
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)

Introduction to Big Data Architecture
Big Data has been a buzzword in recent years. The increasing amount of data raises both the opportunities and the challenges of managing it.
Big Data Architecture is a conceptual or physical system for ingesting, processing, storing, managing, accessing, and analyzing vast quantities, velocity, and various data that are difficult for conventional databases to handle. It uses this data to gain business value since today's organizations depend on data and insights to make most of their decisions.
A well-designed Architecture makes it simple for a company to process data and forecast future trends to make informed decisions. The architecture of Big data is designed in such a way that it can handle the following:
-
Real-time processing
-
Batch processing
-
For Machine learning applications and Predictive analytics
-
To get insights and make decisions.
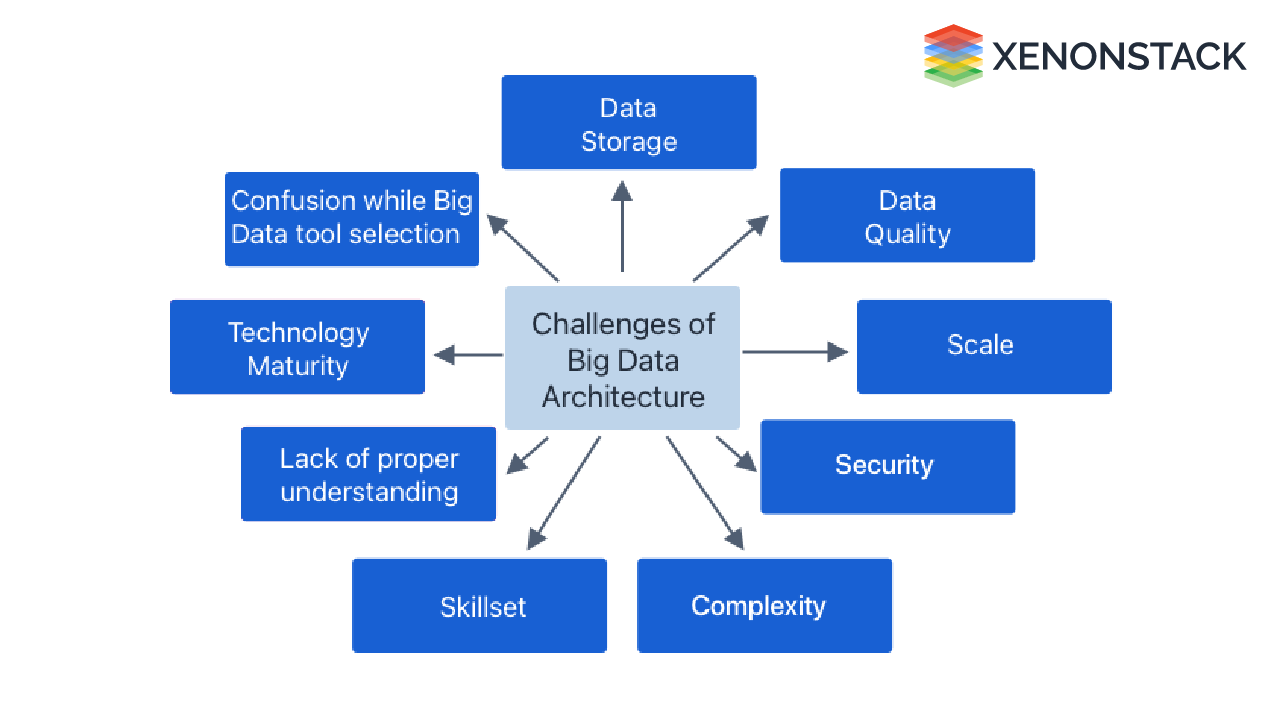
What are the Big Data Architecture Challenges?
Big data has tremendously changed industries, but it is not without challenges. Opting for a Big-data-enabled Data Analytics solution is not straightforward. It requires vast technology land space for components to ingest data from numerous sources. Proper synchronization between these components is also essential.
Building, testing, and troubleshooting a Big data WorkFlow is quite complex. Many organizations find it challenging to keep up with varying use cases. Below is the list of challenges; we look at them individually.
-
Data Storage
-
Data Quality
-
Scaling
-
Security
-
Complexity
-
Skillset
-
Lack of Awareness/Understanding
-
Technology Maturity
-
Big Data Tool Selection
Challenge # 1 - Data Storage in Big Data Architecture
While new technology for processing and storing data is on the way, the volume of data remains a significant challenge because it doubles in size about every two years.
