

Overview of Text-to-Image Generation
In today's data-driven world, organizations are increasingly seeking innovative ways to harness the value of unstructured information. One such emerging area is text-to-image generation, which combines natural language processing (NLP) and Generative AI techniques to convert text descriptions into visual art. With platforms like Databricks simplifying access to big data and machine learning tools, implementing advanced text-to-image solutions has become more feasible than ever before. By employing state-of-the-art generative models such as GANs, VAEs, and Diffusion Models, organizations can unlock unprecedented possibilities for creative expression, marketing campaigns, and educational materials, ultimately driving engagement, enhancing customer experience, and fostering innovation.
Overview of its Applications and Benefits
Text-to-image generation has garnered considerable interest among researchers, artists, and industry professionals alike, thanks to its wide range of practical applications and numerous benefits. Some prominent areas where text-to-image synthesis is being applied include:
-
Content creation: Brands and agencies leverage automated content production workflows powered by text-to-image generation algorithms to rapidly produce engaging graphics and animations at scale, streamlining marketing efforts and minimizing costs.
-
Virtual reality & gaming: Game studios and immersive tech companies rely on text-to-image technologies to populate expansive virtual environments with realistic objects, characters, and landscapes, enabling richer user experiences.
-
Education & research: Educators utilize interactive visual aids derived from descriptive texts to facilitate comprehension and knowledge retention, while researchers apply text-to-image tools to augment scientific studies involving complex patterns and structures.
-
Accessibility: Assistive technologies incorporating text-to-image functionality help individuals with disabilities better understand written material by translating abstract concepts into vivid imagery.
-
Entertainment & arts: Creative professionals exploit the expressiveness of text-to-image systems to craft captivating narratives, compelling performances, and unique pieces of artwork, pushing boundaries of imagination and artistic expression. In today's data-driven world, organizations are increasingly seeking innovative ways to harness the value of unstructured information.
Deep Learning Methods for Text-to-Image Generation
Deep learning techniques serve as the foundation for contemporary text-to-image generation algorithms, providing the necessary modeling capacity to learn intricate mappings between linguistic constructs and perceptual stimuli. Among the popular deep learning methodologies utilized in text-to-image tasks are Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs):
-
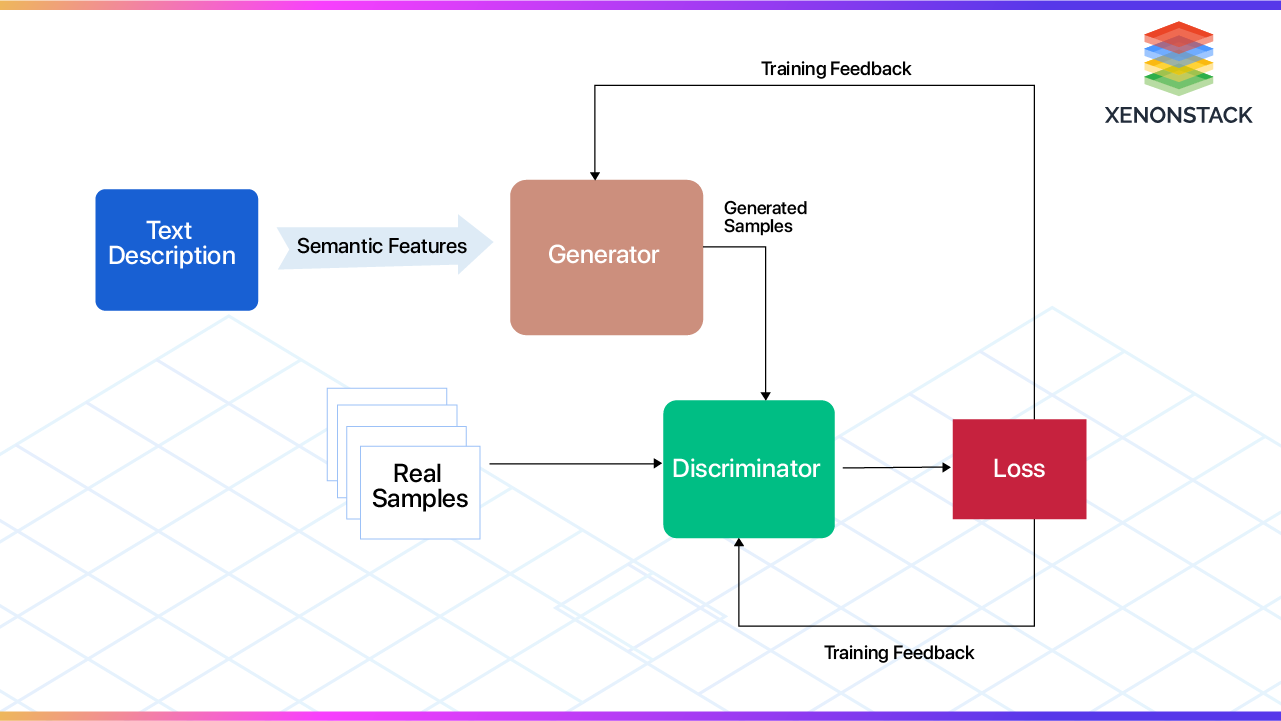
Generative Adversarial Networks (GANs): Comprised of two primary components—a generator network and a discriminator network—GANs participate in a zero-sum game during training. The generator creates plausible images based on random noise vectors, while the discriminator distinguishes real images from those produced by the generator.
