
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Introduction to Computer Vision
The direction of self-supervised learning (SSL) can be considered one of the most promising in the rather unstable field of computer vision. As a result, a number of SSL methods, which are able to employ a vast amount of unlabelled data, can become an adequate counterpart to the traditional supervised learning methods that need a large number of labeled data. This blog describes the current methods for self-supervised learning and contraceptive learning and pre-training techniques with their examples for image classification and object detection problems.
The branch of artificial intelligence that has to do with analysis of information accrued through video cameras referred to as computer vision has seen significant improvements. In the past, such innovations have mainly been driven by supervised learning or training models on some labeled databases.
Also, this approach may face limitations such as the need to get large amounts of labeled data which can be expensive and time consuming in equal measure. Hence, there is self-supervised learning that makes use of unlabeled data to develop exceptional models using little learning content. In this blog post, I am explaining the concept of self-supervised learning as a game-changer in computer vision further, focusing on the contrastive learning, pre-training and their impact on image classification and object detection.
Problem Statement
The traditional approach in training the computer vision model is through going through large datasets and then labeling the data which is very costly. Often in many practical situations like the ones based on the new or the dynamic visual classes, such labeled data may not be easily available. Moreover, the methods of supervised learning are limited to one class, and they do not generalize well in other cases with few samples. This has the implication of a need for a more efficient mechanism of utilizing the available data in the best way possible in order to improve the performance of the chosen model in a number of operations.
High Cost and Time-Consuming:
-
Expense: This means that, when signing labels, organisers have to target the best and the most qualified annotators, hence the costs are high. Tasks such as medical image annotations which can be complex work should attract higher remunerations since the experts are trained to carry out the task.
-
Time: In most of the occurrences, the specific function of annotating large sets of data might take several weeks or even months, which hinders the model development and deployment process.
Impracticality for New or Dynamic Categories:
-
Novel Categories: Acquiring labeled datasets for new or emerging visual categories is a difficult task. For instance, recognizing a new species of animal involves a herculean tasks of coming up with a name that will be adopted.
-
Dynamic Environments: Static extracted features of objects or scenes can be used in visual categories of objects during dynamic settings, for instance, change in street scenes where by new annotated datasets may be required thus making it too expensive and time-consuming.
Limited Generalization and Overfitting:
-
Overfitting: Some supervised models might learn every detail in the training data set and, therefore, when exposed to new data sets, these models might not generalize well.
-
Performance Issues: It has been ascertained that use of few labeled examples during model training would not succeed to perform well on practical domains as sufficient learning of robust features does not occur with such methods.
Scarcity of Labeled Examples:
Data Scarcity: In particular, such models may fail to learn properly in specific cases, when there is lack of labeled data, for example, in narrow specialized fields, in certain districts, or in cases of rare diseases, which results in low accuracy.
Solution: Self-Supervised Learning
 Fig 1 – High level flow of Supervised learning
Fig 1 – High level flow of Supervised learning
Self-supervised learning offers a solution by allowing models to learn from the inherent structure in unlabeled data. SSL creates its own supervisory signals by setting up tasks where the model learns to predict parts of the data from other parts, thus extracting useful features and representations. This approach has shown promise in overcoming the limitations of traditional supervised learning, particularly in scenarios with limited labeled data.
 Fig 2- Contrastive Learning flow
Fig 2- Contrastive Learning flow
Contrastive Learning Methods
SimCLR: Bridging Augmentations
SimCLR (Simple Contrastive Learning) is the revolutionary method that boosts the representation learning by taking into account the relations between different views of the same image. This model will work so that different augmentations of the same image should be as similar as possible whereas, augmentations of two different images should be as dissimilar as possible. This strategy is based on the generation of several transformed replicas of image and the adjustment of the model that resolves the distortions in the feature space.
Architectural Insights
In SimCLR, we use an encoder network that is deep neural network based and after that is a projection head that helps in mapping the feature vectors to a space where the contrastive loss is applied. This contrastive loss function is critically important for ‘attacting’ together positive pairs – augmentations of the same image – while ‘repelling’ apart negative, different images. Not only does this architecture learn a high-quality feature representation but also is versatile about the kind of vision tasks it can perform.
