
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Ensuring high-quality data is essential for organizations relying on modern cloud-based platforms like Snowflake. Maintaining accurate, complete, and accessible data can be challenging, but Snowflake offers powerful automation capabilities to streamline data quality checks, minimizing manual effort while maintaining data integrity.
The effectiveness of any data-driven initiative depends on the quality of the data it relies on. Inaccurate or incomplete data can lead to flawed analysis, unreliable reports, and poor business decisions. Businesses must implement strong mechanisms to monitor, validate, and maintain data quality.
Snowflakes is a leading cloud-based data platform known for its scalability, speed, and flexibility. However, maintaining data quality becomes increasingly difficult as data volumes and complexity grow. Automating data quality checks is one of the most effective ways to reduce human error, improve efficiency, and ensure consistent data accuracy.
This blog explores how to automate data quality checks in Snowflake workflows. By leveraging Snowflake’s built-in features and automation strategies, organizations can ensure their data remains clean, reliable, and ready for analysis.
What is Data Quality, and Why Does It Matter?
Data quality refers to conditions based on accuracy, completeness, consistency, timeliness, and reliability. High-quality data is essential for making accurate business decisions, optimising operational processes, and enhancing customer experiences. Poor data quality, on the other hand, can lead to wrong conclusions, missed opportunities, and wasted resources.
Here are some key aspects of data quality:
-
Accuracy: Data must correctly represent the real-world entities it describes.
-
Completeness: All required data should be present and without missing values.
-
Consistency: Data must be consistent across different systems and sources.
-
Timeliness: Data should be up-to-date and available when needed.
-
Reliability: Data should be dependable and free of errors.
Ensuring data quality involves ongoing efforts to detect and resolve duplication, missing values, or invalid formats. Automation is crucial in maintaining data quality at scale, especially when working with large volumes of data in Snowflake.
Snowflake Overview and Data Quality Management
Before automating data quality checks, it's essential to understand Snowflake and how it can be leveraged for this purpose. Snowflake is a cloud-based data warehouse platform that offers a scalable, flexible, and high-performance environment for managing and analyzing large datasets.
Snowflake’s architecture is designed to handle both structured and semi-structured data, providing support for data lakes, data marts, and enterprise data warehouses.
Snowflake provides several key features to help ensure data quality:
-
Zero-copy Cloning: Snowflake enables users to create clones of their data without physically copying it. This can be useful for testing and validating data without impacting the production environment.
-
Streams: Snowflake supports change data capture (CDC) through streams, allowing users to track data changes in real-time. This helps monitor data quality during data transformations.
