
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)

Introduction to Kafka
The initial goal was to solve the low-latency ingestion of large amounts of event data from the LinkedIn website and infrastructure into a lambda architecture that leveraged Hadoop and real-time event processing systems. The "real-time" processing proved crucial. There were no real-time solutions for this type of ingress at the time.
Although there were solid methods for ingesting data into offline batch systems, they exposed implementation details to downstream users and used a push model that might rapidly overload a user. They were also not created with the real-time use case in mind. It was extremely difficult to get data from source systems and consistently move it around, and previous batch-based solutions and corporate messaging solutions failed to tackle the problem.Kafka was designed to provide the ingestion backbone for this type of use case. Kafka was ingesting over 1 billion events per day in 2011. LinkedIn recently recorded daily consumption rates of 1 trillion messages.
Apache Kafka and Pulsar are powerful stream processing platforms that have evolved and provided us with various services. Each has different abilities, and architecture is suitable for different cases.Read more about Kafka vs. Pulsar: Pick the Right one for your Business
What is the Architecture of Kafka?
A Kafka topic is a collection of messages that belong to a given category or feed name. Data is saved in Kafka in the form of topics. Data is written to subjects by producers, and consumers read data from these topics.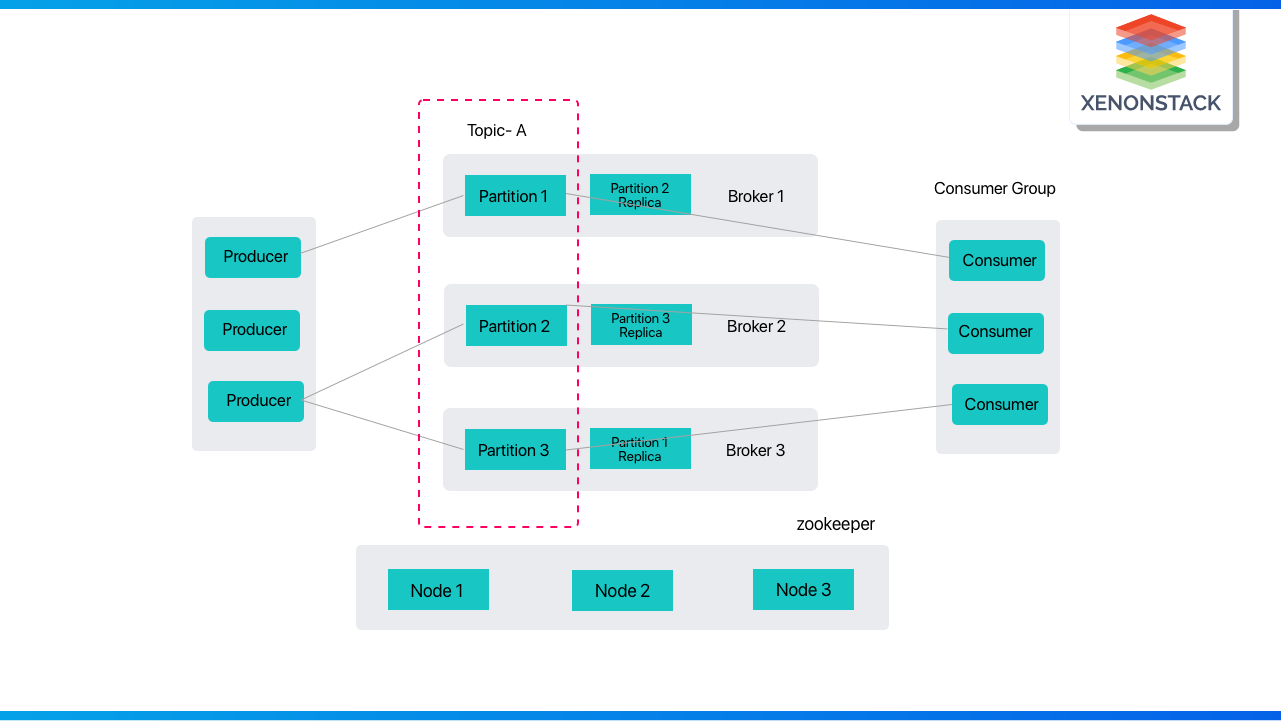
What is the role of the broker in Kafka?
A Kafka clusteris made up of one or more brokers or servers. A broker in Kafka acts as a container for numerous topics with various partitions. A unique integer ID identifies the Kafka cluster's brokers. A connection to any of the cluster's Kafka brokers implies connecting to the entire cluster. If a cluster has more than one broker, the brokers do not have all of the data connected with a single topic.
Consumers and consumer groups
Consumers read data from the Kafka cluster. When the consumer is prepared to receive the message, the data to be read by the consumer must be fetched from the broker. In Kafka, a consumer group collects consumers who all pull data from the same topic or range of topics.
