
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)

What Is Augmented Data Quality and Why Does It Matter for Enterprise Data Operations?
Data quality has always been a prerequisite for reliable analytics, operational decisions, and regulatory compliance. What has changed is the scale of the problem. As data volumes grow exponentially across cloud environments, IoT systems, and distributed architectures, manual data quality processes — profiling, matching, cleansing, merging — cannot scale proportionally with the data they are meant to govern.
Augmented Data Quality (ADQ) addresses this directly. By applying AI, machine learning, and automated pattern recognition to data quality workflows, ADQ reduces manual effort, accelerates quality assurance at scale, and surfaces data quality issues before they propagate into analytical outputs, AI models, or compliance reports.
Key Takeaways
- Manual data quality processes — profiling, cleansing, matching, merging — cannot scale with enterprise data volumes. Augmented Data Quality automates these workflows using AI and ML to reduce manual effort and improve consistency.
- ADQ applies five core functions: automated profiling, rule suggestion, pattern-based cleansing, deduplication, and real-time monitoring — replacing point-in-time audits with continuous quality governance.
- The five primary data quality failure modes (duplication, wrong representation, poor formatting, fragmented sources, outdated information) are each addressable through specific ADQ techniques.
- For CDOs and CAOs: ADQ is the governance layer that makes data-driven decision-making reliable at scale. Without it, data quality degrades as volume grows — silently eroding the analytical outputs and AI model performance that the organization depends on.
- For Chief AI Officers and VPs of Analytics: AI and ML model performance is directly bounded by upstream data quality. ADQ ensures that the training data, inference inputs, and analytical datasets feeding your models meet consistent quality standards — without requiring manual validation at every pipeline stage.
What Is Data Quality and Why Does It Fail at Scale?
Definition: Data quality is the measure of whether data is fit for its intended use — accurate, complete, consistent, timely, valid, and unique. Poor quality data is data that fails on one or more of these dimensions.
Why traditional approaches fail at scale: Manual data quality processes depend on human review cycles — periodic audits, validation scripts, and exception queues managed by data engineering teams. As data volume grows, the ratio of data to human review capacity widens. Quality issues that would have been caught in a smaller dataset propagate undetected into production systems, analytical models, and compliance reporting.
The organizational cost: Decisions made on poor quality data are not just wrong — they are confidently wrong. Incorrect data produces outputs that appear valid, which is worse than no output at all, because the error propagates before it is caught.
A measurement of the scope of data for the required purpose. It shows the reliability of a given dataset. Taken From Article, Data Quality Management
What Is Augmented Data Quality and How Does It Differ from Traditional Data Quality Management?
Definition: Augmented Data Quality is the application of AI, machine learning, and automated pattern recognition to automate data quality tasks — profiling, matching, cleansing, merging, and monitoring — that were previously performed manually.
The core distinction from traditional data quality management:
| Dimension | Traditional Data Quality | Augmented Data Quality (ADQ) |
|---|---|---|
| Process model | Periodic, manual audit cycles | Continuous, automated monitoring |
| Rule definition | Manually authored by data engineers | AI-suggested based on dataset patterns |
| Issue detection | Reactive — after issues enter production | Proactive — flagged at point of entry |
| Deduplication | Manual matching or scripted rules | Automated identifier-based algorithms |
| Scale | Degrades as volume grows | Scales proportionally with data volume |
| Integration | Point-in-time checks | Embedded in data pipeline as governance layer |
Business outcome: ADQ shifts data quality from a periodic remediation project to a continuous operational capability — enabling organizations to sustain data quality standards as data volumes, sources, and complexity grow.
Why is Data Quality important for organizations?
Because decisions and planning depend on correct and complete data.
What Are the Five Core Data Quality Failure Modes ADQ Addresses?
Each failure mode represents a specific class of data quality degradation that manual processes cannot reliably catch at scale:
-
Data Duplication Multiple sources store similar data with different interpretations of the same facts. Duplicate records distort aggregations, inflate counts, and produce false signals in analytical outputs. ADQ addresses this through automated identifier-based deduplication algorithms and SQL-driven filter rules applied continuously.