-
Tasks: Snowflake Tasks allow users to automate and schedule SQL queries and procedures. This makes it easy to schedule regular data quality checks as part of your workflows.
-
Time Travel: Snowflake’s Time Travel feature allows users to access historical versions of data, safeguarding against data corruption or errors that may occur during data processing.
-
Automatic Clustering: Snowflake automatically manages data clustering, optimizing performance and reducing the chances of data fragmentation, which can impact data quality.
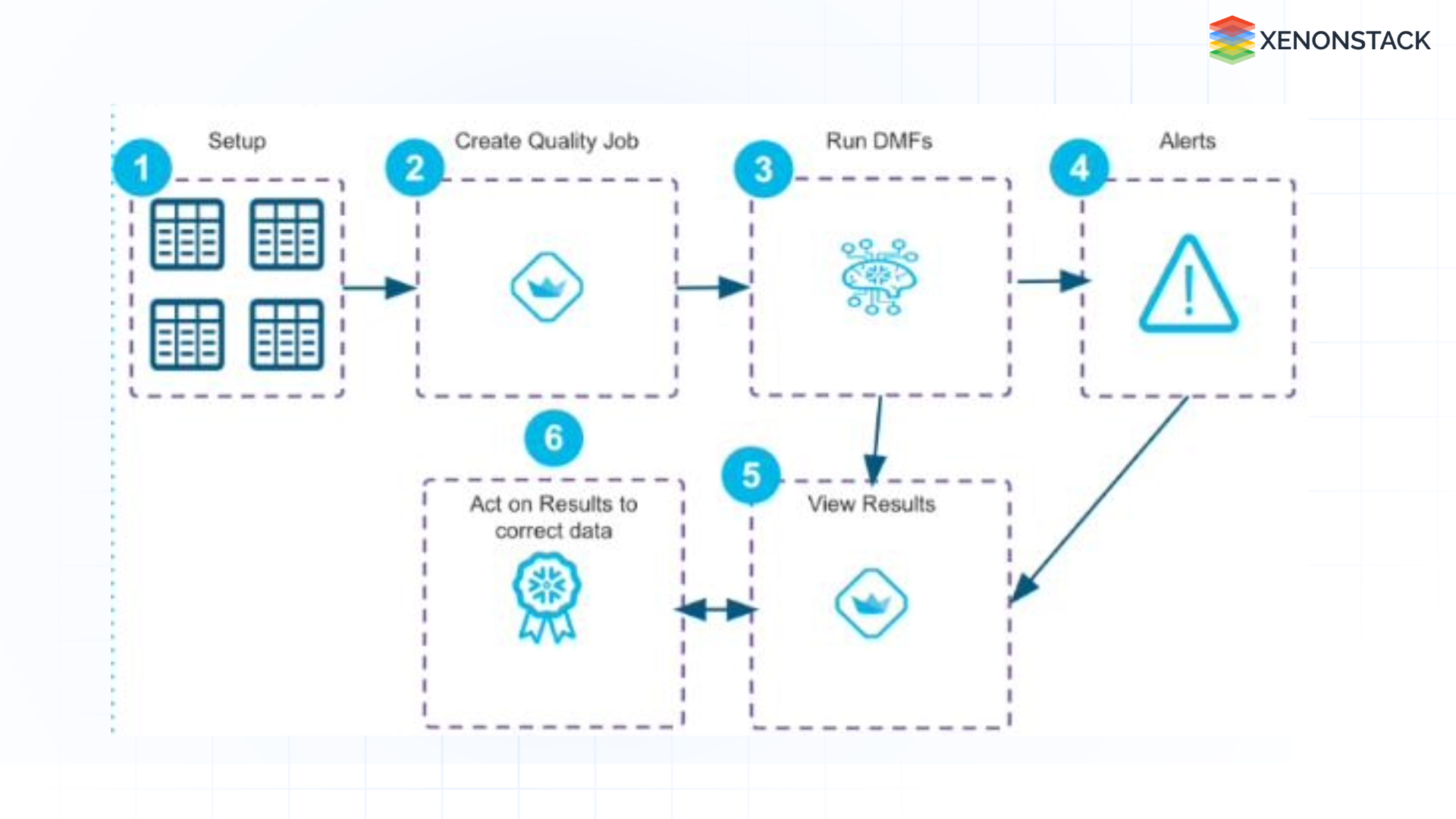 Fig 1: Data Quality Manager App Architecture
Fig 1: Data Quality Manager App Architecture
By combining these features, Snowflake users can implement automated workflows that consistently check and validate data quality as it moves through the data pipeline.
Types of Data Quality Issues
Before automating data quality checks, it’s essential to identify the common data quality issues that can arise in Snowflake. Some problems are inherent to data processing, while others stem from human error or external data sources.
-
Missing Data
One of the most common data quality issues is missing values. Incomplete data can occur due to incorrect data collection methods, errors during data ingestion, or corrupt datasets. -
Duplicate Data
Records can be duplicated when data is loaded multiple times into the system or when the same data source provides redundant information. -
Invalid Data Formats
Data might be stored in formats incompatible with your system or not meeting your expectations. This is common with data coming from external sources or during data transformations. -
Outliers and Inconsistencies
Outliers or inconsistencies in the data, such as values that do not make sense in the context of other records, can indicate data quality issues. These might arise from manual input errors or faulty data processing. -
Data Type Mismatches
If the data is stored with an incorrect data type (e.g., storing a number as text), it can cause issues when performing analysis or transformations. -
Business Logic Violations
Sometimes, data passes basic quality checks but violates business logic rules. For example, a customer’s age may be recorded as unfavourable, or a transaction might exceed available funds in an account.
Identifying and addressing these issues in real-time is key to ensuring high data quality and supporting efficient decision-making.
Automate Data Quality Checks in Snowflake

Data Quality Checks in Snowflake workflows are essential to ensure that the data you are working with is accurate, complete, and consistent. Snowflake provides a powerful data platform that allows you to store and process large datasets, but you must maintain high data quality for meaningful insights.
By automating data quality checks within your workflows, you can minimise human error, ensure reliable data pipelines, and improve the overall quality of your analytics.
This process can be broken down into several steps:
1. Data Validation on Ingestion
-
What it is: This involves validating the incoming data when loaded into Snowflake to ensure it's in the expected format, range, and consistency.
