
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Artificial intelligence (AI) has become a buzzword thanks to mobile phone and car software advancements. Nevertheless, as more devices get smarter with AI, the privacy problem worsens. These issues are resolved through privacy-preserving AI at the edge because data is not sent to the cloud for processing in an AI system, thereby exposing the individual’s details. This approach is particularly beneficial in the application, which involves a decision that needs to be made in real-time, for example, in healthcare, autonomous vehicles and smart home devices. As privacy regulations trend toward being stricter in many parts of the world, edge AI with privacy-preserving elements is expected to be a key solution in the following generation of technology.
 Fig 1: Overview of the encrypted inference process
Fig 1: Overview of the encrypted inference process
Privacy-Preserving AI History
Privacy-preserving AI has its roots deep in machine learning history, where basic algorithms learn to depend on big, centralized data for both training and testing. However, the high volume of sensitive data and the growing potential for negative consequences stimulated the search for approaches to minimise privacy threats. Solutions such as Federated Learning HL, Homomorphic Encryption HE, and Differential Privacy DP appeared to respond to the privacy threat. However, each solves the problem differently. The shift towards edge computing in the late 2010s elevated the demand for private AI methodologies since companies and customers valued local computation.
Techniques in Privacy-Preserving AI at the Edge
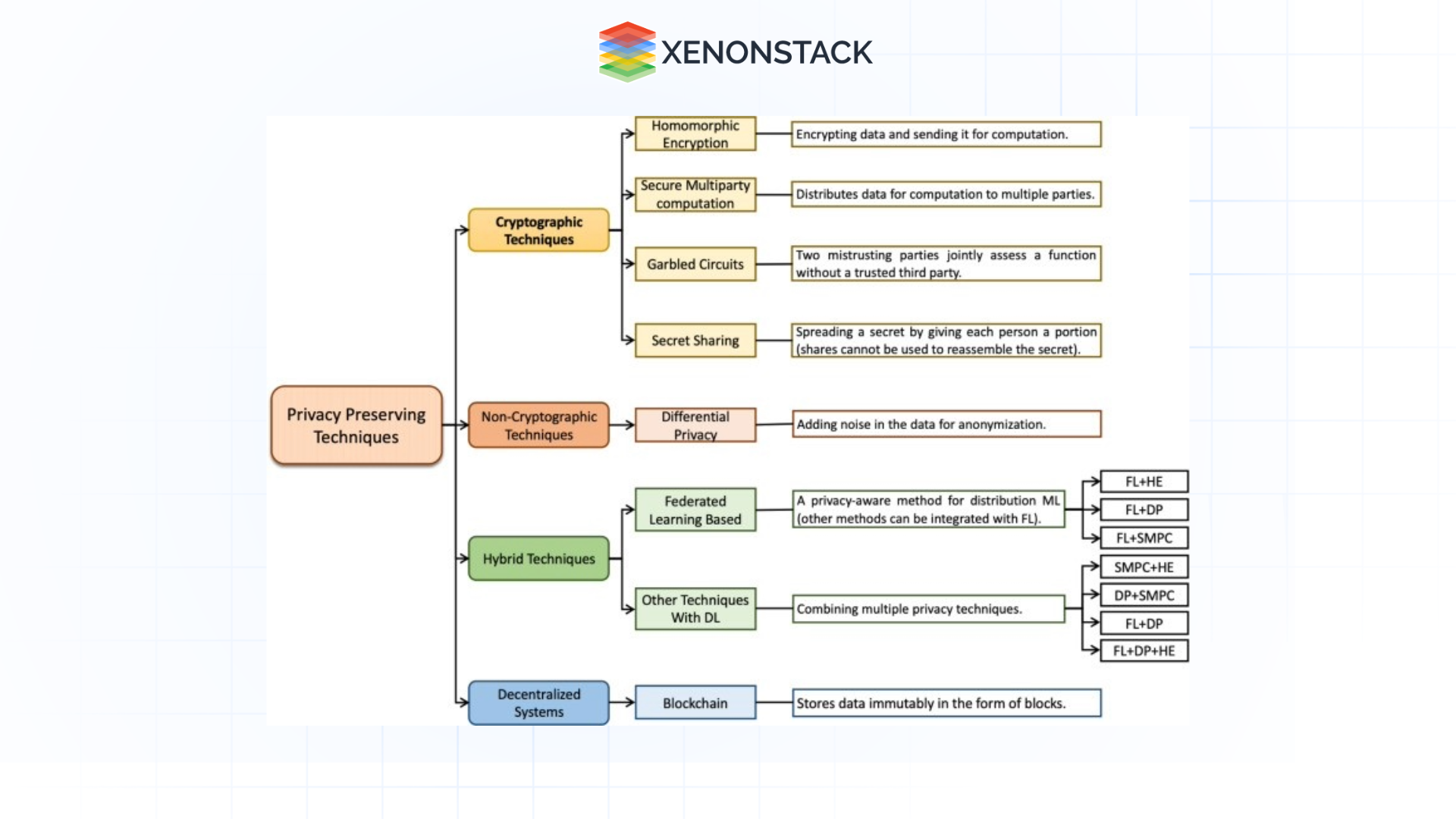 Figure 2: Taxonomy of privacy-preserving techniques
Figure 2: Taxonomy of privacy-preserving techniques
Some methods help achieve privacy preservation of AI at the edge level. Below are some of the key approaches:
-
Federated Learning
FL is a distributed machine learning process that involves averaging the parameters of the shared global model across many devices (clients) without exchanging the raw data with a central hub. Every device builds a model on the local data. It transmits only the updates on model parameters to a principal server, forming a more accurate global model. The general formula for FL is:
Where wt is the model weights available in the global model at the current iteration t, and wt(i) are the local model weights of the device t.