Applications and Achievements
This work shows that the models trained using SimCLR can be further fine-tuned for various tasks including classification and detection of objects. In practice this has been shown to produce good quality results, even surpassing conventional supervised learning methods when assessed on popular datasets such as Image-net. Due to the fact that SimCLR can utilize a big amount of unlabeled data, it becomes more useful in situations when the availability of labeled examples is a problem.
Contrastive Predictive Coding (CPC): Capturing Temporal Dynamics
CPC moreover expands the concept of contrastive learning to sequential data by retrieving futures based on the current context. Whereas the nature of the image data representation differs from the static image representation, CPC deals with the temporal aspect associated with the video data or time series sequences. The proposed model evaluates the model based on how well it can predict future frame or data point, which is helpful in addressing temporal and spatial characteristics.

Core Components
The CPC framework has a context encoder that processes the current frame or sequence and the subsequent prediction head that predicts subsequent frames. The key feature of training is the use of a contrastive loss function that helps to identify the correct future prediction against others. Such a setup allows for the CPC model to build good representations that incorporate continuity and structure that are available in sequences.
Impact and Usage
To the best of our knowledge, CPC has been used to solve a variety of video analysis problems including frame prediction and action recognition. Moreover, CPC models enable learning locally varying future frames by capturing better motion and temporal patterns in motion forecasting, video surveillance, vehicle autonomous driving, and activity recognition.
Pre-Training Techniques
 Fig 3– Pre training techniques flow
Fig 3– Pre training techniques flow
Auto encoders: Learning Robust Representations
Auto encoders are vital self-supervision learning where the main goal is to get the most efficient representation of data through the reconstruction. These models learn to compress the input data and then equally decompress it to its original form and this is achieved in the following manner. This happens as the objective of the auto encoder is to reduce the distance between the input and the reconstructed output thus useful features.
Variants and Applications
A denoising auto encoder incorporates noise to the input data and makes it to perform reconstruction of the original data without the noise; hence, it learns on how best to work with noisy inputs. This ability to learn robust features makes the Auto encoders useful in tasks such as image denouncing, feature extraction and anomaly detection where the ability to handle corrupted or incomplete data is very important.
Generative Adversarial Networks (GANs): Adversarial Learning for Realism
This comes into a GAN where there is a generator and a discriminator that are always competing. The generator then produces fake data and on the other end, the discriminator measures and assess the real as well as the fake data that has been generated by the generator. This adversarial setup is to bring out more accurate details during the training phase as well as produce improved features.
Training Dynamics
Former is the generator whose objective is to produce ‘real’ data whereas the latter is the discriminator whose purpose is to distinguish ‘real’ from ‘fake’ data. This dynamic also improves the model’s ability to produce realistic data or other intricacies integral to its learning. GANs are especially effective for applications where the quality of the generated or transformed data is critical for downstream tasks and is, therefore, applied for data synthesis tasks, stylization, and data augmentation.
Pre-Trained Language Models (PTM): Cross-Domain Influence
PTMs such as BERT and GPT which are designed for NLP have nice methodologies for CV. Such models are built to learn contextual knowledge from large text corpus, knowledge that has been incorporated to improve visual models.
Knowledge Transfer
Like PTMs, Computer Vision involves pre-training models on large-scale images or text-image pair data and then fine-tuning specific vision-related tasks. This approach builds on the fact of contextual understanding provided by pre-training so as to achieve better results in downstream tasks such as image captioning or visual question answering.