-
Wrong Data Representation Inaccuracies in how data is recorded — incorrect addresses, misformatted identifiers, wrong field mappings — produce downstream failures that are difficult to trace to their source. ADQ catches representation errors at the point of entry through validation rules enforced before data reaches storage.
-
Poor Data Formatting Inconsistent formatting across datasets — date formats, naming conventions, units of measurement — creates reconciliation failures when data is joined or aggregated across systems. ADQ applies format standardization rules uniformly across datasets without manual intervention.
-
Fragmented Data Sources Data silos across disparate systems prevent comprehensive cross-domain analysis. ADQ integrates data from distributed sources into a unified quality layer, enabling real-time analytics without requiring centralization of the underlying data.
-
Outdated Information Stale data that persists in databases without refresh governance creates inconsistencies that are invisible until they produce incorrect outputs. ADQ applies time-based monitoring to flag data that has exceeded defined freshness thresholds.
What is the fastest way to improve Data Quality?
Add validation at the source and verify data before saving.
What are Convolutional Neural Networks?
- Firstly, Convolutional means we have two functions, A and B. We apply one operation, C, on both A and B, which defines how function A produces function B, so in this example, C is Convolutional. Secondly, Neural Networks mean that our brain has lots of connected neurons, which help us learn things. For example, if we see a person's face a second time, our brain will recognize faces. Similarly, in data, AI has the concept.
- CNN is a technique that is used for recognizing the Image. In simple words, recognizing the Image means seeing the object, animals, or anything as an image and then seeing the edges of images, for example:
- As we know, images are categorized into grayscale images(means ranges 0 to 255, black and white ) and coloured images combined with RGB). We can also scale down the Image by 0's and 1's.

0's represent white, and 1's as black. And between 0's and 1's, we have vertical edges. As we see, this Image is 6X6 pix, and when we apply a 3X3 filter on it, we get a 4X4 filter
4X4 filter
In the 4X4 Image, we can apply the min-max scale, which means converting the minimum value to 0 and the maximum value to 255 because the maximum value is 255. In the final, we get the middle layer(the middle two layers), which is our white side, and the first and last are our dark sides.
Why are CNNs mentioned in Augmented Data Quality?
Because CNN-based augmentation creates variations that help improve training data quality.
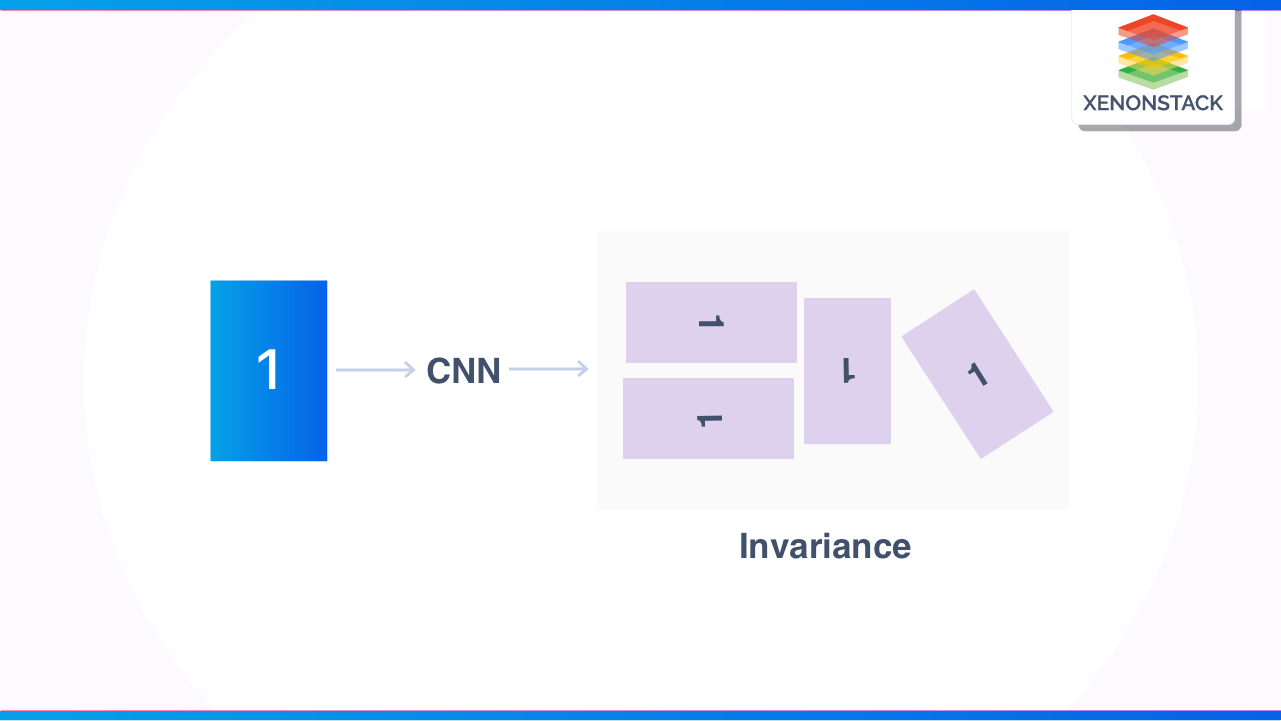
Why do we need Augmented Data Quality?
