
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
What is a Data Fabric?
Data fabric is a dynamic approach to managing data. It's a sophisticated architecture that harmonizes data management standards and procedures across cloud, on-premises, and edge devices. A single environment with a combination of architecture and technologies makes handling dynamic, distributed, and heterogeneous data more accessible. Data visibility and insights, data access and management, data observability, data protection, and data security are just a few of the many benefits of a data fabric.
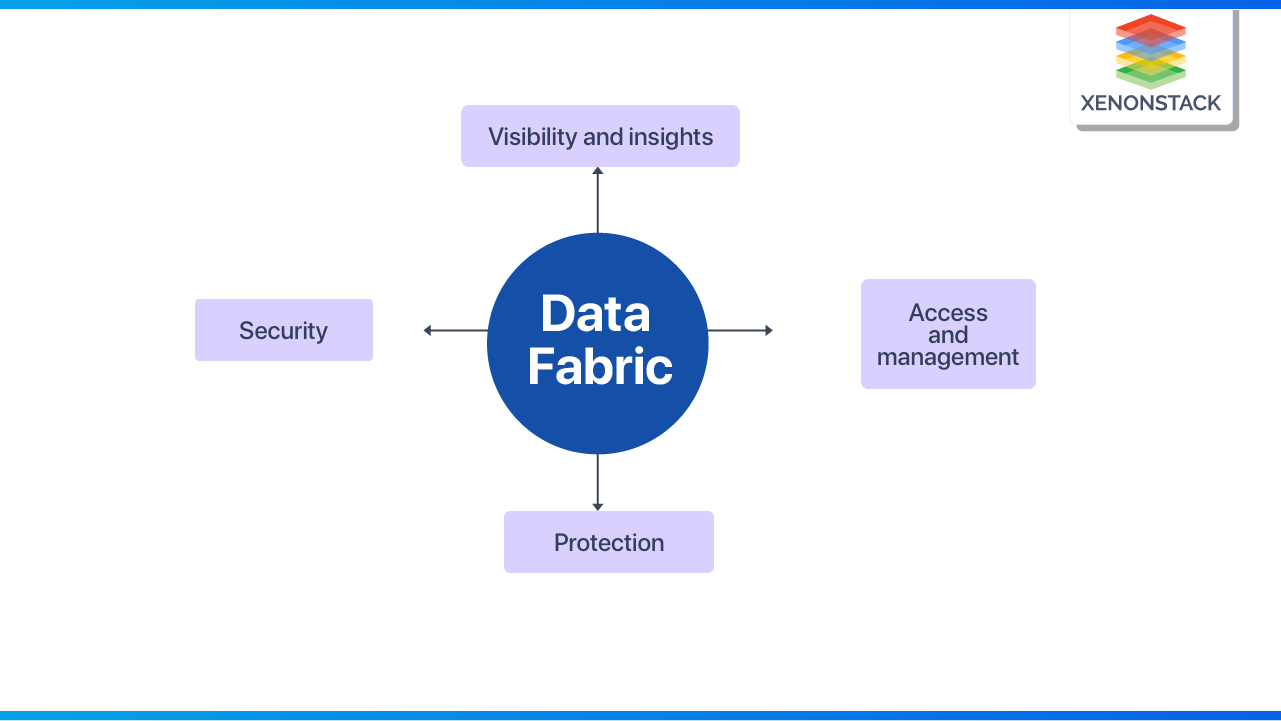
A data fabric boosts end-to-end performance, reduces costs, and makes infrastructure deployment and management more effortless.
Why Data Fabric is Important?
Companies are overwhelmed by the volume of available data sources or the difficulty of integrating them. We need a significant shift in the data exploration paradigm to identify a solution that addresses the causes rather than just the symptoms. Instead of pursuing the never-ending quest of achieving SLAs in increasingly complex ETL/ELTs, perhaps the Data Fabric platform could be responsible for speed, agility, and data unification.
By design, the entire ecosystem should incorporate new sources and collaborate with others. This would help with most analytics like performance, scalability, and scalability issues. Because each option is best suited for different conditions, judgments should be made after thorough thought and with the necessary understanding. Permanent data migration is not taken into account by data fabric. It leaves the data in the sources alone. As a result, we will be able to avoid more issues such as:
- Multiple flow dependencies; waiting for certain data to be processed before proceeding, resulting in additional latency.
- Lack of atomicity; when entangled flows occurred due to an intermediate step failure, cleaning up and re-running only the failed flows was a difficult task.
- Due to the design of the ETL/ELT process, there is a delay in the delivery of new data sources to the reports.
Data observability defines the health of data in the organization and mostly eliminates the data downtimes by appealing best practices of DevOps observability to data pipelines.Explore here How Data Observability Drives Data Analytics Platform?
How does Data Fabric work?
Consider two scenarios
- When the pilot is active and focused, drive the plane with full attention to the route. At that time, the airplane’s autopilot mode does no or minimal intervention.
- When the pilot is lazy and dizzy, he loses his focus. At that time, the airplane automatically switches to autopilot mode and does the necessary corrections.
This is how data fabric works. It initially acts as a passive observer of the data pipelines. In this way, it automates and helps leaders to work on innovations.
Now, let’s understand its architecture with the help of a diagram.
- Data Sources: From where the data is collected.
- Data catalog: It extracts the meta-data and stores the passive data in the knowledge graph.
- Knowledge Graph: Here, through analytics, the passive meta-data is converted to active meta-data.
- AI/ML algorithm applied on the active meta-data, which simplifies and automates data integration design.
- Dynamic data integration delivers the data into multiple delivery styles.