-
Variational Autoencoders (VAEs): VAEs employ probabilistic graphical models to represent images within low-dimensional spaces using continuous latent variables. An encoder network maps input images onto probability distributions outlining potential pixel intensity variations, whereas a decoder network rebuilds original images from sampled points drawn from these distributions.
Using Databricks for Text and Image Data Processing
Databricks is a powerful unified analytics platform that allows you to process and analyze massive volumes of structured, semi-structured, and unstructured data quickly.
Utilizing Databricks for Managing Large-Scale Text and Image Data Sets
Handling Text Data in Databricks
-
Data Ingestion: Import textual datasets from various sources, including cloud storage services, databases, or local files using Databrick's file reader APIs. For example, you may use spark.read.text() to read plain text files into a data frame.
-
Text Preprocessing: Perform common NLP techniques like tokenization, stemming, lemmatization, stopwords removal, and vectorization within Databricks using libraries like NLTK, spaCy, or Gensim. Additionally, integrate these libraries with PySpark for parallelized text processing across clusters.
-
Feature Engineering: Extract meaningful features from raw text data through techniques like Term Frequency-Inverse Document Frequency (TF-IDF), Word2Vec, Doc2Vec, or BERT embeddings. These techniques help convert text information into numerical representations suitable for machine learning algorithms.
-
Model Training & Evaluation: Train ML models based on extracted features using built-in libraries like sci-kit-learn, TensorFlow, Keras, PyTorch, or Hugging Face Transformers. You can leverage Databricks' auto-scaling capabilities to allocate resources efficiently during model training.
-
Deployment: Deploy trained models directly from Databricks using MLeap, TorchServe, TensorFlow Serving, or other model serving platforms. This enables real-time prediction via RESTful API endpoints, which can be easily integrated with web applications or external systems.
Working with Images in Databricks
-
Loading Images: Start by importing pictures saved in formats like JPEG, PNG, or TIFF using Databricks functions such as binary files. Then, modify any required metadata, change picture sizes, or cut out areas of interest.
-
Preparing Images: Improve your dataset by changing aspects like orientation, flipping, zooming, or lighting with libraries like OpenCV or imaging. Carry out these processes simultaneously on many computers using PySpark User Defined Functions (UDFs) for quicker outcomes.
-
Creating Features: Use convolutional neural networks (CNNs) to extract useful characteristics from image details. Harness ready-to-use networks—such as VGG16, ResNet, or DenseNet—and modify them according to needs through transfer learning.
-
Learning Model & Assessment: Teach computer vision models with tagged picture collections and assess their correctness using tactics like k-fold cross-validation, splitting evenly, or drawing with replacement. Keep tabs on overfitting through frequentation procedures and early termination rules.
-
Implementation: Save educated designs and set them up employing solutions like TensorFlow Serving, ONNX Runtime, or TorchServe. Combine established models with manufacturing lines for real-time object recognition, partitioning, or categorization chores.
Best Practices for Data Preprocessing and Feature Engineering
-
Optimize resource allocation by setting appropriate task granularity levels when working with distributed computing environments.