By Augmented Data Quality, we will analyze information daily to identify the pattern of data quality. As the volume of data increases daily, organizations will evolve to transform into data-driven organizations; to speed up this process, they will augment their data to improve the quality of data.
Suppose we have very few images, and we want many photos. In that case, we will have different invariances or transformations on images, and we get lots of images from pictures because, let's take an example. If we pass input is X(A), then output is Y(A). If the input is X(B), the output is Y(B).
Automate the Data Quality Task: Profiling, matching data, poor quality warning, and merging are data quality tasks that are automated by Augmented Data Quality functions to improve data quality.
Why do organizations use Augmented Data Quality?
To improve data quality at scale as data volume grows daily.
How does Augmented Data Quality work?
We will create new augmented data by applying reasonable filters on data or images. We can augment the text, images, audio, and other data. For Image augmentation, we use TensorFlow or Keras. Keras uses various layers to apply augmentation to data.
Data Observability combines data monitoring, tracking, and troubleshooting to maintain a healthy data system. Explore here How Data Observability Drives Data Analytics Platform?

What Are the Core Features of Augmented Data Quality Systems?
1. Data Integration
ADQ combines data from distributed sources into a unified, well-structured quality layer — supporting real-time analytics without requiring physical data movement. Traditional tools that move and replace data for quality purposes cannot achieve real-time integration at enterprise scale.
2. Unstructured Data Handling
Most enterprise data does not conform to rigid schemas. ADQ addresses missing values, corrupted records, and schema-inconsistent data through automated pattern detection and remediation — handling data that traditional validation rules cannot process.
3. Accuracy Measurement
ADQ measures data accuracy through configurable upper and lower bound rules. For example: if a defined accuracy threshold requires 93–97% of completed records to meet a quality standard, ADQ monitors this range continuously and flags deviations at the point they occur — not after they have propagated.
4. Rule Suggestion and Pattern Recognition
Rather than requiring data engineers to manually author quality rules for every dataset, ADQ analyzes existing data patterns and suggests rules for cleansing and merging. This accelerates rule definition and reduces dependency on manual domain expertise for every new data source.
A data mesh architecture is a decentralised approach that allows domain teams to independently perform cross-domain data analysis. Click to explore Adopt or not to Adopt Data Mesh? - A Crucial Question
What are the standard Data Quality checks?
The standard data quality checks are described below:
Uniqueness
If multiple items are repeated in our data, meaning if duplicate values are tremendous, then we will consider that data poor quality. ADQ will use the SQL rules to apply duplicate items or data filters. Once we can apply a filter, we apply it automatically to our data.
Completeness
We consider our Data complete when nothing is missing. We can set a search rule on null values to identify missing values or crucial vital data.
A data strategy is frequently thought of as a technical exercise, but a modern and comprehensive data strategy is a plan that defines people, processes, and technology. Discover here 7 Key Elements of Data Strategy
What Are the Six Best Practices for Implementing Augmented Data Quality?
1. Automate the core data quality tasks first Profiling, merging, cleansing, and monitoring should be automated before expanding scope. Automating these foundational tasks eliminates the highest-volume manual work and creates the baseline from which AI-driven rule suggestion can operate.
2. Start small and align to KPIs Begin with a single use case where data quality is measurable against a defined business KPI. Demonstrating measurable improvement in a contained scope — before expanding to larger datasets or more complex rules — establishes organizational confidence and a replicable methodology.
