
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
The modern world generates vast amounts of data in different formats—text, images, audio, and video. Traditional embedding models often focus on a single data type, such as text-based models for natural language processing (NLP) or image-based models for computer vision. However, real-world applications frequently require understanding multiple data types simultaneously.
Multimodal embeddings bridge this gap by converting different data types into a unified vector space, allowing machine learning models to understand relationships across diverse modalities. This technique enhances various AI applications, from content recommendations and semantic search to autonomous systems and multimodal chatbots.
Amazon SageMaker provides a robust and scalable environment for developing multimodal embeddings. In this blog, we will explore multimodal embeddings, their importance, and a step-by-step process to build, store, and use them effectively with SageMaker.
What Are Embeddings?
Embeddings are numerical vector representations of data that preserve semantic meaning in a lower-dimensional space. Instead of treating words, images, or other data types as raw input, embeddings transform them into dense vectors where similar items have closer representations.
Embeddings make it easier for machine learning models to process and compare complex data. They improve:
-
Semantic Understanding: Words with similar meanings (e.g., "king" and "queen") have closer embeddings.
-
Dimensionality Reduction: Converts high-dimensional data (e.g., one-hot encoded words) into compact, meaningful representations.
-
Efficient Search & Retrieval: Enables fast similarity searches in large datasets.
Common use cases for embeddings include
-
Natural Language Processing (NLP): Used in word embeddings like Word2Vec, GloVe, and BERT.
-
Image Processing: Image embeddings help identify similarities in pictures.
-
Recommendation Systems: Online platforms use embeddings to recommend products, movies, or music.
-
Search Engines: Google, Bing, and enterprise search engines use embeddings for more relevant search results.
Introduction to Multimodal Embeddings
Multimodal embeddings extend the concept of embeddings by integrating multiple data types—text, images, audio, and video—into a common vector space. Instead of treating these modalities separately, multimodal embeddings establish relationships between different data types to enhance understanding.
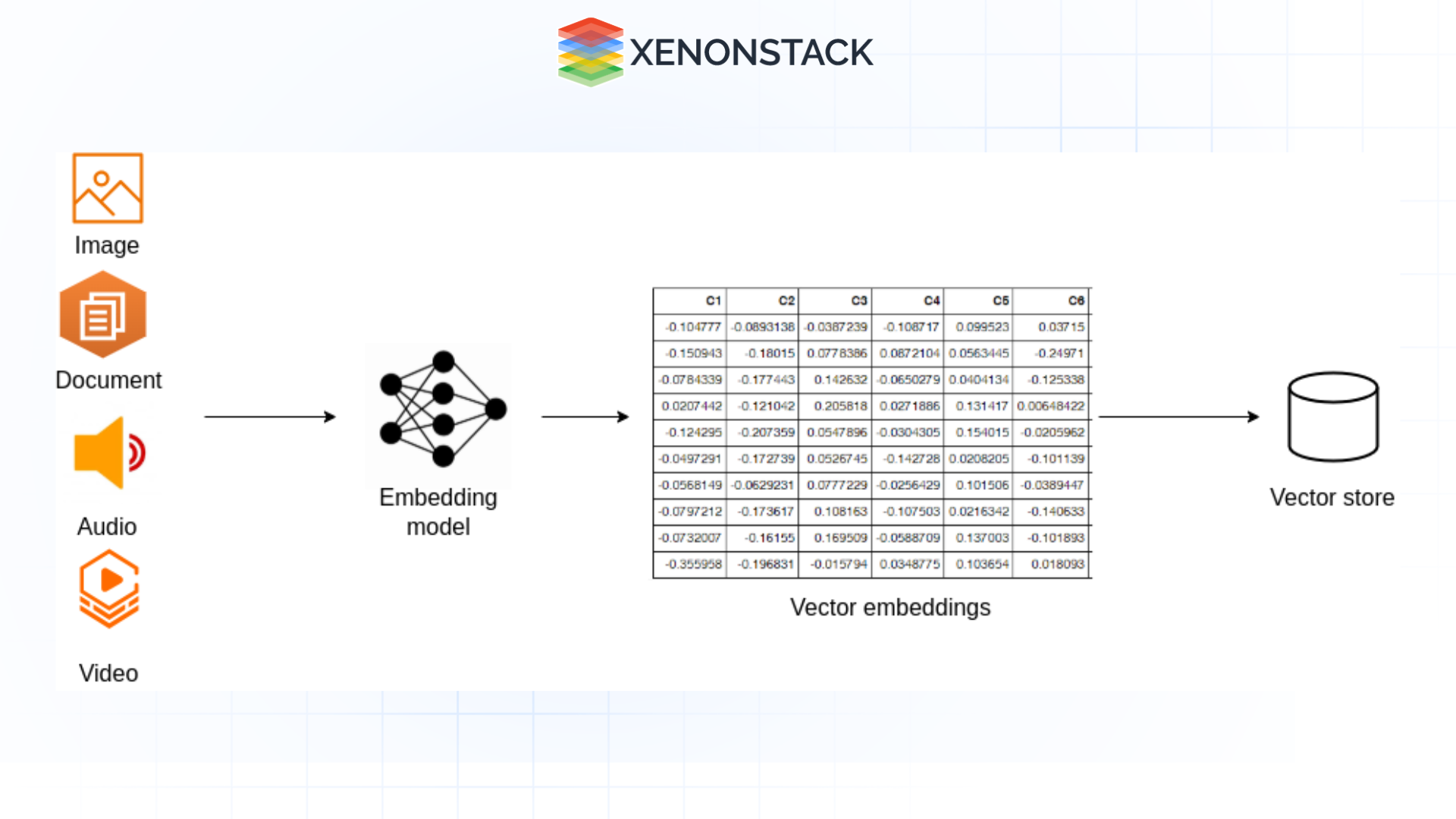
