On-premise AI and Data Platform
Building a Private Cloud Compute engine for data privacy and security for Generative AI Applications and Multi-Agent systems involves composite AI principles with Decision Intelligence. AI Infrastructure Stack needs Model Training and Inference to scale batch and real-time data.
Main Components for Building Compound AI Systems for AI Agents and Agentic AI
- Integration ( Intelligent ETL, Data Pipelines and Workflows)
- AI Model Security Supply Chain
- Governance (Data Access Management)
- Storage ( I/O Processes + Cost per operations)
- ModelOps - ML/DL Models and Decision Models
- MLOps and LLMOps
- AI Quality
- AI Assurance
- Data Protection and Backup
Importance of Private Cloud Solutions

Enhanced Security and Privacy
Private clouds offer isolated infrastructure, reducing unauthorized access risks. This makes them ideal for industries like finance and healthcare, where sensitive data management is critical
Greater Control and Customization
Private cloud solutions grant organizations full control over resources, enabling custom configurations for optimized operations and better efficiency than public cloud alternatives
Importance of Kubernetes in AI Infrastructure
Kubernetes has emerged as the standard for managing containerized architectures at scale, making it an essential tool for organizations implementing AI solutions. It provides clarity by defining a standardized pipeline and toolkit for orchestrating containers, which is vital for deploying scalable AI models in production environments.
The Requirement for Versatility and Seamless Integration in Enterprise AI Platforms
The versatility in developing AI models and their architectures presents scaling challenges, as different teams often adopt varying approaches. This lack of interoperability leads to complications, with numerous libraries and versions being used in model development. To address these challenges, there is a pressing need for a standardized approach that is:
-
Framework Agnostic: Capable of supporting multiple AI frameworks without being tied to any specific one.
-
Language Agnostic: Flexible enough to accommodate various programming languages, allowing teams to work in their preferred environments.
-
Infrastructure Agnostic: Can function across different deployment environments, whether on-premises, in the cloud, or in hybrid setups.
-
Library Agnostic: Designed to integrate seamlessly with various libraries, ensuring organizations can leverage existing tools without being restricted by specific technologies.

Enterprise AI Infrastructure Platform Capabilities
The capabilities of the enterprise AI infrastructure platform are described below:
Software Engineering Practices for AI
Advanced machine learning practices increasingly integrate software engineering disciplines like Test-Driven Development (TDD), continuous integration, rollback and recovery, and change control. Simply developing a Jupyter notebook and handing it off to a team for operationalization is no longer sufficient. Enterprise AI strategies should adopt end-to-end DevOps practices similar to those in high-grade engineering organizations, supporting various models and data types while remaining flexible for innovations in machine learning and deep learning.
Challenges of Storage and Disk/IO
Data parallel computing workloads require parallel storage. The primary challenges in running Deep Learning Models—whether in the cloud or on-premises—include bottlenecks from the edge to the core to the cloud, such as:
- Slow data ingestion
- Outdated on-premises technology
- Virtualized storage bottlenecks in the cloud
Even when deploying deep learning in the cloud for agility, these bottlenecks can persist. Configuring Kubernetes for co-location can help mitigate these issues, providing the flexibility needed for effective deep-learning pipelines.
Health Checks & Resiliency
Kubernetes offers features that enhance application resiliency by managing failovers, ensuring that on-prem environments can achieve cloud-like resilience.
Framework Interoperability
To facilitate model framework, language, and library agnosticism, Facebook and Microsoft initiated a community project supported by AWS. This interoperability allows a single machine-learning application to deploy across various platforms. Frameworks like ONNX and MLeap provide standardized formats for model artefacts, optimizing them for efficient performance on serverless platforms built on Kubernetes.

Implementation Steps of AI Model On-premises
Infrastructure Setup
Setting up the infrastructure for an on-premises AI and data platform involves several critical steps:
-
Assess Requirements: Evaluate your organization's specific needs, including computational power, storage capacity, and network requirements.
-
Choose Hardware: Select appropriate servers, storage solutions, and networking equipment to support the expected workload and ensure high availability.
-
Establish Networking: Configure a robust network architecture to facilitate communication between different components of the AI platform while ensuring security protocols are in place.
-
Install Software: Deploy necessary software components, including operating systems, container orchestration tools (like Kubernetes), and AI frameworks that will be utilized for model development and deployment.
-
Security Measures: Implement security protocols such as firewalls, access controls, and encryption to protect data and infrastructure from unauthorized access.
Deploying AI Models
Deploying AI models into a production environment involves several key steps:
-
Model Preparation: Train and validate the AI model using appropriate datasets. Optimize the model for performance and accuracy, then serialize it for deployment.
-
Choose Deployment Environment: Based on your organization’s needs for scalability, cost, and security, decide whether to deploy on-premises or in a hybrid cloud environment.
-
Containerization: Package the model and its dependencies into a container (e.g., using Docker). This ensures consistency across different environments and simplifies deployment.
-
Deploy the Containerized Model: Set up the necessary infrastructure in your chosen environment (e.g., Kubernetes cluster) to host the containerized model. Configure networking and security settings to ensure proper access to resources.
-
Monitor and Maintain: After deployment, continuously monitor the model's performance to ensure it meets operational standards. Implement logging and alerting mechanisms to track usage and identify any issues promptly.
Build Your Own DataOps Platform using Kubernetes