Besides data size, the number of file formats used to store data is also growing. As a result, effectively storing and managing information is often challenging for the organization.
Solution
Companies use current approaches like compression, tiering, and deduplication to handle these massive data collections. Compression reduces the number of bits in data, resulting in a smaller overall size. The process of deleting duplicate and unnecessary data from a data set is known as deduplication.
Data tiering allows companies to store data in different storage tiers, guaranteeing that the data is stored in the best possible location. Depending on the size and significance of the data, data tiers might include public cloud, private cloud, and flash storage.
Companies also turn to Big Data technologies like Hadoop, NoSQL, etc.
Challenge #2 - Data Quality in Big Data Architecture
Data quality includes accuracy, consistency, relevance, completeness, and use fitness. For Big Data Analytics solutions, diverse data is required. Data Quality is a challenge anytime working with diverse data sources, for example, matching data format, joining them, checking for missing data, duplicates, outliers, etc.
Data must be cleaned and prepared before being brought for analysis. Consequently, obtaining useful data requires a significant effort to clean it to obtain a meaningful result. It is estimated that data scientists spend 50%—80% of their time preparing data.
Solution
You have to check and fix any data quality issues constantly. Also, duplicate entries and typos are typical, mainly when data originates from multiple sources. The team designed an intelligent data identifier that recognizes duplicates with minor data deviations and reports any probable mistakes to ensure the quality of the data they collect.
As a result, the accuracy of the business insights derived from data analysis has improved.
Challenge #3 - Scaling in Big Data Architecture
Big data solutions are used to handle large volumes of data. It can cause issues if the planned architecture is unable to scale. The output may suffer if the design cannot scale them. With the exponential increase in data volume being processed, the architecture may overwhelm the deluge of data they ingest, degrading application performance and efficiency.
To handle an overflow of data, auto-scaling allows the system to continuously have the right capacity to handle the current traffic demand. There are two types of scaling.
Scaling up is a feasible solution until it is impossible to scale up individual components any larger. Therefore, dynamic scaling is required. Dynamic scaling provides the combined power of scaling up with capacity growth and the economic benefits of scale-out. It ensures the system's capacity expands with the exact granularity needed to meet business demands.
Solution
Compression, tiering, and deduplication are some of the latest approaches businesses use to deal with enormous data volumes. Compression is a technique for lowering the number of bits in data and, as a result, the total size of the data.
Deleting duplicate and unnecessary material from a knowledge set is known as deduplication. Data tiering allows companies to store data in many storage layers and guarantees that the information is stored in the most appropriate location.
Depending on the size and relevance of the data, data tiers may include public cloud, private cloud, and flash storage. Companies also opt for Big Data technologies such as Hadoop, NoSQL, etc.
Challenge #4 -Security in Big Data Architecture
Although Big data can provide great insight for decision-making, protecting data from theft is challenging.
Data collected may contain personal and PII(Personally Identifiable Information) data of a person. GDPR (General Data Protection Regulation) is the data protection law to ensure the security of PII and personal information across and outside the European Union (EU) and European Economic Area (EEA).
According to the GDPR, organizations must protect their customers' PII data from internal and external threats. Organizations that store and process the PII of European citizens within EU states must comply with the GDPR.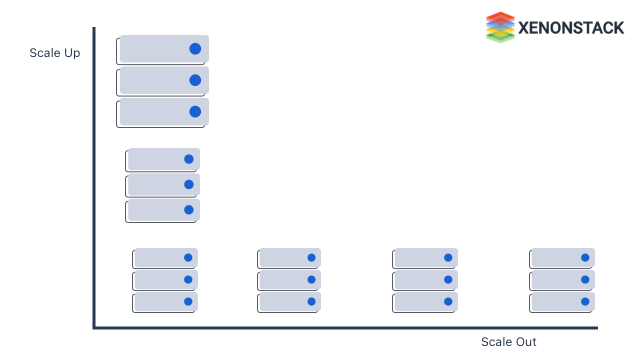
However, if architecture has a minor vulnerability, it is more likely to be hacked. A hacker can fabricate data and introduce it into data architecture. They can also penetrate the system by adding noise, making it challenging to protect data.
Big data solutions typically store data in centralized locations, and various applications and platforms consume data. As a result, securing data access becomes a problem. A robust framework is needed to protect data from theft and attacks.
Solution
Businesses are recruiting more cybersecurity workers to protect their data. Other steps to safeguard Big Data include Data encryption, Data segregation, Identity and access management, Implementation of endpoint security, Real-time security monitoring, and the use of security software for Big Data, such as IBM Guardian.
