
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Why Composable Data Matters
As businesses increasingly rely on data to drive decisions, managing and extracting value from vast datasets has become a critical challenge. Converting raw data into actionable insights can be a complex task, often hindered by traditional methods. These methods are limited due to human capacity in processing and analyzing massive volumes of data. This is where the combination of Agentic AI and composable data analytics plays a transformative role.
By leveraging the power of Agentic AI, organizations can automate and intelligently manage their data, while composable data analytics allows the efficient processing and integration of different data sources and techniques, ultimately improving data-driven decision-making. In this blog, we will explore how the synergy between Agentic AI and composable data analytics is revolutionizing data analytics, addressing challenges, and offering solutions that impact industries like healthcare, finance, and cybersecurity.
Agentic AI represents an advanced form of Artificial Intelligence that possesses autonomous decision-making capabilities. Unlike traditional AI, which operates within predefined parameters, Agentic AI can learn and make decisions based on real-time data inputs. It doesn't just react; it takes proactive actions to drive outcomes. In the context of data analytics, Agentic AI can analyze, plan, and execute tasks with minimal human intervention, allowing organizations to achieve unprecedented efficiency and effectiveness in their data processing efforts.
What is a Composable Data and Analytics Framework?
The term "composable" implies that the platform allows different data sources and analytical techniques to be easily integrated and combined in various ways to support a wide range of use cases.
Composable data and analytics is a framework that leverages a microservices-based architecture and allows users to leverage existing assets to create their own analytics experience.
-
Using composable data and analytics, easily combine and reuse different data sources, analytical techniques, and tools to solve specific business problems or gain insights from data.
-
It provides flexibility and scalability by allowing data engineers and scientists to easily access, combine, and analyze data from multiple sources without requiring extensive data integration and modeling.
-
A composable data and analytics platform typically includes various tools and technologies, such as data integration, data warehousing, data governance, machine learning, and visualization.
The problem that existed in the industry before the introduction of composable data and analytics frameworks was the difficulty of integrating, manipulating, and analyzing large, complex datasets from multiple sources. It made it difficult for organizations to gain insights from their data and make data-driven decisions.
Composable data and analytics frameworks address this problem by providing a flexible and modular approach to data analysis, allowing organizations to easily combine and manipulate different data sources and analytical tools to gain insights and make decisions.
Key Components of Composable Data Framework
The critical elements of a composable data and analytics framework include the following:
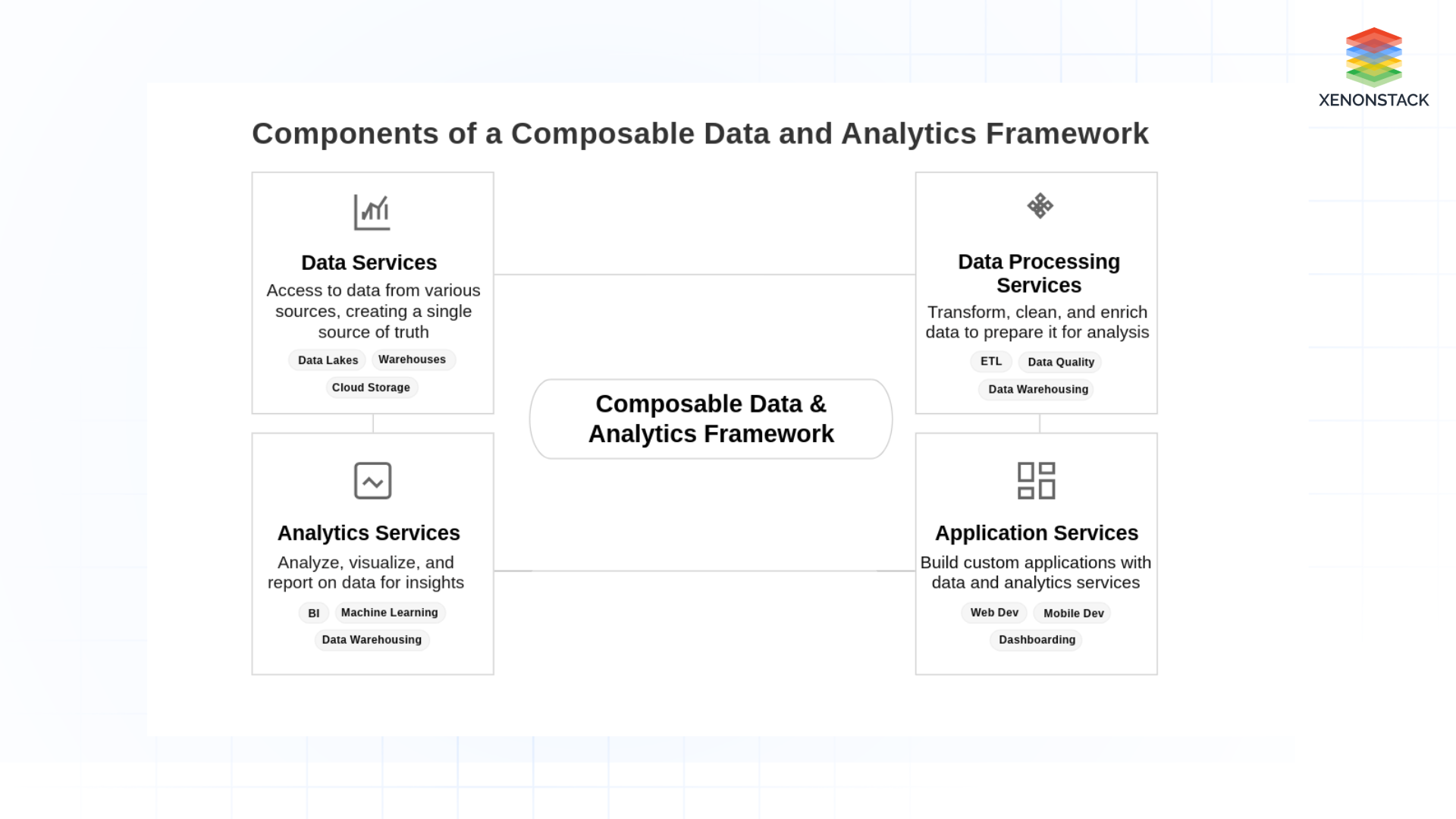 Fig 1: Composable Data and Analytics Framework Components
Fig 1: Composable Data and Analytics Framework Components-
