
Overview of Transfer Learning
Transfer learning, also known as academic forking, is a very effective technique used in machine learning where a model designed for one set of tasks acts as the basis for another model that focuses on a slightly different set of tasks. This methodology uses the prior knowledge and the previous patterns of solving a certain task to improve the performance of the new one, which makes it efficient in cases where labelled data is difficult to acquire. Due to this, transfer learning decreases the time and costs needed for training by enabling practitioners to attain better results with few samples. It adequately captures the issue of knowledge transfer where two different but related domains arise, allowing for better machine learning
Domain adaptation, which is a part of transfer learning, deals directly with the problem of domain shift, whereby a difference exists in the data distribution between the source and the target domain. Despite the same tasks, differences in data features such as picture quality, light conditions, or language differences tend to decrease the model’s performance. Such disparities are sought to be eliminated by domain adaptation methods to effectively transfer models from one domain to another. To overcome the issue of transferring knowledge from the source domain to the target domain, several approaches like adversarial training and statistical measures help in fine-tuning the models, which improve the model’s robustness as well as accuracy when deployed for real-world use cases.
Problem Statement
The top two considerations that transfer learning and domain adaptation focus on are the leading problems that transfer learning and domain adoption deal with:
Limited Data
-
Cost and Time: Obtaining large, labelled datasets requires significant time and expense, and these challenges are even more formidable in medical imaging, where specialist knowledge is needed for the labelling process.
-
Scarcity: Gathering properly enough labelled data is challenging in countless domains, especially in pursuing offending diseases or other explicit goals.
Domain Shift
-
Variability in Data: Many models cannot handle the new data set (target domain) because they were trained on a separate data set (source domain), the two of which may have different distributions.
-
Environmental Factors: The generality of the model could suffer from inconsistencies that arise due to variances in the illumination of images, as well as inconsistencies in people data.
Imbalanced Datasets
-
Class Distribution: Certain classes display greater samples while others provide few, so training data often gives poor results on minority groups.
-
Performance Bias: The potential exists for them to emphasize large classes, leading to inadequate comprehension of important information for prediction in other categories critical for fields such as fraud analysis and disease identification.
Understanding Transfer Learning
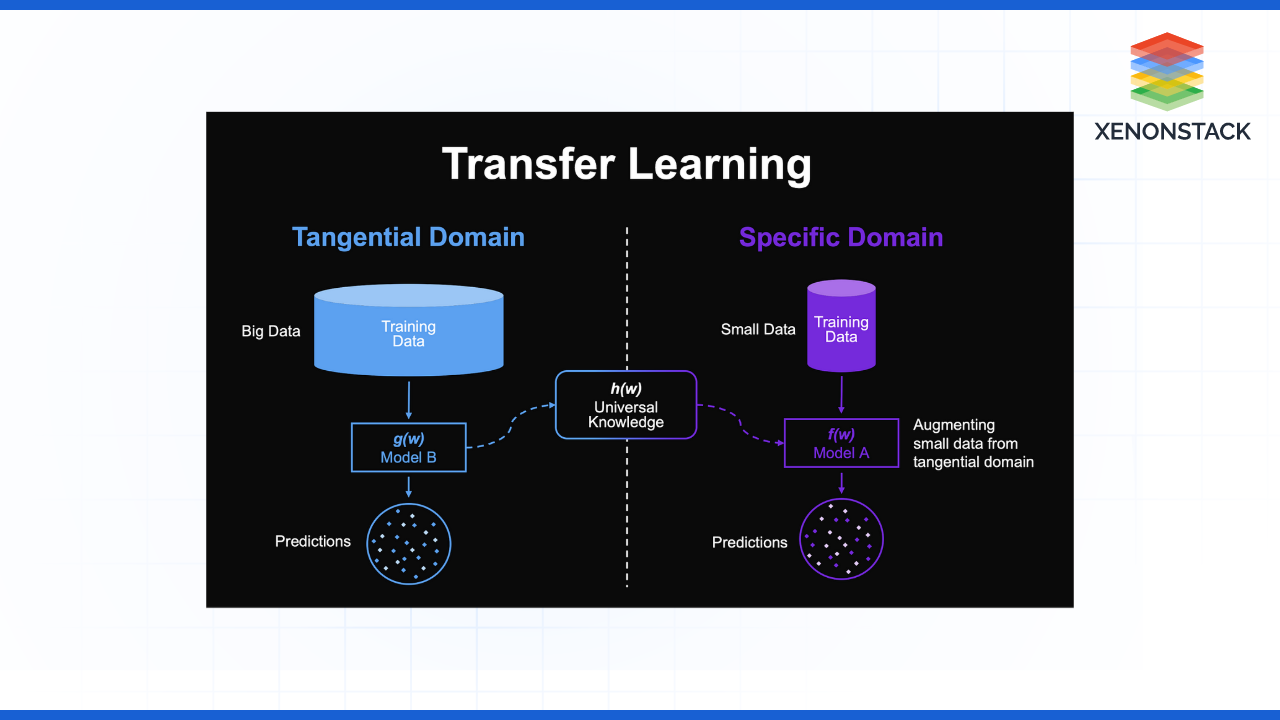
Fig – Transfer Learning high-level Solution View
Fine-tuning
-
Overview: Fine-tuning is one of the strategies widely used in transfer learning. This implies processing a data set with a large or diverse set of information sources and re-identifying the analyzed material for a specific task using labelled data from a target digital environment. This is especially useful when the amount of labelled data is smaller than the unlabeled data.