Producer
Kafka producers send messages to one or more topics. Data is sent to the Kafka cluster. When a Kafka producer sends a message to Kafka, the broker receives it and appends it to one partition. Producers have the option of publishing messages to a certain division.
Significance of Partitioning and keys
In Kafka, topics are separated into a customizable number of sections known as partitions. Partitions enable several consumers to read data from the same subject simultaneously. Partitions are split in chronological sequence. The number of partitions is set when configuring a topic, although this number can be adjusted afterward.
A topic's partitions are spread among servers in the Kafka cluster. Each server in the cluster manages the data and requests partitions independently. Messages, coupled with a key, are forwarded to the broker. The key can be used to identify which partition a message will be routed to. All messages with the same key are routed to the same partition. The partition will be determined via a round-robin method if no key is supplied.
Offsets and Replicas
In Kafka, messages or records are allocated to a partition. Each record is given an offset to describe the location of the records inside the partition. The offset value associated with a record can be used to identify it inside its partition uniquely. A partition offset has no relevance outside of that partition. Because records are appended to the ends of partitions, older records will have smaller offset values.
In Kafka, replicas are similar to backups for partitions. A topic's partitions are distributed across numerous servers in a Kafka cluster. Replicas are copies of the partition. They are used to guarantee that no data is lost in the case of a breakdown or a scheduled shutdown.
Leaders and followers
Each partition in Kafka will always have one server acting as the partition's leader. The leader oversees all read and write operations for the partition. There might be zero or more followers for each division. The role of the follower is to repeat the leader's data. If the leader for a particular partition fails, one of the follower nodes can take over as the leader.
Data mesh creates a layer of connectivity that removes the complexities associated with connecting, managing, and supporting data access. It is a method of connecting data that is spread across multiple data silos.Know here to Adopt or not to Adopt Data Mesh?
The right number of Topics/Partitions in a Kafka cluster
In Kafka, a topic partition is the unit of parallelism. Writes to distinct partitions can be done in full parallel on both the producer and broker sides. As a result, costlier procedures like compression can take advantage of more hardware resources. On the consumer side, Kafka always sends all data from a single partition to a single consumer thread.

As a result, the consumer's degree of parallelism (within a consumer group) is limited by the number of partitions consumed. As a result, the higher the throughput achieved by a Kafka cluster with more partitions, the better, but having a huge number of partitions may also have several negative impacts, such as
-
A more significant number of partitions necessitates a more significant number of open file handles.
-
There's a chance that adding more partitions would increase unavailability.
-
End-to-end latency may increase when more partitions are added.
-
More partitions may necessitate additional memory on the client's part.
Throughput is used as a crude calculation for determining the number of partitions. You calculate the total amount of production (for example, x) and consumption (for example, y) that can be achieved on a single partition (for example, y). Let's suppose your throughput goal is t. Then you'll need a minimum of max(t/x, t/y) partitions. The amount of per-partition throughput that may be achieved on the producer is determined by batching size, compression codec, acknowledgment type, replication factor, and so on.
In general, a Kafka cluster with more partitions has greater throughput. However, the impact of having too many partitions in total or per broker on factors like availability and latency must be considered.
What is the Architecture of ZooKeeper?