-
Cache frequently accessed datasets to avoid recalculating intermediate results repeatedly.
-
Implement efficient logging mechanisms for tracking progress, debugging issues, and measuring performance indicators throughout the pipeline.
-
Choose the right evaluation metric(s) tailored to the problem domain and ensure they align with business objectives.
-
Regularly validate assumptions made about input data distributions and update preprocessing steps accordingly if needed.
-
Benchmark different feature engineering techniques against each other to select those yielding optimal downstream model performance.
Understanding Generative AI Models for Image Synthesis
Generative AI has revolutionized the field of computer graphics, enabling realistic and diverse image synthesis. Various generative models exist; here, we explore three prominent categories: Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Diffusion Probabilistic Models (DPMs). Each has unique advantages and shortcomings. We will discuss key features, evaluation criteria, and challenges related to these models.
Introduction to Different Types of Generative AI Models
Generative Adversarial Networks (GANs): Introduced by Ian Goodfellow et al. in 2014, GANs consist of two neural networks - a generator and a discriminator - competing against each other iteratively. The generator learns to produce synthetic images indistinguishable from real examples, whereas the discriminator tries to discern actual vs. artificial inputs. Over time, the competition drives the generator toward increasingly convincing outputs.
Variational Autoencoders (VAEs): VAEs are probabilistic graphical models proposed by Kingma and Welling in 2013. They combine principles from traditional autoencoders and Bayesian inference. Unlike standard autoencoders, VAEs allow sampling latent space vectors for generating new instances. Through stochastic variational inference, VAEs minimize reconstruction error while preserving coherent output structures.
Diffusion Probabilistic Models (DPMs): DPMs are recently developed generative models introduced by Ho et al. in 2020. They rely on diffusion processes to gradually add noise to input data until reaching pure Gaussian noise. Later, another denoising procedure generates novel plausible samples by reversing the noising operation stepwise.
Key Features and Strengths of Each Model Type
|
Model Type |
Key Features |
Strengths |
|
GANs |
High realism, detailed images, complex data distributions, correlations across modalities, continuous training |
Surpassing earlier generative models, capture complex data distributions and correlations, support continuous training |
|
VAEs |
Tractable likelihood estimation, flexible generation modes, disentanglement studies |
Facilitate principled evaluations and comparisons, offer flexible generation modes, enable disentanglement studies |
|
DPMs |
Strong empirical performance, robust theoretical guarantees, uncertainty quantification |
Comparable performance to state-of-the-art techniques, and robust theoretical guarantees, allow for uncertainty quantification |
Challenges and Limitations Associated with Current Generative AI Models
|
Challenge |
Limitations |
|
Instability |
Poor convergence, mode collapse |
|
Entanglement |
Complicated interpretability, hindered factorizations |
|
Complexity |
Significant computational resources, extensive tuning |
|
Explainability |
Black box nature, lack of transparency |
Transforming Text Descriptions into Visual Art
Creating visual art from text descriptions is an exciting area in machine learning, with applications ranging from entertainment to accessibility tools. This section will explore various techniques used to convert textual descriptions into visual art, including pre-trained NLP models, encoder-decoder architectures, multi-modal embeddings, strategies for improving image quality and diversity, and optimization methods.
A. Pretraining NLP Models for Understanding Text Semantics
Pre-trained NLP models can be fine-tuned to better understand text semantics. These models are trained on large datasets, enabling them to capture linguistic patterns and relationships between words. To generate visual art from text descriptions, it's crucial to comprehend the meaning, context, and intent behind the given input. Fine-tuning these models helps extract relevant features that guide the generation process. Popular choices include BERT, RoBERTa, or DistilBERT for natural language understanding tasks.
B. Encoder-Decoder Architecture Design Considerations
Encoder-decoder architectures play a vital role in converting text descriptions into visual art. The encoder processes the input text description, capturing its essence and representing it as a compact vector representation. Simultaneously, the decoder generates pixels iteratively based on this vector until a complete image emerges.
Design aspects like attention mechanisms, recurrent neural networks (RNN), long short-term memory (LSTM), gated recurrent units (GRU), or transformers significantly impact performance. Attention allows focusing on specific parts of the input while generating different regions of the output image, resulting in higher fidelity. Additionally, selecting appropriate dimensionalities and layers within the model ensures efficient information flow during the encoding and decoding stages.