-
Process: The parameters of the pre-trained model that has gained very rich feature representations are fine-tuned on the target data. Usually, certain stages of the model are made “inactive,” meaning their weights will not be changed during the training period. This way, the model can keep what it has learned in other tasks to form new features while fine-tuning previously learned features to new data.
-
Benefits: Fine-tuning enhances a model's performance and averts overfitting because it encompasses knowledge from the source domain. Where the target domain data is limited or unbalanced, fine-tuning makes a dramatic difference.
Statistical Criteria
-
Techniques: Mean and standard deviation, most widely known as Maximum Mean Discrepancy (MMD) and H-divergence, are typical measures of domain divergence. These methods help ensure that the learned model performs well in the new data distributions.
-
Maximum Mean Discrepancy (MMD): MMD measures the divergence between the mean of the feature distribution in the source domain and that in the target domain. If the above-mentioned discrepancy is minimized during training, the model can distribute the two components alike so that it can generalize well with the target domain data.
-
H-divergence: This method assesses a classifier's ability to distinguish between samples from the source and target domains. When one tries to train the model with minimum H-divergence, the goal is to obtain representations that will be insensitive to domain changes.
Regularization Techniques
-
Concept: Regularization methods prevent cases of overfitting, wherein other important relations between the learned representations across domains the model is trained with are not captured.
-
Parameter Regularization: Unlike weight sharing, in which the model tries to share parameters between the source and target domains, parameter regularization helps the model adjust differently for the two domains but is related to each other. Such ways can be accomplished through L2 regularization or exponential weight regularization.
-
Purpose: It makes the learning of a model stronger as it only focuses on some related features while at the same time learning from a general knowledge base, which gives better results in the end.
Sample Re-weighting
-
Definition: Another type of re-weighting used is sample re-weighting, which is done by varying the weight associated with the training samples. This is particularly useful when it comes to problems like internal covariate shift.
-
Techniques: Batch normalization is usually applied to normalize the activations between layers to improve the training process and make it not sensitive to different batches. This minimises the impact of the different data distributions.
-
Effectiveness: The approach will enhance the model's generalizability on target notably by stabilizing the learning process and adjusting the sample weights to a new empirical distribution.
Techniques for Domain Adaptation
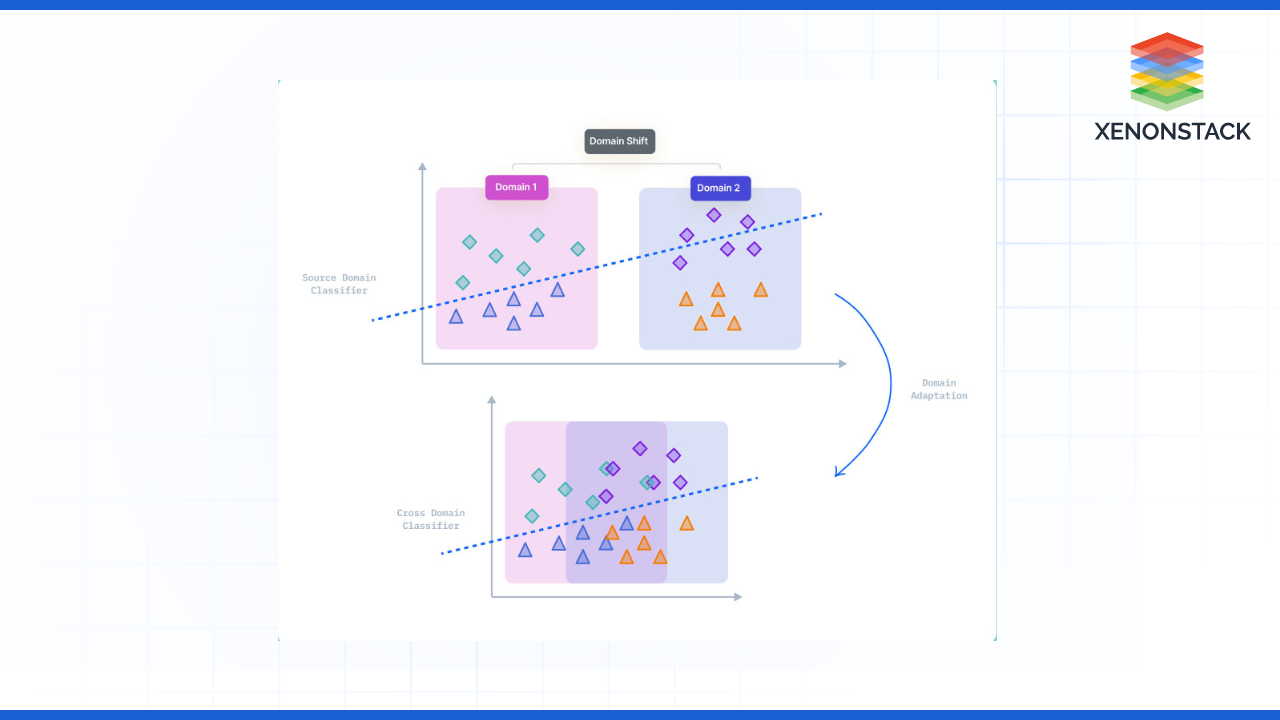
Fig – Domain Adaptation High-level View
Adversarial Learning
-
Introduction: The training process of a domain classifier that seeks to identify features common across domains is enhanced by using adversarial learning, domain adaptation, and GANs as a structure.
