
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
What are Protocol Buffers?
Protocol buffers language-neutral, platform-neutral extensible mechanism for serializing structured data over the network, think XML but faster, smaller and more straightforward. Google develops it for its internal server to server communication. You define how your data will be structured, and all data structures definition will be saved in the .proto file. Read and write structured data with a variety of data streams and a variety of languages. You can modernize your schemas without making changes to deployed programs that are compiled against the traditional schema. A quick summary before we started with the details -- Developed by google
- Cross-platform software
- Mostly used for internal protocols
Real-Time Big Data Analytics Services for Enterprises includes below services for enabling real-time decision making, clickstream analytics, fraud detection, Personalized User Experience and recommendations Explore Our Services, Streaming and Real-Time Analytics solutions
Why we need Protobuf?
JSON has many benefits as an information exchange format- it is human intelligible, understandable and typically performs great. It also has its issues. Where browsers and java scripts are not using the data directly - particularly in the case of internal communication services protocol buffers are the best choice over JSON for encoding data. It is a binary encoding format that permits you to define your schema for your data with a stipulation language. The Protocol Buffers stipulation is performed in different languages: Java, C, Go, etc. are all supported, and most modern languages have a practical implementation.- .proto file
- Python library
- C++ library
- Java library
How to Define Protocol Format?
• Types - Protobuf supports several common types that can be mapped to native language types. This includes multiple variations of integers, floating-point numbers, strings and Booleans Fields can be repeated to represent lists. Messages can also be nested. • Number - Each protobuf field has an arbitrary number assigned to it. This number is used to identify the field in the binary format and should be unique for the message. • Name - The field name is purely to improve readability and in code generation. It is not used in the serialized protobuf messagessyntax = "proto3"; package tutorial; message Person { required string name = 1; required int32 id = 2; optional string email = 3; enum PhoneType { MOBILE = 0; HOME = 1; WORK = 2; } message PhoneNumber { required string number = 1; optional PhoneType type = 2 [default = HOME]; } repeated PhoneNumber phones = 4; } message AddressBook { repeated Person people = 1; } Each field must be expounded with one of the following transformers: • Required • Optional • Repeated
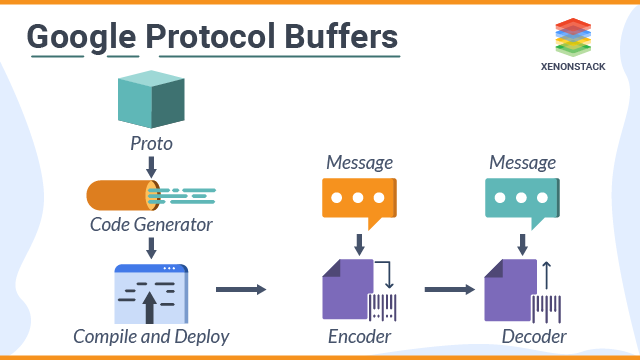
How does Google Protocol Buffers work?
Define the schema for data, and we need to start with. Proto file adds a message to each data structure for serializing them then add name and type for all field in the news. The syntax is similar to c++ or java. Let's go through the program and see what it does. It starts with the declaration, which helps to stop conflicts between different projects. the definition in your .proto file will not affect the generated code. Next, you have your message definitions. A message contains all sets of typed fields. Standard data types are available as field type you can choose according to a requirement including bool, int32, string float, double, etc. we can define nested type messages. The "= 1", "= 2" markers on all fields are a unique identifier that is used by the binary encoding. Tag between 1- 15 requires one or less byte to encode than a higher number. Go services Go API 000000 11111111 000000000 11111111 00000 1111110 00001111 000000 11111 NodeJS Server JS Server JS Objects JSON Client CALLS CALLS TRANSMITTED OVER THE WIRE SERIALISES DE-SERIALISES SERIALIZE TRANSMITTED • Define message formats in a .proto file. • Use the protocol buffer compiler. • Use the Python/java protocol buffer API to write and read messagesWho Should use Google protocol Buffers?
Don't use it if
• A browser consumes data from service. • Largely JavaScript Architecture. • Large Packet Sizes. • Young Start-up.Worth looking into if
• NodeJS server is talking to native android apps. • Micro-service architecture spanning multiple languages. • High data throughput.What are the Advantages of Protobuf?
- Lightweight
- Takes up less Space
- Faster transmission
- Validation of data structure
- Easy to modify the schema


