-
How to automate it: You can automate data validation using streams in Snowflake to track changes in data as it’s loaded. Create stored procedures that trigger when data is ingested into a target table to perform data type validation, null checks, and boundary checks (e.g., values in a valid range).
-
Example: If you're loading data for a financial report, check if the amount values fall within expected ranges or if necessary fields like "date" are missing.
2. Null and Missing Value Checks
-
What it is: Ensuring that key fields do not contain null or missing values.
-
How to automate it: You can write SQL queries that check for null values in critical columns and flag any discrepancies. For more advanced checks, you can create a Snowflake Task to periodically run SQL queries that check for nulls in specified fields and send alerts if issues are found.
-
Example: Automate checks to ensure that customer "email" and "phone_number" columns are never null or missing. If any row violates this, trigger a notification.
3. Data Consistency Checks
-
What it is: Ensuring that the data in different tables is consistent and adheres to business rules.
-
How to automate it: You can implement consistency checks by creating Snowflake tasks that run periodically to validate relationships between different datasets. For example, check that every order has a valid customer ID or that sales data is consistent with product information.
-
Example: Create a task to check that each transaction in a sales table has a matching entry in the products table, i.e., every order must have a valid product reference.
4. Duplicate Data Detection
-
What it is: Detecting and handling duplicate records in your data.
-
How to automate it: Use Snowflake Streams and Tasks to check for duplicate entries in the dataset continuously. For instance, create a task to identify rows with the same primary key or other unique identifiers and flag or remove them automatically.
-
Example: Automatically detect duplicate customer records based on unique identifiers like customer email or phone number, and either flag them for review or remove them from the dataset.
5. Data Profiling and Anomaly Detection
-
What it is: Running data profiling checks to understand the dataset's distribution and patterns and detect anomalies or outliers deviating from expected behaviour.
-
How to automate it: Snowflake provides functions like APPROX_COUNT_DISTINCT, MEAN(), STDDEV(), etc., that can be used to profile the data automatically. You can set up tasks that run periodically to check for outliers or unexpected changes in data distributions, which can signal issues.
-
Example: Set up an automated process to detect if the distribution of sales values has drastically changed or if any outliers exist, flagging records that exceed a set threshold.
6. Data Quality Monitoring and Alerting
-
What it is: Continuously monitoring data quality and automatically alerting stakeholders when data issues arise.
-
How to automate it: Use Snowflake tasks combined with third-party tools or Snowflake's Notification Services to automate alerts when quality checks fail. These alerts can be sent to a Slack channel, email, or monitoring dashboard for quick remediation.
-
Example: Create a task that checks for data discrepancies or failed data loads and automatically triggers an email to the data team with the error details.
Best Practices for Data Quality in Snowflake
To effectively automate data quality checks in Snowflake workflows, consider the following best practices:
Tools and Features to Leverage in Snowflake for Data Quality
Snowflake offers several tools and features that can help automate data quality checks:
-
Streams and Tasks: For real-time data monitoring and automation.
-
Zero-copy Cloning: To safely test and validate data without impacting production systems.
-
Data Sharing: To ensure that external partners or teams have access to quality-validated data.
-
Snowflake Snowpipe: For automated data ingestion and processing.
By combining these tools, Snowflake provides a flexible environment for automating and maintaining high data quality throughout your pipeline.
Troubleshooting and Monitoring Data Quality
Automating data quality checks does not guarantee error-free operation. It's essential to monitor these checks regularly and troubleshoot any issues.
-
Log Data Quality Results: Log the results of data quality checks for audit purposes. This can help identify patterns or recurring issues.
-
Create Dashboards: Use visualization tools like Tableau or Looker to create dashboards that monitor the results of data quality checks.
-
Set Up Alerts and Notifications: Set up automated notifications in case of failures or breaches in data quality thresholds.
Automating data quality checks within Snowflake workflows is an essential strategy for maintaining the integrity and reliability of your data pipeline. Organizations can ensure that their data remains accurate, complete, and consistent by leveraging Snowflake’s powerful features, such as Streams, Tasks, and Time Travel, well-defined data quality rules, and automated corrective actions.
Embracing automation improves operational efficiency and reduces the risk of human error, allowing data engineers and analysts to focus on higher-value tasks. By following best practices and leveraging Snowflake’s full suite of tools, businesses can confidently trust their data for mission-critical decision-making.




























