
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
What is Chaos Engineering?
Chaos engineering is an approach to today’s software systems that seeks to strengthen the internal integrity of the system by subjecting it to experiments in live conditions. This technique promotes the discovery of points of weakness and endorses the fortification of systems, particularly in the context of the health of cloud-native systems.
The major objective in practising chaos engineering is to testify for the system's risks, all the others being controlled, before launching the system into a production environment where the end users are active. By experimenting with more and more failure scenarios, which would otherwise be avoided at all costs, teams work on the stability, reliability, and robustness of their applications.
The Necessity of Chaos Engineering
With advances in technology, particularly computer and business-enhancing related program development, software applications become and quite logically is true for the distributed systems that are usually sliced and diced unto a virtualized environment in the email, so it becomes even more important to guarantee that such applications can withstand and all sorts of failures.
For this reason, there are a few reasons which argue chaos engineering is a must:
Resilience Improvement:
No one is perfect in every organization, be it a cyber privacy health care system. Therefore, in cases where downtimes need to be prevented by enhancing performance, chaos experiments will be conducted in a timely manner as organizations will be able to look for and fix system defects.
Enhanced Handling of Incidents:
Knowledge of an application's behaviour during failure creates much less ambiguity and speeds up recovery.
Reduction of anxiety levels on releases:
Knowing that the system will not be broken whenever changes are made to prevent any future downtimes, the assumption is that teams will be less worried about pushing the live editions of the projects when they are ready for this phase.
Reliability in culture: Effective adoption of chaos engineering builds trust in teams, prompting them to seek better solutions to their systems.

Overview of KrKn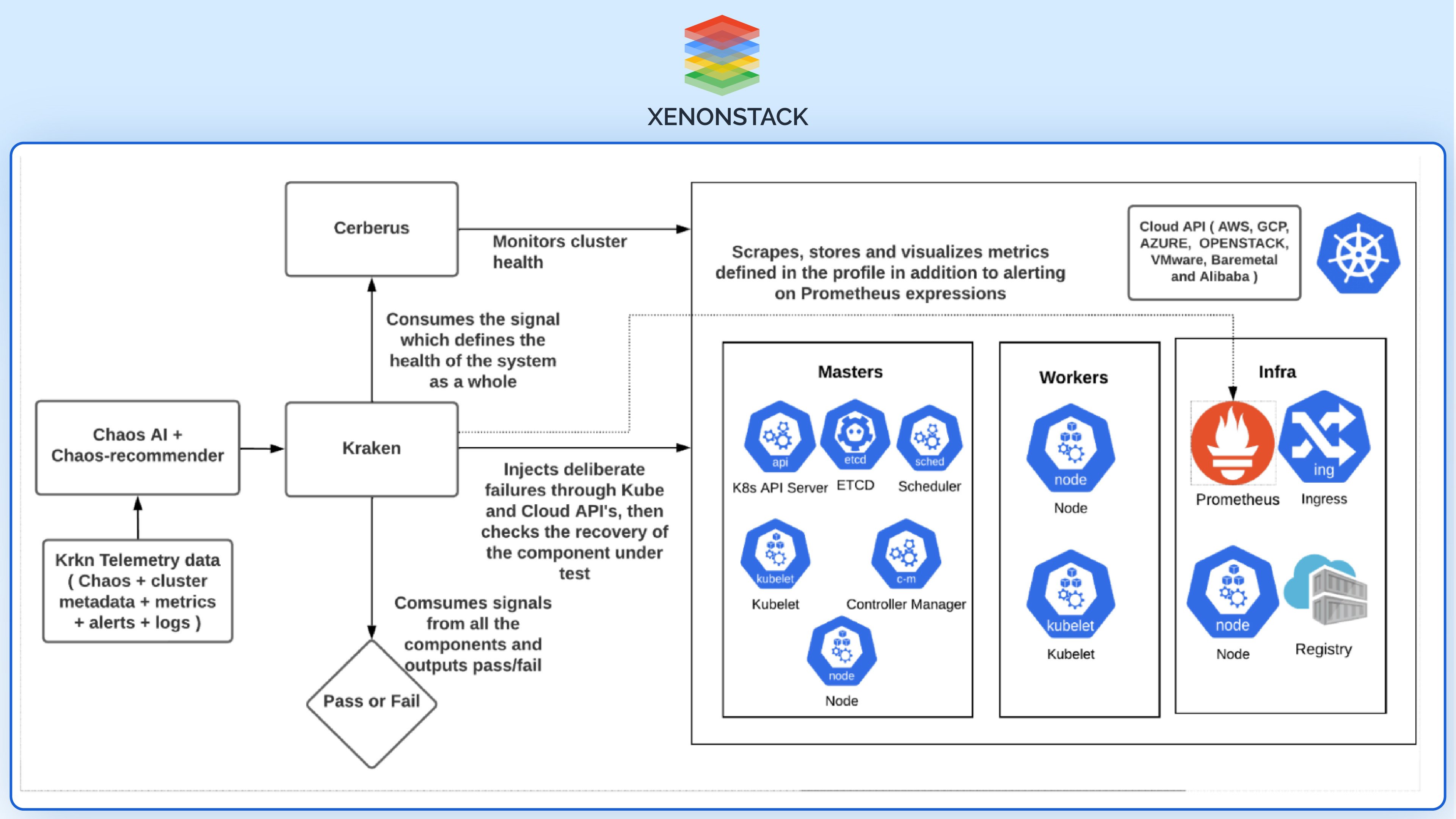
KrKn is an open-source tool devoted to chaos engineering in a particular Kubernetes environment. The failure of traditional static architecture in the face of advancing microservices and the increased use of Kubernetes as the mainstream container manager have indicated the introduction of such a tool.