For example, a multimodal embedding model can learn that an image of a “golden retriever” and the text “friendly dog” are related, even though they originate from different data sources.
Benefits associated with the usage of multi-modal embeddings include:
-
Improved Contextual Understanding: Allows AI models to interpret relationships across text, images, and other modalities.
-
Better Search and Retrieval: Enhances semantic search by allowing users to retrieve content using multiple input formats (e.g., searching for images using text queries).
-
Personalized Recommendations: Helps systems understand user behaviour across different content types (e.g., video and text preferences).
-
Enhanced AI Interactions: Power AI agents and chatbots to process and respond to multimodal inputs more effectively.
-
Understanding both text and images for better filtering of inappropriate content
Developing Multimodal Embeddings with Amazon SageMaker
AWS SageMaker is a fully managed service by Amazon Web Services (AWS) designed to help developers and data scientists build, train, and deploy machine learning (ML) models quickly and easily. It offers a range of tools and features to simplify and accelerate the process of creating machine-learning solutions without managing the underlying infrastructure.
Amazon SageMaker provides a scalable and efficient way to develop multimodal embeddings. It streamlines the process by offering pre-trained models, distributed training capabilities, and easy deployment options.

Key features of SageMaker for Multimodal Embeddings include:
-
Pre-Trained Models: SageMaker JumpStart provides access to pre-trained multimodal models like the Cohere Embed Multimodal Model.
-
Custom Model Training: Users can fine-tune models using PyTorch, TensorFlow, or Hugging Face Transformers.
-
Object2Vec Algorithm: A neural embedding algorithm that generates meaningful vector representations from different input types.
-
AWS Service Integrations: Seamlessly works with Amazon S3 for data storage, DynamoDB for structured storage, and Qdrant for vector search.
-
Scalability: Supports distributed training on powerful GPU instances for handling large datasets efficiently.
Implementing Multimodal Embeddings with SageMaker
Creating multimodal embeddings—representations that integrate data from various modalities like text and images—can significantly enhance applications such as semantic search and recommendation systems. Amazon SageMaker provides a robust platform for developing and deploying these embeddings efficiently.