Applications in Classification and Object Detection
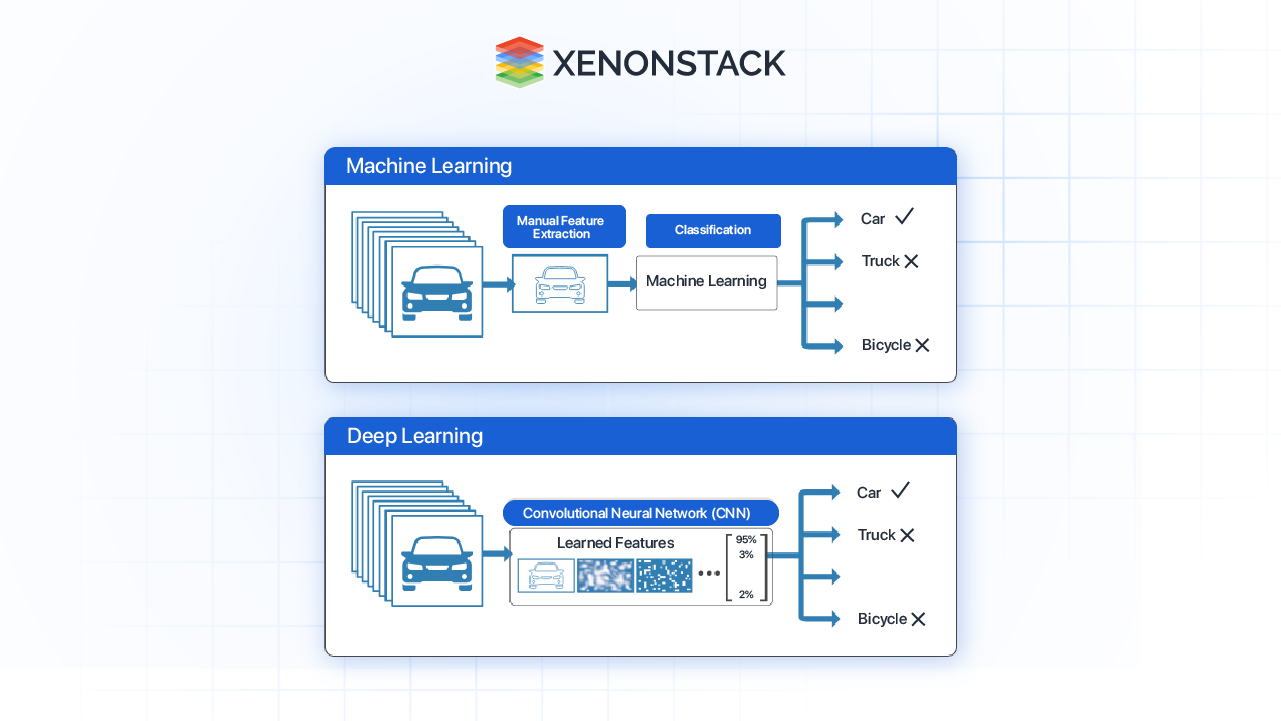
Revolutionizing Image Classification
Conversely, contrastive based methods of drove breakthrough in image classification by learning generalisation features from the raw unlabeled data. The above techniques used in training models of this nature have recorded high classification accuracies particularly in the Benchmark models such as the Image Net; though as mentioned earlier, their effectiveness is well evident from the ability to classify multiple objects with precision.
Impact on Model Performance
Reducing the dependence on large labeled datasets through pre-training on a large amount of unlabeled images and then fine-tuning on particular tasks makes image classification more efficient and scalable solutions. This approach is particularly useful in cases where there is a small number of training examples/to train the classifier or in cases where there are visual categories that are constantly emerging, changing or dying.
Enhancing Object Detection
When it comes to object detection, self-supervised learning methods play an important role in enhancing the model’s performance of detecting and localizing objects present in an image. Thus, the object detection accuracy is improved and the process becomes more efficient with help of fine-tuning based on pre-trained representations.
Practical Implications
This reveals that the pre-training with self-supervised approaches leads to better performance on the object detection when labeled data is little. This is especially important for the application of self-driving cars where the positioning of objects is very important in enabling the functionality as well as safety of the car.
Conclusion of Self-Supervised Learning
From the discourse, self-supervised learning is a giant leap in computer vision where efforts for labeled data and models are focused. The latter is at the heart of the current evolution and contrastive learning methods and pre-training techniques can learn in large amounts of unlabeled data and are extremely efficient in applications such as image classification as well as object detection. Considering the continued progress of research along with the growth of technology, self-supervised learning represents an ever more important field in the creation of more efficient and effective forms of computer visioning.




