Apache ZooKeeper is a free and open-source distributed coordination service that aids in the management of a large number of servers. It isn't easy to manage and coordinate in a distributed setting. ZooKeeper automates this process, allowing developers to develop software features rather than worrying about how it is distributed.
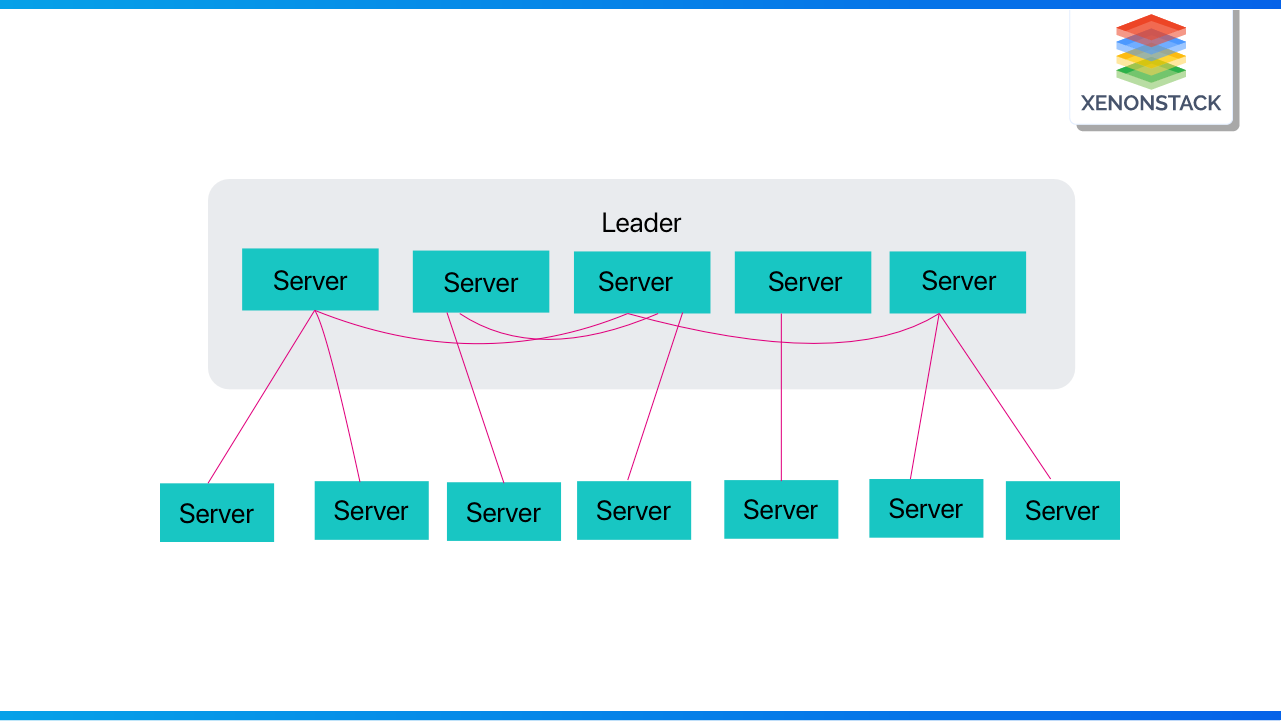
Client-Server architecture is used by Apache ZooKeeper, in which clients are “machine nodes” and servers are nodes.The relationship between the servers and their clients is depicted below. We can see that each client uses the client library and communicates with any of the ZooKeeper nodes in this way.
Server
When a client connects, the server sends an acknowledgment. If the connected server does not respond, the client will immediately transfer the message to another server.
Client
The client is a node in a distributed application cluster. It enables you to obtain information from a server. Every client sends a message to the server at regular intervals, which allows the server to determine whether or not the client is alive.
Leader
A server is designated as the Leader. It provides all of the information to the clients and an acknowledgment that the server is still operational. If any of the connected nodes fails, it will undertake automated recovery.
Follower
A follower is a server node that obeys the instructions of the leader. Client read requests are handled by the ZooKeeper server connected to the client. The ZooKeeper leader is in charge of handling client write requests.
Cluster/Ensemble
Ensemble or Cluster is a collection of ZooKeeper servers. When using Apache, you can use ZooKeeper infrastructure in cluster mode to keep the system working at its best.
Role of ZooKeeper in Kafka and Backup
ZooKeeper accomplishes its high availability and consistency by distributing data over multiple collections of nodes. ZooKeeper can execute instant failover migration if a node fails; for example, a leader node fails, a new one is selected in real-time via polling within an ensemble. If the initial node fails to answer, a client connected to the server might query a different node.
ZooKeeper is used in a minor but crucial coordinating function in newer versions of Kafka (>= 0.10.x). When new Kafka Brokersjoin the cluster, ZooKeeper is used to discover and connect to the other brokers. The cluster also uses ZooKeeper to pick the controller and track the controller epoch. Finally, and arguably most significantly, ZooKeeper saves the Kafka Broker topic partition mappings, which keep track of the data held on each broker. The data will still exist in the absence of these mappings, but it will not be accessible or copied.
How is the heartbeat managed for Kafka Brokers?
-
The mechanism by which Kafka can know that the business application with the consumer is still up and running or is not running is known as heartbeat.
-
This helps Kafka expel a non-active consumer from the group to distribute partitions to the remaining consumers. Still, this way of handling heartbeat had a problem, i.e., If your processing takes a longer time, you'll need to set a long timeout, which will result in a system that takes minutes to notice and recover from failure.
-
The Kafka broker controls this process by delivering network status updates stating that we're still alive and evicting each other based on timeouts. In older versions of Kafka, we had to call the poll method to trigger the heartbeat mechanism.
-
Kafka's newer versions use KIP-62 (a background thread) to handle this mechanism. So, instead of waiting for us to call a poll, this thread informs Kafka that everything is good.
-
So, suppose your entire process dies along with the heartbeat thread. In that case, Kafka will soon notice. It will no longer be influenced by the amount of time you spend processing data because the heartbeat is transmitted asynchronously and more frequently.
Conclusion
As a result, in this role of ZooKeeper in Kafka, we've seen that Kafka relies heavily on ZooKeeper to function effectively in a Kafka cluster. Finally, we discovered that all Kafka broker settings are saved in ZooKeeper nodes. Even Kafka consumers require Zookeeper to be aware of the most recent message consumed. We also looked into ZooKeeper server monitoring and ZooKeeper server hardware.
- Discover more about DevOps Best Practices for Data Engineers
- Explore more about Big Data Discovery using Blockchain



























