
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Introduction to Apache Storm and Kerberos
Apache Storm plays an important role to manage the smooth functioning of the operational database. Before starting with how we can secure Storm with the help of Kerberos. Let us discuss what actually is Storm and Kerberos are:
Big Data Architecture helps design the Data Pipeline with the various requirements of either the Batch Processing System or Stream Processing System. Click to explore about, Big Data Architecture
What is Apache Storm?
Storm is a distributed real-time computation system that is free and open source. As the number of IOT devices is increasing at an enormous range which results in high streams of data at a very short interval which results that we need very large data memories for storing, data processing and analyzing these heavy data to get some actionable results. In this case, It is the best method to deal with this situation. It helps in storing, processing, analyzing and publishing real-time data without storing any actual data.
What is Apache Kerberos?
Kerberos is an authentication protocol which helps us in providing a secure login to the network over the unsecured network. This uses the concept of the encrypted tickets and helps us reduce the amount of the password time sent through the network. This concept of keys is controlled by KDC (key distribution center). The generated ticket will be verified or we can say authentication takes place and then the secure connection will be established.
A platform or framework in which Big Data is stored in Distributed Environment and processing of this data is done parallelly. Click to explore about, Apache Hadoop Security with Kerberos
What is the Apache Storm Architecture?
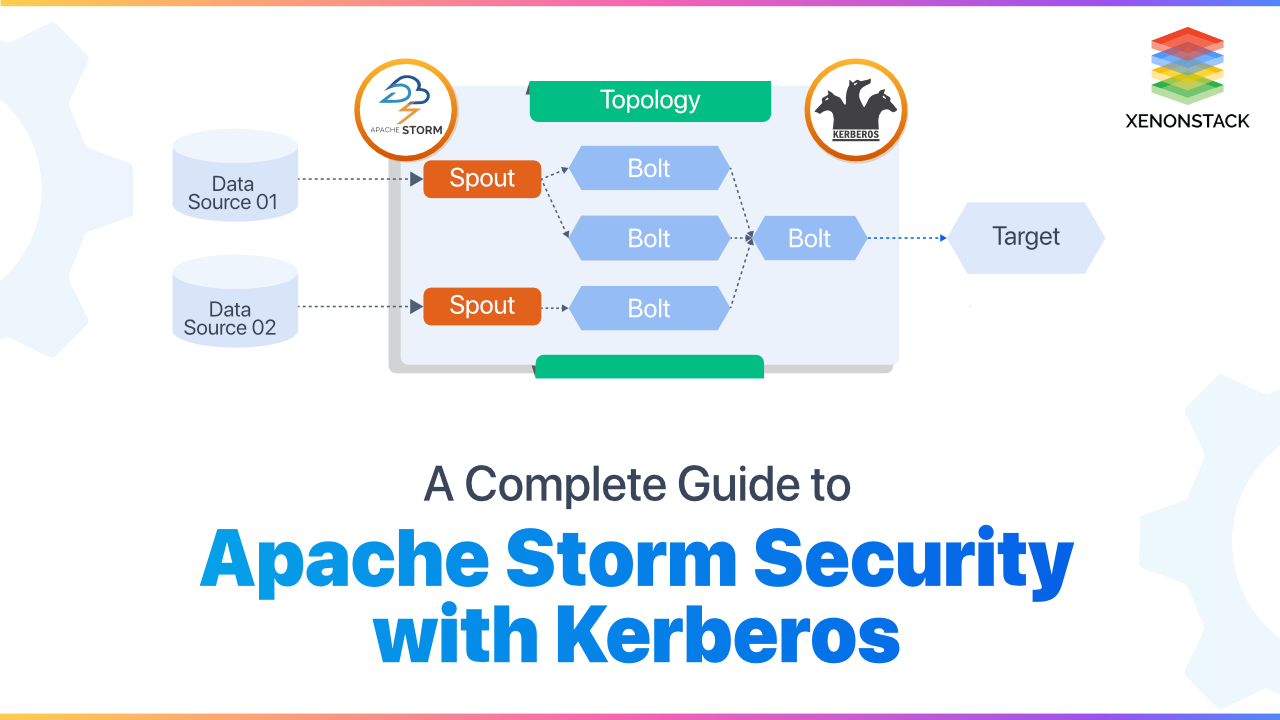
The main component of the Storm is the checkpoints named as spouts and bolts. The coming stream of data is passed from one checkpoint to another where the filtering, analyzing and aggregation of the data takes place. After this process occurs then that filtered stream is passed for the people to view. The streams of data are ejected by Data sources kept and then passed to spout and then bolt and finally to target and to provide Apache Storm Security Now let us discuss the actual meanings of the components.
- SPOUT: The stream of data that is emitted by the Data Source is taken by the spout. The main purpose of the Spout is to receive data from the data sources continuously and then transfer this received data into the actual format of million tuples processed per second per node of tuples and then send this to Bolts for further processing.
- BOLTS: The stream of data that is made into tuple form by the spout is received by the bolts. To Perform all the processing functions on this stream is the work of bolts. The major functions performed by the bolts are filtering, joining, aggregation, connecting to the database, etc. The main uses of this Storm are in analysis in real-time, machine learning online, distributed Remote Procedure Calls, and many more. We can assume the speed of the Storm is as noticed over a million tuples processed per second per node. Setting up apache storm is easy and will guarantee the data process.
RDD is the fundamental data structure of Spark. They are immutable Distributed collections of objects of any type. Click to explore about, Guide to RDD in Apache Spark
How to Secure Storm with Kerberos?
To provide Apache Storm Security, a common setup for handling big data projects is Kerberos. For Kerberos authentication of Storm we setup a KDC and Kerberos are configured at each node. There are two main nodes i.e. Nimbus and Supervisor node.
First of all, we have to make some changes to the storm.yaml file and then copy this changed storm.yaml on each Nimbus and Supervisor node in /home/mapr/.storm/ directory. After this, we will generate a new Kerberos ticket that will be acting as a key to lock for entering these nodes. Now let us see how we can implement this practically .Storm.yaml file contains the configuration of apache storm and we need to add
yamlstorm.thrift.transport:"org.apache.storm.security.auth.kerberos.KerberosSaslTransportPlugin" java.security.auth.login.config: "/path/to/jaas.conf"
Djava.security.auth.login.config=/path/to/jaas.conf
kinit -kt /opt/mapr/conf/mapr.keytab -p mapr/<fqdn>@<realm>
http://<hostname>:<UI_port>/?user.name=mapr
A Comprehensive Approach
Apache Storm due to its comprehensive feature helps Enterprises to process data faster, solving complex data problem in very less time. However, providing security to secure operational data matters the most. To know more about Storm we advise taking the following steps –- Discover more about Apache Spark Optimization Techniques
- Explore here about Apache Spark Security


