Challenge #5 -Complexity in Big Data Architecture
Big data systems can be challenging to implement since they must deal with various data types from multiple sources. Different engines might choose to run this, such as Splunk to analyze log files, Hadoop for batch processing, or Spark for data stream processing. Since each of these engines required its data universe, the system had to integrate all of them, which made it complex.
Moreover, organizations are mixing cloud-based big data processing and storage. Again, data integration is required here. Otherwise, each computer cluster that needs its engine will be isolated from the rest of the architecture, resulting in data replication and fragmentation.
As a result, developing, testing, and troubleshooting these processes becomes more complicated. Furthermore, it requires many configuration settings across different systems to improve performance.
Solution
Some firms use a data lake as a catch-all store for vast amounts of big data obtained from various sources without thinking about how the data would be merged. Various business domains, for example, create data that is helpful for joint analysis, but the underlying semantics of this data are frequently confusing and must be reconciled. According to Silipo, ad hoc project integration might lead to much rework.
A systematic approach to data integration frequently yields the highest ROI on big data initiatives.
Challenge #6 - Skillset in Big Data Architecture
Big data technologies are highly specialized, using frameworks and languages that aren't common in more general application architectures. On the other hand, These technologies are developing new APIs based on more developed languages.
For example, the U-SQL language in Azure Data Lake Analytics is a hybrid of Transact-SQL and C#. SQL-based APIs are available for Hive, HBase, and Spark. Skilled data professionals are required to operate these modern technologies and data tools. These will include data scientists, analysts, and engineers who use tools to extract data patterns.
A shortage of data experts is one of the Big Data Challenges that companies face. This is usually because data-handling techniques evolved rapidly, but most practitioners haven't. Solid action is required to close this gap.
Solution
Some firms use a data lake as a catch-all store for vast amounts of big data obtained from various sources without thinking about how the data would be merged. Various business domains, for example, create data that is helpful for joint analysis, but the underlying semantics of this data are frequently confusing and must be reconciled. According to Silipo, ad hoc project integration might lead to much rework. A systematic approach to data integration often yields the highest ROI on significant data initiatives.
Challenge #7 -Lack of Proper Understanding in Big Data Architecture
Insufficient awareness causes companies to fail with their Big Data projects. Employees can not understand what data is, how it is stored and processed, and where it comes from. Data professionals may undoubtedly know about it, but others might not understand.
If organizations don't understand the importance of knowledge storage, it is challenging to keep sensitive data. They may not use databases properly for storage, making retrieving vital data problematic when it is required.
Solution
Everyone should be able to attend big data workshops and seminars. Military training sessions must be developed for all personnel who deal with data regularly or who work near large data projects. A basic understanding of knowledge concepts must be instilled at all levels of the organization.
Challenge #8 - Technology Maturity
Consider this scenario: your cutting-edge big data analytics examines what item combinations clients purchase (for example, needle and thread) based on prior consumer behaviour data. Meanwhile, a soccer player posts his latest outfit on Instagram, with the white Nike sneakers and beige cap being the two standout pieces. It looks fantastic on them, and those who see it tend to dress similarly.
They rush out to get a pair of shoes and headgear that matches. However, your store sells shoes. As a result, you're losing money and possibly some regular customers.
Solution:
Technology does not analyze data from social networks or compete with online retailers, which explains why you didn't have the necessary goods in stock. And, among other things, your competitor's big data shows social media changes in near-real-time. And their store carries both pieces and offers a 15% discount if you buy them both.
Technology Maturity - Tricky Method of Turning into Useful Insights
You should create a sound system of variables and data sources whose analysis will provide essential insights to ensure nothing is out of range. External databases should be used in such a method, even though gathering and interpreting external data can be difficult.
Conclusion of Big Data Architecture
Organisations often get confused when selecting the most straightforward tool for giant data analysis and storage. They bother, and sometimes, they're unable to seek out the result. They find themselves making poor decisions and selecting irrelevant technologies due to the waste of money, time, effort, and work hours.
-
You can engage seasoned specialists who are significantly more knowledgeable about these instruments. On the other hand, travelling for big data consultancy is a unique experience.
-
Consultants will recommend the most basic equipment that can benefit your business. Based on their advice, you'll compute a technique and choose the most straightforward instrument.
Some of the significant data architecture challenges are discussed above. Addressing them is necessary to make correct, real-time data use possible. As a result, the above points must be considered when developing a significant data architecture.


