- Automation is applied to the data in data orchestration tools and sent to the consumers.
Data mesh creates a layer of connectivity that removes the complexities associated with connecting, managing, and supporting data access.Click to explore Adopt or not to Adopt Data Mesh? - A Crucial Question
Implementation of Data Fabric
The fundamentals of online transaction processing (OLTP) are the foundation of the data fabric.
Detailed information about each transaction is inserted, updated, and transferred to a database via online transactional processing.
The information is organized, cleansed, and stored in silos in a central location for later use.
At any point in the fabric, any data user has access to the raw data and generates different discoveries, allowing enterprises to develop, adapt, and improve by leveraging their data.
The following are requirements for a successful data fabric implementation:
- Application and services: This is where the data acquisition infrastructure is constructed.
This encompasses the creation of apps and graphical user interfaces. - Development and Integration of Ecosystems: Establishing the essential ecosystem for data collection, management, and storage. Customer data must be sent to the data manager and storage systems securely to avoid data loss.
- Security: All data gathered from various sources must be maintained with care.
- Storage Management: Data is kept in a way that is accessible and efficient, with the ability to scale as needed.
- Transport: Building the necessary infrastructure for data access from wherever in the organization's geographic regions.
- Endpoints: Creating software-defined infrastructure at storage and access points to enable real-time analytics.
Principles of Data Fabric
So far, Data Fabric appears to be a fantastic solution, but every solution has its drawbacks and stumbling blocks. The following are the essential principles and challenges to remember:
- Regardless of overall increases in data volume, the Data Fabric must scale in and out. Because the ecosystem is entirely responsible for the performance, data access may solely focus on business objectives.
- By design, Data Fabric must accommodate all access methods, data sources, and data kinds. It has multi-tenancy, which means that various users can move throughout the fabric without affecting others, and strong workloads can't consume all the resources.
- The Data Fabric must cover various geographical on-premise locations, cloud providers, SaaS apps, and edge locations with centralized management. The fabric's transactional integrity is necessary, so a well-thought-out master data replication plan is required to regulate all processes successfully. Later on, it's utilized to ensure that multi-location queries get consistent results.
- The logical access layer adds a layer of protection that can be controlled from a single location. Data Fabric can allow users' credentials to be passed across to the source systems, allowing access rights to be correctly reviewed.
Data catalogs work best with rigid models, but with the increasing complexity of data pipelines, complex unstructured data becomes an essential standard for understanding our data.Click to explore about Data Catalog with Data Discovery
Key pillars of Data fabric
All types of metadata must be collected and analyzed by the data fabric.
The core of a dynamic data fabric design is contextual information. A mechanism (such as a well-connected pool of information) should be in place to allow data fabric to recognize, connect, and analyze various types of metadata, including technical, business, operational, and social metadata.
Passive metadata must be converted to active metadata by the data fabric.
- Businesses must activate metadata to share data without friction. To do this, data fabric should: Analyze accessible information for critical metrics and statistics continuously, then design a graph model.
- Create a graphical representation of metadata that is easy to grasp, based on their unique and business-relevant relationships.
- Utilize important metadata metrics to enable AI/ML algorithms that learn over time and generate enhanced data management and integration predictions.
The data fabric must create and maintain knowledge graphs.
- Knowledge graphs empower data and analytics leaders to derive business value by enhancing data with semantics.
- The knowledge graph's semantic layer makes it more intuitive and straightforward to read, analyzing D&A leaders simple. It gives the data consumption and content graph more depth and significance, allowing AI/ML algorithms to utilize the data for analytics and other operational purposes.
- Data integration experts and data engineers can regularly employ integration standards and technologies to enable easy access to - and delivery from - a knowledge graph. D&A executives should take advantage of this; else, data fabric adoption could be hampered.
A robust data integration backbone is required for data fabric.
Data fabric should work with various data delivery methods (including, but not limited to, ETL, streaming, replication, messaging, and data virtualization or data microservices). It should accommodate a wide range of data consumers, including IT (for sophisticated integration needs) and business users (for self-service data preparation).
Benefits of Data Fabric
An actual data fabric meets five essential design principles:
- Maintaining Control: Maintain secure data control and governance regardless of where it is stored: on-premises, near the cloud, or in the cloud.
- Option: With the freedom to adapt, choose your cloud, application ecosystem, delivery methods, storage systems, and deployment strategies.
- Integration: Allow components at each layer of the architectural stack to work together as a single unit while still extracting the full value of each component.
- Access: Get data to where it's needed, when needed, and in a format that applications can understand.
- Reliability: Regardless of where data resides, manage it using standard tools and processes across many contexts.
A data strategy is frequently thought of as a technical exercise, but a modern and comprehensive data strategy is a plan that defines people, processes, and technology.Discover here 7 Key Elements of Data Strategy
Conclusion
Every day, we see organizations evolve quicker and faster, with the rate of innovation increasing all the time. This influences the rotation of new software and applications and data management and analytics because top-level organizations must be data-driven.
Data management and analytics approaches that have been used for years may find it challenging to keep up. We'll probably have to rethink how we approach this problem. The design and fundamental principles of Data Fabric solve the bulk of the existing and most critical issues that arise when creating and using DLs and DWHs. We can take advantage of the cloud platform's capabilities by using it. We can now design unlimited scalability and power solution by exploiting the cloud platform's capabilities. This brings the Data Fabric concept to life and positions it as the most promising future data management method.
- Explore more about Big Data Governance Tools, Benefits, and Best Practices
- Click to explore What is a Data Pipeline?
- Read more about Observability vs Monitoring


