-
Mechanism: The purpose of the domain classifier within this model is to sort the provided sampling into either the target domain or the source domain, but the main model's feature generation diminishes the classifier's power in this regard. An important element is to apply data from an unrelated sector, known as domain confusion, in the training of the neural network to generate representations that can operate in yet a third sector.
-
Benefits: By applying adversarial learning to model adjustment, we improve our resilience to domain changes and our suitability for working with new data, thereby improving the effectiveness of the models in practical applications
Target Data Generation
-
Concept: Engineered approaches confirm generating a body of synthetic annotated data in the speciality area, resulting in dataset growth and normally obviating the substantial need for human annotations and labelling.
-
Example: We observe an application of GANs centred on image generation from the source domain and focused on the target domain within this context. These networks connect data pairs and sustain the connection from source to target samples by sharing a fraction of their weights.
-
Advantages: This technique enables the handling of more extensive data volumes, greatly improving performance in situations where data from the target domain is limited. It delivers functionality in resolving difficulties connected to the management of poor datasets.
Domain Classifiers
-
Role: The educational process combines domain classifiers to boost comprehension of the contrasts between source data and target data. They facilitate the strengthening of infrastructure and make their functions commonplace.
-
Implementation: During training, the domain classifier investigates whether the information on the condition is from the source or target domain. To lessen the domain classifier's rapid categorization of samples, we optimize the principal model, which then asks to identify independent features.
-
Impact: The improvement achieved in model performance across various applications, especially when limited target domain insights are available, results from the increased resilience supplied by domain classifiers to changing data distribution patterns.
Applying these solutions in conjunction reduces the principal difficulties of transfer learning and domain adaptation, allowing models to work in real cases characterized by data scarcity and variation.

Real-World Applications
Computer Vision
-
Image Classification: The term transfer learning has come to represent image classification tasks because models trained on extensive datasets like ImageNet have proved capable of performing well on focused tasks, particularly when data is inadequate.
-
Object Detection: The application of domain adaptation strategy within Domain Adaptive Faster R-CNN enhances results in different scenarios regarding object detection.
-
Image Segmentation: Using domain adaptation techniques for variations in pixel distribution led to promising results in segmentations for applications in medical imaging.
Computer Vision is revolutionizing industries by enabling machines to interpret visual data, automate processes, and enhance decision-making—transforming how we interact with the world. Explore here
Natural Language Processing
-
Machine Translation: Techniques for mixing advanced translation models by involving domain-specific losses together with general data.
-
Text Classification: The use of adversarial networks in enhancing classification tasks is justified, as we have learned that text characteristics vary from one domain to another.
Explore how Natural Language Processing bridges the communication gap between humans and machines, transforming vast amounts of unstructured data into actionable insights
Speech Recognition
-
Automatic Speech Recognition: The adaptation methods for domains boost recognition accuracy in environments where the signal-to-noise ratio is low by minimizing the difference between training conditions and those during operation.
Explore how Automatic Speech Recognition transforms spoken language into actionable insights, revolutionizing communication and productivity across various sectors
Time-Series Data Processing
-
Healthcare Monitoring: It also assists in analyzing multivariate time-series data to provide better patient monitoring frameworks using variational recurrent adversarial methods.
-
Driver Assistance Systems: This work suggests that learning features common to different datasets appeal to creating predictive models for driving manoeuvres.
Summary and Future
Due to the facilitation of domain adaptation and transfer learning in machine learning, models gain understanding and can be used on challenging and frequently complex problems. These methods are shown to be the most productive in situations where amassing extensive, annotated datasets is not possible, unsuitable, or too expensive and/or when the data distribution dynamics change over time or across different platforms.
The analysis of transfer learning and domain adaptation in handling issues related to limited data and shifting domains reveals that these two methodologies improve both the performance and accuracy of models across various application domains, including computer vision for image recognition and natural language processing for language comprehension. Optimism among researchers is high that these method developments will lead to forthcoming AI architectures that encompass better algorithms and models that are both quicker and more precise.
-
Learn more about Generative Adversarial Networks (GANs) for Image Synthesis
-
Explore more about Vision Transformers (ViTs)