Data Services: Services that provide access to data from various sources, such as data lakes, warehouses, and cloud-based data storage. These services enable the organization to create a single source of truth for data.
-
Data Processing Services: Services that enable data to be transformed, cleaned, and enriched to prepare it for analysis. These services use technologies such as data warehousing, ETL, and data quality tools.
-
Analytics Services: These Services enable data to be analyzed, visualized, and reported. These services use data warehousing, business intelligence, and machine learning technologies.
-
Application Services: Services that enable the organization to build custom applications that use data and analytics services to meet specific business needs. These services use the web and mobile development technologies, dashboarding, and visualization.

How Agentic AI Automates Data Preparation
A major obstacle in data analytics is data preparation and cleansing, which is often time-consuming and complex. Agentic AI simplifies this process through the following methods:
-
Data Quality Assessment: Agentic AI can automatically assess incoming data for anomalies, duplicates, and missing values, ensuring the data is of the highest quality.
-
Data Transformation: By utilizing machine learning techniques, Agentic AI transforms unstructured data into structured formats, making it more suitable for analysis.
-
Automated Cleansing: Through continuous learning, Agentic AI can autonomously identify and clean irregularities in the data, ensuring a more accurate dataset for analysis.
What is Composable Data Processing?
Composable data processing is a framework that enables modular, scalable, and efficient data ingestion and processing. It streamlines the complex process of handling large datasets, optimizing it with minimal complexity, latency, and cost. The core advantages of composable data processing include:
-
Efficiency: Minimizing unnecessary complexity in data processing.
-
Modularity: Allowing different teams to extend and modify data ingestion processes without disrupting the system.
-
Scalability: Enabling organizations to handle large data volumes effectively.
This approach allows organizations to scale their data engineering efforts while maintaining flexibility and maximizing reuse. It is critical for organizations needing to process vast amounts of data daily, such as in industries like marketing and healthcare.
Why Do We Need Composable Data Processing?
As data complexity increases, organizations are faced with the challenge of managing and processing terabytes of data daily. Without a modular, scalable approach like Composable Data Processing, these data operations would result in significant backlogs, hindering timely decision-making and operations. A case study from Adobe Experience Platform (AEP) illustrates the importance of composable data processing in overcoming such challenges.
By adopting Composable Data Processing, AEP can effectively manage vast datasets and transform them into actionable insights, improving the efficiency of targeted advertising and customer experience applications.
Real-World Impact of Agentic AI in Data Analytics
In healthcare, Agentic AI is being used to improve clinical and operational efficiencies. For example, in medical imaging, Agentic AI can analyze X-rays and MRIs with exceptional accuracy, enabling faster diagnosis and treatment. Additionally, Agentic AI can predict patient outcomes by continuously monitoring and analyzing data, allowing for timely interventions.