KrKn helps the teams imagine many failure situations, and as such, the products are well stress tested.
Key Features of KrKn
-
Kubernetes Native: Since KrKn is a Kubernetes operational tool, it can be deployed in managed Kubernetes environments such as Amazon EKS, Google GKE, and Azure AKS.
-
Customizable Chaos Experiments: Users can self-define chaos scenarios using YAML to achieve effectiveness for specific applications.
-
Observability and Monitoring: KrKn also enables insights into how a system or application performs during the chaos such that some metrics, logs and traces can be captured.
-
Automation and Rollbacks: KrKn is capable of performing the chaos experiment in an automated manner and undoing the procedural changes that were activated as a result of the testing to restore normalcy.
-
Rich Documentation and Community Support: Another advantage of KrKn is that, as a free source code developer, users readily assist it, and the vast amount of available documentation allows them to begin their work soon.
Getting Started with KrKn
To implement KrKn in your Kubernetes environment, follow these steps:
Step 1: Prerequisites
- Kubernetes Cluster: Ensure you have a running Kubernetes cluster. This can be a managed service like EKS, GKE, or AKS or a self-hosted cluster.
- kubectl: Install kubectl, the command-line tool for interacting with your Kubernetes cluster.
- Helm: Install Helm, the package manager for Kubernetes, to simplify the installation of KrKn.
Step 2: Installing KrKn
- Add the KrKn Helm repository:
- helm repo add krkn https://charts.krkn.dev
- helm repo update
- Install KrKn:
- Verify Installation:
Step 3: Defining Chaos Experiments
KrKn allows users to create chaos experiments through YAML files. Here’s an example of a basic chaos experiment that simulates a pod failure:apiVersion: krkn.io/v1
kind: ChaosExperiment
metadata:
name: pod-failure-experiment
spec:
selector:
matchLabels:
app: my-application
action: terminate
duration: 30s
interval: 10s
This experiment focuses on the pod's app, my-application. Terminating a pod takes 30 seconds, followed by a few steps, a 10-second pause, and some more steps.
Step 4: Conducting Chaos Experiments
The pod-failure-experiment YAML file contains the information needed to perform the chaos experiment. The kubectl command applies the pod-failure-experiment YAML configuration.
kubectl applies -f pod-failure-experiment. yaml
With the possibility of carrying out that experiment, you can see the effect that experiment has on the application and services.