-
Homomorphic Encryption
Homomorphic Encryption (HE) means computation is possible on ciphertext data so that information can be processed without decrypting. It is useful when data is considered sensitive, although computationally expensive. The function can be represented as:
Where E represents encryption and f(x) is an arbitrary function that may be required to be computed.
-
Differential Privacy
Despite being based on endeavours to derive utility from local data, DP adds noise to data or model outputs to hide the inputs of data points, offering plausible deniability to users. The purely probabilistic privacy guarantee is quantified using parameters ∈ (privacy budget) and δ, where lower numerical values indicate higher privacy.
Where M is a mechanism used on two data sets, D and D's, which are dissimilar by one data point.
-
Secure Multiple Party Computation or SMC
SMPC splits a data computation task to multiple agents, yet no agent can view the entire dataset. The computation is performed across all parties involved in such a manner that the privacy of the information is protected even under an adversary environment.
Modern Advances in Privacy-Preserving AI
Advanced attempts in privacy-preserving AI have been made in recent years for the operation at the edge. Key developments include:
-
Edge Hardware Improvements: Mobile endpoints are stronger now, and devices such as NVIDIA’s Jetson and Google’s Edge TPU enable computation to be performed locally and the usage of high-level AI models on small devices.
-
Federated Learning Frameworks: Like TensorFlow Federated, by Google and OpenMined’s PySyft, help developers build federated learning models more easily, thus expanding privacy-preserving results across devices.
-
Private Machine Learning Frameworks: Many corporations, like Apple and Google, have already started using differential privacy in their AI models. That has become a precedent, proving that most large tech firms understand privacy as an important aspect of new AI technologies.
-
Federated Analytics: Emerging relatively recently, federated analytics offers a method to gather the analytics of the decentralised data without the data itself, giving an added anonymity by not accumulating large amounts of data.
Importance of Privacy-Preserving AI
As AI infiltrates more areas of our lives, privacy concerns intensify, and for good reasons:

Regulatory Compliance
In Europe, the General Data Protection Regulation Act and, in California, the California Consumer Privacy Act require organizations to adequately protect people’s data.
Consumer Trust
If consumers trust that they are not putting their data into an AI system that will be misused, then users will accept the use of AI in various sectors. Measures to protect privacy make users confident and encourage more people to use AI.
Advantages of Privacy-Preserving AI at the Edge
-
Enhanced Privacy: Using the device as a data processing platform prevents data leakage.
-
Reduced Latency: To accomplish this, the computation is done locally to reduce the time that would have been taken to send information to cloud servers.
-
Lower Bandwidth Requirements: Since data is kept local, the device uses less data, hence the need for less bandwidth.
-
Increased Scalability: Privacy-preserving techniques decentralise computation, which is the best way to distribute computation across many devices, say millions of devices.
Why Is Privacy-Preserving AI at the Edge Complex?

Despite its benefits, implementing privacy-preserving AI at the edge comes with challenges:
-
Resource Constraints: Clients are typically less equipped than a server centre. Therefore, exotic devices have more limited computing and storage power.
-
Complexity of Encryption Methods: Subsequently, both homomorphic encryption and SMPC may be less feasible for implementation within low-energy devices.
-
Communication Overheads: Techniques such as Federated Learning involve passing information between devices and servers, and this puts pressure on the network.
-
Balancing Privacy and Performance: They need to manipulate the data slightly with methods like differential privacy, and here we see that if it is not controlled, it adds noise and, therefore, reduces the model's fidelity.
Reducing Privacy-Preserving AI Obstacles 
-
Efficient Model Design: While lightweight models improve computational and power requirements for edge devices, they can be more deployable.
-
Optimized Communication Protocols: Some federated learning techniques can be set up to avoid communication rounds and data sharing among the devices.
-
Hardware Accelerators: Mainstream hardware like Google’s Edge TPU or Apple’s Neural Engine can boost the performance of privacy-preserving computations, making them possible on the edge.
-
Dynamic Privacy Budget: Other differential privacy models can embrace a privacy budget that can be adjusted or varied based on aspects such as noise and performance, leading to better accuracy without additional loss of privacy.
Applications of Privacy Preserving AI at the Edge
Privacy-preserving AI at the edge has broad applications across industries:
-
Healthcare: These devices access and gather private data about a patient’s health, but because most of the analyses are done locally on the wearable device, the amount of data transmitted is reduced.
-
Autonomous Vehicles: Self-driving car systems receive and analyse large quantities of data within a closely observed period. Edge AI guarantees this data is not exposed, thus minimising data leaks during its transfer.
-
Smart Cities: Information that passes through surveillance and monitoring systems in smart cities is usually considered sensitive data. This way, information handling occurs on-site, and people’s identities are not revealed to any third party.
-
Finance: It is used in financial applications because it can train models across decentralised financial datasets without exposing customer information.
This advancement of privacy-preserving AI at the edge targets two areas that will keep developing – data privacy and powerful AI services. Some solutions include Federated Learning, Differential Privacy, and Homomorphic Encryption, which can ensure that data stays on edge devices while AI gains improvement. Since the hardware used in edge computing is progressing, these approaches will become more practical as more innovative and privacy-related AI requests arise.




