In cybersecurity, Agentic AI excels by detecting anomalies in network traffic, predicting potential threats, and taking immediate, autonomous actions to prevent breaches. It’s also instrumental in automating tasks like data cleaning, transformation, and analysis, providing faster and more accurate insights.
Agentic AI and Predictive Analysis
Agentic AI is essential in predictive analytics, enabling organizations to forecast future trends with high accuracy. Whether it's predicting market trends, analyzing financial data, or forecasting demand in industries like energy and transportation, it offers valuable tools such as:
-
Scenario Simulation: Simulating future scenarios to predict outcomes based on historical data.
-
Time-Series Forecasting: Using techniques like Recurrent Neural Networks (RNNs) to forecast time-series data in fields such as stock trading and weather prediction.
Overcoming Cognitive Bottlenecks in Data Analysis
Traditional data analysis is often hindered by human limitations, including biases and slow processing speeds. Agentic AI overcomes these bottlenecks by analyzing data at a much faster rate and without cognitive biases, enabling organizations to gain insights from vast datasets in real time.
Use Cases for Composable Data & Analytics
There are many use cases for composable data and analytics; some examples are:
 Fig 2: Composable Data and Analytics Framework Use Cases
Fig 2: Composable Data and Analytics Framework Use Cases-
Social Media Analytics: Combining text data from social media with demographic data to understand customer sentiment and preferences.
-
Predictive Maintenance: Combining sensor data from industrial equipment with historical maintenance records to predict when equipment will likely fail and proactively schedule maintenance.
-
Fraud Detection: Combining transaction data with external data sources (IP addresses and social media profiles) to detect fraudulent activity.
-
Healthcare Analytics: Combining electronic health records with lab results, claims, and genomics data improves patient outcomes and reduces costs.
-
Risk Management: Combining financial data with market and news data to identify and manage risks in financial markets.
Best Practices for Composable Analytics Framework
By following these best practices, organizations can implement a composable data and analytics framework that is flexible, modular, and reusable and can help to improve data-driven decision-making and drive business growth.
-
Start with an Apparent Business Problem: Understand the problem you are trying to solve and ensure that the data and analytics services you build align with that problem.
-
Centralise Data Storage: Create a centralized data lake or data warehouse to use as a single source of truth for the organization.
-
Use Data Standards and Governance: Establish data standards and governance processes to ensure data is accurate, consistent, and compliant with regulations.
-
Use Modular and Reusable Services: Design data and analytics services to be modular and reusable so they can be composed, configured, and reused to meet different business needs.
-
Prioritise Scalability: Plan for scalability using cloud-based data storage and analytics solutions that adapt to changing data volumes.
-
Invest in Data and Analytics Skills: Invest in training and development programs to build the necessary skills within the organization.
-
Implement Security and Privacy Controls: Implement security and privacy controls to protect sensitive data and comply with regulations.
-
Monitor and Measure Performance: Monitor the composable data and analytics framework's performance and measure the business's impact.
-
Continuously Iterate and Improve: Continuously iterate and improve the composable data and analytics framework as the organization's needs evolve.
Future of Composable Data and Analytics Framework
The future of composable data analytics combined with Agentic AI will focus on:
Scalability
Enabling organizations to manage massive datasets efficiently.
Real-Time Processing
Accelerating data ingestion, transformation, and analysis for instant decision-making.
Advanced Machine Learning Integration
Enhancing predictive analytics and automation capabilities.
AI-Driven Automation
Reducing manual intervention in data preparation, cleansing, and governance.
Modular & Flexible Architectures
Allowing businesses to build customized, adaptive analytics ecosystems.
Improved Data Governance & Security
Ensuring compliance, access control, and privacy protection.
Industry-Specific Applications
Expanding use cases in healthcare, finance, cybersecurity, and IoT.
Why Composable Data is Essential for Business Growth
A composable data and analytics framework is a powerful tool that enables organizations to extract valuable insights from vast datasets, driving better decision-making. By providing a flexible and easy-to-use platform for data integration, transformation, and visualization, it empowers businesses to rapidly combine and analyze data from multiple sources.
The integration of Agentic AI enhances this framework by automating repetitive data tasks, reducing human error, and accelerating insight generation. Meanwhile, composable data processing ensures that data workflows are optimized for scalability and efficiency.
With this approach, organizations can harness their data effectively, drive innovation, and maintain a competitive edge in an increasingly data-driven world.




