Step 5: Monitoring and Analyzing Results
About the above, once the chaos experiment concludes, all the consequences of crowding out must be interpreted. With the assistance of Prometheus and Grafana, one can follow the metrics provided to the teams through KrKn's internal statistics. Such metrics include
-
Time taken to respond
-
Rate of errors
-
Logs of the systems
-
Parameters determining work of information system
Some Useful Tips When Working with KrKn in the Practice of Chaos Engineering
-
Start Small: Start with probably harmless experiments with a low failure simulation. When you feel more secure in your systems, raise the bar slowly and perform more complicated tests.
-
Automate Experiments: Integrate chaos experiments into the regular CI/CD pipeline. By instituting chaos testing as a standard approach early on in development, you may solve problems centred around roadblocks identified late in the development cycle.
-
Document Findings: Maintain logs of every experiment done. Document the setups, outcomes, and system changes. With this documentation, you can lessen the burden of follow-up experiments and even improve the system.
-
Involve the Team: Engage in chaos engineering as a team in practice as much as it is possible.
-
Learn from Failures: Chaos engineering is more about learning to add value to systems.

Common Chaos Scenarios to Test with KrKn
These are some situations of chaos that common teams can play around with using KrKn:--
Pod Failures – In this case, not all the pods will be active, and some will be surgically…
-
Network Policy: Introduce artificial delays in the network traffic to test the application's reaction to delayed responses.
-
Resource Exhaustion—CPU or memory resources will be granted to specific pods, and the application's performance under this limitation will be evaluated.
-
Node Failures – Here, the failure of an entire node will be simulated to gauge.
-
Service Interruptibility- Turn off one dependent service for a while to check the application when one important service is missing.
Benefits of using Karkin for Chaos Engineering
-
Kubernetes Specific: As a Kubernetes-centric tool, KrKn is developed for the seamless adoption of container technologies, making it suitable for countries with Kubernetes as the fundamental infrastructure.
-
Open Source: This open-source orientation has great benefits since KrKn is open-sourced to developers in the wider society, leading to the improvement of the model itself.
-
Economic: Such abuse of the controlled environment is tested by the organizations so that costly downtimes are avoided in the controlled “production” environments.
-
Elastic: With KrKn’s help, chaos engineering experiments can be run in pre-production and production environments, allowing them to grow with your applications.
-
Platforms Interoperability: KrKn can be trained to enhance the platforms’ interoperability, seamlessly integrated into the organization's existing CC practices, enhancing reliability constructs.
Challenges and Considerations
Here’s a concise list of considerations for applying chaos engineering methodologies, such as KrKn:
-
Preparedness for Failure: Ensure teams are well-prepared for potential failures when introducing faults.
-
Supportive Culture: Foster a culture that encourages trial-and-error learning to support experimentation.
-
User Impact: Prioritize minimizing negative effects on end users during chaos tests in production environments.
-
Understanding Microservices: Recognize the complexity of microservices architecture and how various services interact.
-
Monitoring and Control: Continuously monitor chaos experiments to prevent them from spiralling out of control.
-
Timing of Experiments: Conduct chaos experiments during off-peak hours to reduce disruption during high-traffic times.
-
Legal Considerations: Be aware of legal boundaries and obligations to avoid potential legal issues arising from chaos experiments.
8. Identifying Barriers: Focus on identifying factors that hinder fault detection in challenging environments.
Final Thoughts on Using KrKn for Chaos Engineering
KrKn helps his clients optimally apply chaos engineering to their Kubernetes deployments. While chaos testing has limitations, certain threats are also investigated to increase the system's confidence and improve its ability to respond to incidents.
On the other hand, such operating models would still face the issue of the complex and distributed nature of systems if the companies have grown in terms of operational and business activities. That is the reason why a good number of organizations are more than pleased by the adoption of chaos engineering principles. There is no doubt that organizations seeking KrKn, in addition to chaos engineering techniques, can and will prepare their applications against ageing problems and, in particular, distortions. Also, it is worth noting that chaos engineering can be deployed at any stage of development workflow through the hierarchical level of the team structure to create reliable, even safer, and stress-free applications.
- Explore more about Google Cloud Managed Services
- Know more about Kubernetes Managed Services for Hybrid Cloud




