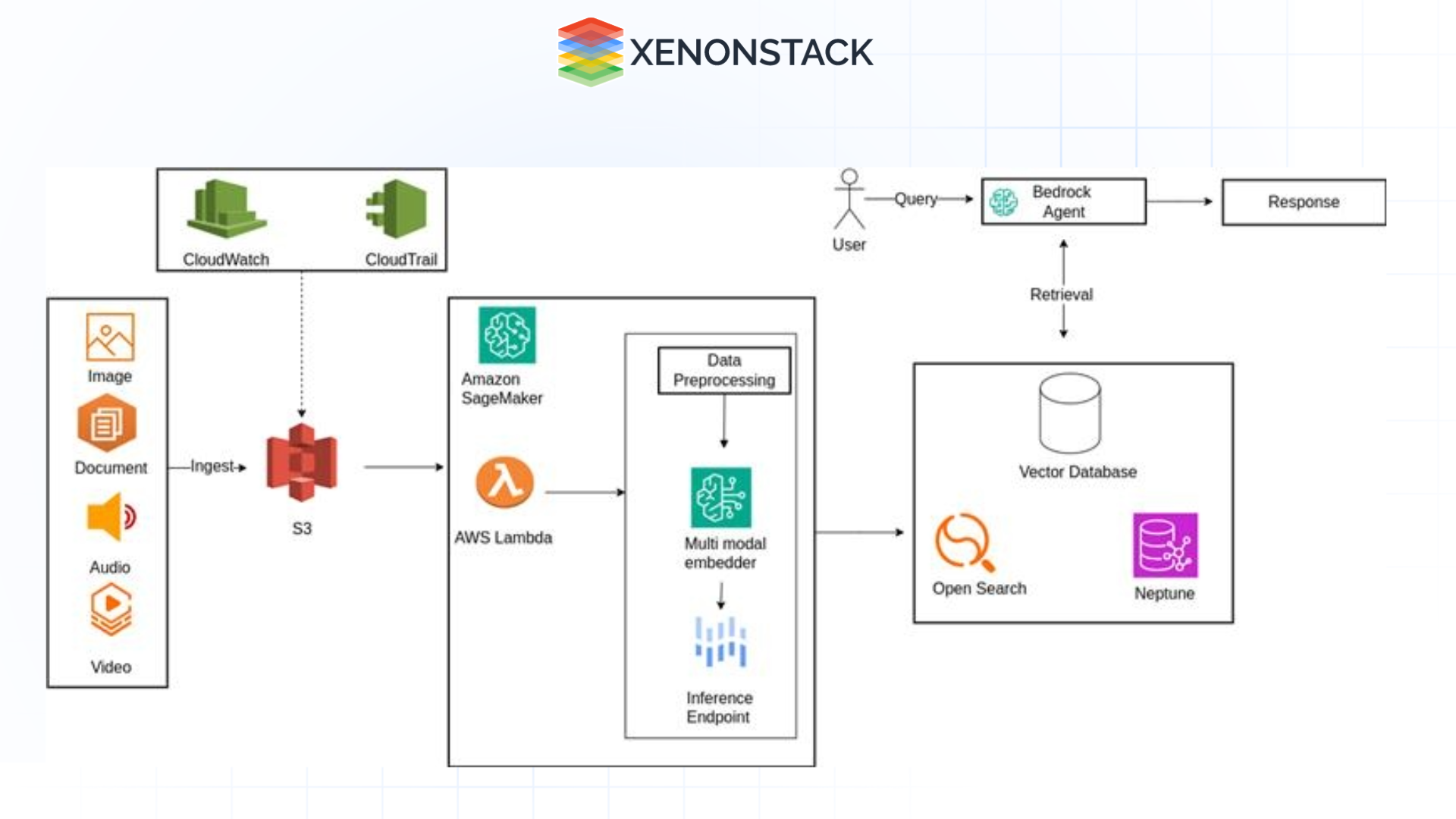 Figure 2: Pipeline for multimodal embeddings
Figure 2: Pipeline for multimodal embeddings Set Up Your AWS Environment
-
Ensure you have an active AWS account with the necessary permissions to access SageMaker and related services.
-
Install the AWS Command Line Interface (CLI) and configure it with your credentials.
Choose a Multimodal Embedding Model
-
Amazon SageMaker offers pre-trained multimodal models like Cohere's Embed 3 and Amazon's Titan Multimodal Embeddings.
-
Cohere's Embed 3 can generate embeddings from text and images, facilitating seamless integration of diverse data types.
Deploy the Model on SageMaker
-
Subscribe to the desired model through the AWS Marketplace.
-
Deploy the model using SageMaker JumpStart or the SageMaker console.
