (such as nightly sales reports) can be parallelized, which increases overall throughput without impacting real-time workloads. Therefore, EtLT is capable of handling both real-time and batch data processing.
- Cloud-Native
EtLT is in the right direction of cloud-native architectures. Most clouds, AWS, Google, Azure, or their equivalents, offer deep archival storage for deep archiving. It is a manner of stashing huge amounts of 'cold' data in an economic way.
This makes it conceivable that information may be stored inside a cloud setup with the basic attributes of storing data, and further processing can be done within the cloud using appropriate cloud applications. The entire process, thereby, becomes cheaper and more flexible to demand varied data.
- Increased Flexibility
Besides, the two-stage transformation process in EtLT implies that changing and improving your pipeline is easier as your data needs are transformed over time. While all transformation activity is done at the time of ETL, one major bottleneck in the case of ETL design in business process change will be the required change in ETL transformation, which is a highly cumbersome and error-prone task.
Whereas this process of change can be governed and enacted at a later stage with the use of the transforming context of EtLT, no resubmission of the data will be required for those cases, nor is emergence needed.
Practical Exercise: Development of an EtLT Pipeline - Step by Step
With those essential concepts now in place, I want to take you through how we might go about building an EtLT pipeline. For this design, we will use Apache Kafka, Apache Spark, and Delta Lake, all off-the-shelf tools.
Items You Need
-
Apache Kafka: A publish-subscribe messaging application designed for real-time data streaming.
-
Apache Spark: A fast and general computational engine for big data.
-
Delta Lake is a highly scalable storage layer that gives users the ability to perform fast queries as well as real-time ingest.
Step 1: Reading from Kafka
The data source of the EtLT pipeline is a Kafka stream from which real-time data is extracted. In fact, Kafka is extremely optimized for data that is natively event-streams, such as website logs, IoT sensors, and financial transactions. Here is the code snippet that could do it using Apache Spark. Here is the code snippet that could do it using Apache Spark:
# Read from Kafka Stream using Spark
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
Option("subscribe", "topic_name") \
load()
Step 2: Light Transformation
After extracting the data from Kafka, we perform some minimal transformations. Transformations, in this case, represent removing unwanted rows or cases of missing data or changing fields into appropriate data types. This stage is also supposed to make the approach straightforward, as this will lower the pace in the pipeline if it's not.
# Filter data and Cast it
transformed_df = df.select("key", "value").selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
df.loc[df['desired_column'] == 'desired_value']
Step 3: Loading the Data into Delta Lake
After the transformation from the initial form, data will be ready to load into any other solution for storage, such as Delta Lake. Delta Lake supports scalable storage, which provides real-time querying. The next section explains how to load data into the Delta Lake table using Apache Spark:
#Writing Data to Delta Lake
transformed_df.write.format("delta").mode("overwrite").save("/mnt/delta/events/")
Step 4: Apply the Final Transforms
However, once the data is securely stored in the Delta Lake, it creates other higher-level transformations. Imagine that you are to find out how many activities in some time slices were conducted by each user. You could do this aggregation once the data has been loaded. You could do this aggregation once the data has been loaded:
# Make the last modification using SQL
final_df = spark.sql("””
SELECT user_id, COUNT(*) AS action_count
FROM delta.`/mnt/delta/events/`
Group by user_id
"""
This will break down the operations so that our pipeline remains effective, even when there is a lot of data or complex transformations.

Why EtLT Outperforms Traditional ETL
Below is discussed how EtLT is proving to be a better agent for today's modern data pipelines than traditional ETL.
-
Scalability: The EtLT framework is designed to support large volumes of raw data, loading it without heavy transformations; hence, it is scalable.
-
Elasticity: The separation of different transformation steps enables you to reconsider and remodel your data at any time without rebuilding the entire pipeline.
-
Real-time capabilities: since EtLT works well for streaming data, it's great to be applied in such cases as fraud detection, customer behavior tracking, and monitoring of IoT. Using Cloud Platforms and Streaming Tools with EtLT Modern cloud platforms and streaming tools are the best fits for EtLT. By all signs, modern technologies, from Apache Flink to run-time data processing and retention of raw data in a cloud like Google Cloud Storage or AWS S3 with integration possibilities to Data Governance and Security Tools such as Apache Ranger, will enable you to build firm and scalable data pipelines safely in today's modern business world.
Using Cloud Platforms and Streaming Tools with EtLT
This workload corresponds very well with current cloud platforms and streaming tools; therefore, EtLT works well. Apache Flink can be regarded as a technology used for real-time data processing while the raw data can be a part of cloud platforms, namely Google Cloud Storage or AWS S3. For data governance and security purposes Apache Ranger integration could be utilized. These make it possible for you to design and develop more reliable, flexible, and secure data pipelines to cater to today’s dynamic business world.
Conclusion: Why EtLT is the Future of Data Processing
Why EtLT is the Next Generation of Data Processing in settings characterized by an explosive surge of data and real-time requirements, EtLT is on its way to becoming the actual standard for these new types of data pipelines. The real-time and flexible nature really fits into big data or real-time analytics architecture of customer scalability. Should this transform process be cut into stages and pushed through a cloud storage API using modern technologies like Apache Spark or Delta Lake, you get a real opportunity to build an extremely high-performance, scalable solution for business processes. Either way, from streaming data, batch data, or both cases, EtLT is a logical progression in any modern data processing architecture.
- Explore more about Data Processing in IoT
- Read more about the Automated Data Processing




