C. Multi-Modal Embedding Techniques
Multimodal embeddings combine text and visual representations by projecting both onto a shared latent space. They enable effective interaction between language and vision components, facilitating accurate translation of textual concepts into their corresponding visual elements. Commonly employed techniques involve using convolutional neural networks (CNN) for image processing combined with recurrent neural networks (RNN) or transformer-based models for text handling. Fusion strategies such as concatenation, element-wise summation, or multiplicative interactions further enhance integration at the feature level.
Application and Use Cases of Text-to-Image Generation
As text-to-image generation technology becomes more sophisticated, it has a wide range of potential applications across industries. In this section, we will explore six possible use cases for this technology
-
E-commerce Product Visualization: One exciting application of text-to-image generation is in e-commerce product visualization. With this technology, customers can input descriptions or specifications of products they are looking for, such as color, size, shape, and style. The system would then generate images of those products based on the customer's preferences, allowing them to see exactly what they want before making a purchase decision.
-
Personalized Advertising and Social Media Content Creation: Another promising area for text-to-image generation is in personalized advertising and social media content creation. Brands can use natural language processing algorithms to analyze user data, including search queries, browsing history, and demographic information, to generate tailored advertisements and posts.
-
Customizable Avatars and Virtual Worlds: Customizable avatars and virtual worlds offer another intriguing opportunity for text-to-image generation. Users can create unique characters based on descriptive inputs, enabling greater self-expression and creativity.
-
Realistic Video Game Assets and Special Effects: Realistic video game assets and special effects represent yet another compelling use case for text-to-image generation. Developers can harness this technology to automatically generate detailed character models, environmental objects, and visual effects based on written descriptions.
Future Trends in Text-to-Image Generation Technologies
The field of text-to-image generation technologies is rapidly evolving, driven by advances in artificial intelligence, machine learning, and computational power. As researchers continue pushing the boundaries of what's possible, several key trends and innovations are emerging:
Advances in Generative AI models and optimization strategies
-
Development of novel GAN architectures, such as StyleGAN and BigGAN, capable of producing highly realistic and diverse image samples.
-
Progress in diffusion models, which simulate physical processes to generate high-fidelity images from random noise distributions.
-
Exploration of alternative loss functions and regularization techniques to mitigate common issues like mode collapse and overfitting.
Integration of reinforcement learning and other ML approaches
-
Utilization of deep deterministic policy gradients (DDPG) and proximal policy optimization (PPO) algorithms in conjunction with GANs for fine-grained control over image generation parameters.
-
Leveraging meta-learning techniques to facilitate fast adaptation of pre-trained models to new domains or tasks within text-to-image synthesis.
-
Application of few-shot learning paradigms to minimize reliance on labeled data, thereby improving robustness and adaptability across varied input contexts.
Scalability improvements via cloud computing and distributed processing
-
Implementation of containerization technologies like Docker and Kubernetes for managing microservices architecture in text-to-image pipelines.
-
Orchestration of horizontal scaling strategies across multiple GPU instances to accommodate fluctuating demands in computing resources.
Ethical concerns around privacy, ownership, and responsible usage
-
Establishment of legal frameworks governing the creation, dissemination, and commercial exploitation of synthetic images derived from textual descriptions.
-
Development of transparent labeling standards to distinguish authentic content from computer-generated counterparts.
Conclusion
In conclusion, this blog discusses the process of converting text descriptions into visual art using Databricks for data processing and generative AI models for image synthesis. The article highlights various types of generative AI models such as GANs and VAEs, along with their key features and evaluation criteria for selection. It also covers techniques for converting text descriptions into images including pretraining NLP models, encoder-decoder architectures, multi-modal embedding, and optimization methods. Various applications and use cases are presented, ranging from e-commerce and personalized advertising to interactive learning environments and automated interior design. Looking ahead, advances in generative AI models, integration of reinforcement learning, scalability improvements, ethical concerns, and potential impacts on society are all highlighted as important areas for future research and development. Overall, the blog encourages continued exploration and experimentation in the exciting field of text-to-image generation technologies.
-
Explore the importance of Generative AI in Cyber Securities
-
What are the basic Ethics of Artificial Intelligence?
-
Learn How to Build a Generative AI Model for Image Synthesis?