-
Configure the endpoint to handle inference requests.
Prepare Your Data
-
Collect and preprocess your text and image data, ensuring it's in a format compatible with the model.
-
For images, consider encoding them in base64 format for processing.
Generate Embeddings
-
Use the deployed model endpoint to generate embeddings for your data.
-
Send the text input to the model and receive the corresponding embedding vector for text data.
-
For images, send the base64-encoded image to the model to obtain the embedding.
-
The model can generate a unified embedding for combined text and image inputs that captures information from both modalities.
Utilize the Embeddings
-
Store the generated embeddings in a vector database like Amazon OpenSearch Serverless for efficient retrieval.
-
Use these embeddings to enhance applications such as semantic search, recommendation systems, or any other application that benefits from understanding the semantic relationships between text and images.
By following these steps, you can effectively create and deploy multimodal embeddings using Amazon SageMaker, enhancing your application's ability to process and understand diverse data types.
Benefits of Using Amazon SageMaker for Multimodal Embeddings
Amazon SageMaker offers a scalable, secure, and fully managed environment for generating multimodal embeddings, making it an ideal choice for AI-driven applications. Here are some key benefits:
-
Scalability & Performance: SageMaker provides on-demand compute resources, allowing you to scale model inference dynamically based on workload demands. It supports GPUs and specialized instances to efficiently process large datasets, including high-resolution images and long text sequences.
-
Pre-Trained Models & Customization: SageMaker JumpStart offers pre-trained multimodal embedding models like Cohere Embed 3 and Amazon Titan, reducing development time. It also allows for fine-tuning models using proprietary datasets to improve accuracy and relevance for specific applications.
-
Seamless Integration with AWS Services: Easily store and retrieve embeddings using Amazon OpenSearch, DynamoDB, or S3.For enhanced functionality, combine SageMaker embeddings with AWS AI services such as Amazon Rekognition (image analysis) and Amazon Comprehend (text processing).
-
Cost Efficiency: Pay-as-you-go pricing ensures that businesses only pay for the resources they use, eliminating the need for costly infrastructure investments.SageMaker’s managed services help reduce operational overhead and maintenance costs.
-
Security & Compliance: SageMaker provides built-in security features like encryption, IAM-based access controls, and VPC integration to safeguard sensitive data. It meets industry compliance standards such as HIPAA and GDPR, making it suitable for highly regulated industries.

Practical Use Cases of Multimodal embeddings
Multimodal embeddings can drive innovation across various industries by enabling AI systems to understand and integrate diverse data formats.
E-Commerce & Retail
-
Visual Search & Recommendations: Customers can search for products using images instead of text queries. Multimodal embeddings improve recommendation systems by combining text descriptions with product images.
-
Fraud Detection: Identifies inconsistencies in user-generated content (reviews, images, receipts) by analyzing textual and visual patterns together.
Healthcare & Medical Research
-
Medical Image Analysis: Embeddings help correlate patient symptoms (text-based clinical notes) with X-rays, MRIs, or CT scans to improve disease diagnosis.
-
Drug Discovery: AI models analyze scientific literature (text) alongside molecular structures (images) to identify potential drug candidates.
Finance & Insurance
-
Automated Claims Processing: Multimodal AI can process insurance claims by extracting data from textual reports and supporting images (e.g., accident photos).
-
Fraud Prevention: Identifies fraudulent activities by cross-referencing invoice texts, customer statements, and transaction images.
Autonomous Vehicles & Smart Cities
-
Traffic Monitoring & Incident Detection: AI models process live video footage (images) along with textual traffic reports to predict congestion and accidents.
-
Smart Parking Systems: Combines license plate recognition (image data) with parking rules (text data) to optimize parking availability.
Final Thoughts on Multimodal Embeddings
Multimodal embeddings are transforming AI applications by enabling machines to understand and relate multiple data types in a unified way. Amazon SageMaker provides a powerful and scalable environment to develop these embeddings with pre-trained models, distributed training, and seamless AWS integration.
By utilising SageMaker’s multimodal embedding capabilities, organizations can improve search engines, recommendation systems, autonomous agents, and medical diagnostics, unlocking new frontiers in AI-driven applications.




