3. Prioritize deduplication Duplicate records are the most common source of data quality degradation at scale. Removing duplicates produces immediate, measurable improvement in analytical accuracy and should be the first optimization applied.
4. Establish a data recovery and backup policy Automated quality processes that modify or remove records must be recoverable. Every ADQ deployment requires a defined backup policy and rollback capability to prevent automated errors from permanently degrading the datasets they are intended to improve.
5. Apply rules to specific data types Data quality rules are most effective when scoped to specific data types — numerical ranges, categorical values, date formats. Real-time profiling enables type-specific rules to be applied continuously without requiring full dataset scans.
6. Implement a governing data approach Define conditions that determine which data is retrieved, from which sources, and at what frequency. A governing data approach ensures that ADQ operates on the right data with the right constraints — not uniformly across all available data regardless of business relevance.
How Does ADQ Work in Practice? The Processing Flow
Augmented Data Quality processes data through a structured transformation sequence:
- Ingest — Data enters the pipeline from source systems
- Profile — ADQ scans data to identify quality issues: missing values, duplicates, format violations, range breaches
- Apply rules — AI-suggested or manually defined quality rules execute against the dataset
- Transform — Cleansing, normalization, and deduplication are applied based on rule outputs
- Validate — Transformed data is checked against accuracy thresholds before progressing downstream
- Monitor — Continuous monitoring tracks quality metrics over time and triggers alerts when thresholds are breached
For image data specifically, ADQ uses tools such as TensorFlow or Keras to apply augmentation — rotation, scaling, zooming — generating dataset variants that expand training data coverage and improve model generalization without requiring additional data collection.
 Automate Data Quality processes and rules with Artificial Intelligence and Machine Learning. Augmented Data Quality Solutions
Automate Data Quality processes and rules with Artificial Intelligence and Machine Learning. Augmented Data Quality Solutions
Why Does ADQ Matter for AI and Analytics Readiness?
For Chief AI Officers managing AI model performance and VPs of Analytics responsible for analytical output quality, ADQ is the upstream dependency that determines whether model training and analytical workflows operate on trustworthy data.
AI models trained on duplicated, incomplete, or incorrectly formatted data produce confident outputs on a flawed foundation. The error is invisible at the model level — it originates in the data, and no amount of model tuning compensates for systematic data quality failures upstream.
ADQ creates the conditions for reliable AI deployment by ensuring that:
- Training datasets meet defined completeness and accuracy thresholds before model training begins
- Inference inputs are validated against quality rules before reaching production models
- Analytical datasets used for reporting and decision support reflect current, deduplicated, consistently formatted data
As organizations move toward data-driven decision-making at scale, ADQ is not optional infrastructure. It is the governance layer that makes analytical and AI outputs trustworthy enough to act on.
Conclusion: Augmented Data Quality as a Strategic Data Infrastructure Investment
Augmented Data Quality helps organizations maintain accurate, reliable, and usable data at a scale that manual processes cannot sustain. As data volumes grow and the organizational dependence on data-driven decisions and AI outputs deepens, the cost of poor data quality compounds — producing incorrect decisions with increasing confidence and decreasing detectability.
For CDOs, Chief Analytics Officers, VPs of Data and Analytics, and Chief AI Officers, the strategic case for ADQ is direct: it is the infrastructure layer that ensures the data feeding your decisions, models, and compliance reporting meets the quality standards those outputs require — continuously, automatically, and at scale.
The practical starting point is automation of the four core tasks — profiling, matching, cleansing, and monitoring — applied to the highest-value data domain first. From there, rule suggestion, deduplication, and cross-source integration compound the quality improvement progressively across the enterprise data landscape.
-
- Explore more about Augmented Data Management Best Practices
- Click to explore Augmented Data Management Solutions
- Know more about Data Management Services and Solutions

Next Steps with Augmented Data Quality
Talk to our experts about implementing compound AI system, How Industries and different departments use Agentic Workflows and Decision Intelligence to Become Decision Centric. Utilizes AI to automate and optimize IT support and operations, improving efficiency and responsiveness.


