With Enterprises becoming jealous of data and security paramount, Becoming an AI-powered enterprise requires a custom-made Data Platform. Every enterprise has its natural data and needs. The number of teams involved makes it challenging to have security and compliance in place while, at the same time, giving organizations the freedom to run experiments and discover data. An Enterprise Data Strategy should elaborate on how Data will be securely shared across various teams.
Big Data Applications are evolving and have become more friendly to Kubernetes. With the rise of Kubernetes Operators, running complex stateful workloads on Kubernetes has become a much simpler task. Data Governance is required, and how it benefits them and an organization.
.jpg?width=1920&height=1080&name=Artboard%201%20(1).jpg)
Data Lineage for AI Platform
Capturing all events across the data and AI platform comprises events from infrastructure to application. The Data Lineage Service should be capable of capturing events from ETL Jobs, Querying Engines, and Data Processing Jobs. There should also be Data Lineage as a Service, which can be integrated by any other services where there is a need to incorporate Data Lineage. ELK Stack and Prometheus can provide Lineage for the Kubernetes Cluster and the Workloads Happening on top of it.
Data Catalog with Version Control
With MultiCloud and Cloud Bursting in Mind, The Data Stored should have version control. The version control for data should be as reasonable as the version control for Software code. The Data Version Control should be built on top of Object Storage, which can be integrated with Existing Services. Minio is a service that can be combined with S3 and provide the same APIs. For machine learning model data, DVC allows the storage and versioning of source data files, ML models, directories, and intermediate results with Git without checking the file contents in Git. Meta Cat should be integrated with the Data on Premises and External Sources.
A platform to define data collection layer to collect metrics stats of clusters, pipelines, applications running on it using REST API, Agent-based collection using SNMP protocols. Taken From Article, AIOps for Monitoring Kubernetes and Serverless
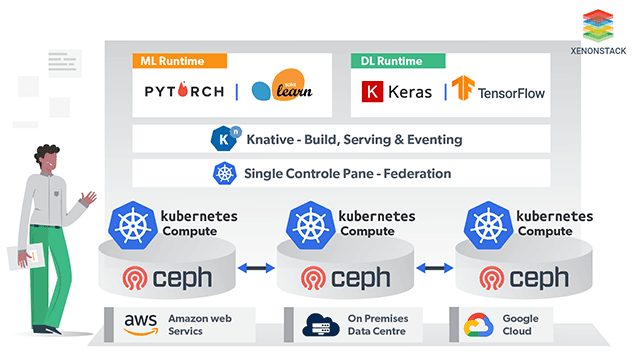
Multi-Cloud AI Infrastructure
This infrastructure should meet the following high-level infrastructure requirements -
-
Massive computing power for faster model training
-
High-performance storage for managing large datasets
-
Independent scaling of compute and storage resources
-
Handling diverse data traffic efficiently
-
Cost optimization to manage AI workloads effectively
Vendor Independence with Kubernetes
Utilizing Kubernetes for your Data Science Stack allows for a "Lift and Shift" approach to multiple cloud vendors, preventing vendor lock-in for future AI projects. This approach helps identify which cloud provider can run models more efficiently in terms of cost and performance.
Federated Kubernetes on Multi-Cloud
-
Models as Cloud Native Containers
Microservices, in general, are very beneficial when we have a complex stack with various business domain workloads running and talking to each other in a Service Mesh. However, Microservices suit Models Development and Operations Lifecycle excellently, with immense benefits.
-
Portability
With the use of Kubernetes, the pain of configuration management gets easy. Once the ML System is containerized, The infrastructure can be written as a code that can run on Kubernetes. Helm can be used to create Curated Applications and Version Controlled Infrastructure Code.
-
Agile Training at Scale
Kubernetes provides large-scale Agile training methods. Training jobs run as Containers, which can be scheduled on various Node types with GPU acceleration. Kubernetes can manage the scheduling of such workloads.
-
Experimentation
The dynamicity of Artificial Intelligence requires a lot of research. If the cost of running experiments is too high, the development lags. Running Kubernetes on commodity hardware on-premise helps run very low-cost operations.
Cloud Bursting for AI Platform
-
Cloud Bursting is a model for the application, but it's very relevant to AI workloads, which require a lot of Experimentation. In Cloud Bursting, the workload deployed on an On-Premises Data Center scales into a Cloud whenever there is a spike. Kubernetes with Federation can be set up to implement Cloud Bursting, and the AI Workloads shall be containerized in a cloud-agnostic architecture. The lift and shift from On-Premises can be triggered based on custom policies, depending on Cost or Performance.
Leverage your On-Prem for Experimentation
-
Customized Hardware - It is essential for running production-level Deep Learning and Machine Learning systems. Using virtualized storage or computing can lead to performance degradation, causing critical anomalies to be missed. With Kubernetes on-premises, enterprises can maintain high performance without sacrificing functionality, utilizing tailor-made hardware to support specific workloads.
Serverless For AI Platform on Kubernetes using Knative
- Automating the Pipeline
KNative or Kubernetes aims to automate all the complicated parts of the pipeline, such as the build, training, and deployment. It is an end-to-end framework for - Promoting the Eventing Ecosystem in Build Pipeline. Knative's eventing is the framework that pulls external events from various sources such as GitHub, GCP PubSub, and Kubernetes Events. Once the events are pulled, they are dispatched to event sinks. A commonly used sink is a Knative Service, an internal endpoint running HTTP(S) services hosted by a serving function.
- KNative currently supports the following as Data sources for its eventing -
AWS SQS
Cron Job
GCP PubSub
GitHub
GitLab
Google Cloud Scheduler
Google Cloud Storage
Kubernetes - Using Functions to Deploy Models
Functions are useful for dealing with independent events without maintaining a complex unified infrastructure. This allows you to focus on a single task that can be executed/scaled automatically and independently. Knative can be used to deploy simple models. The PubSub eventing source can use APIs to pull events periodically, post them to an event sink, and delete them.
Artificial Intelligence for Cyber Security is the new wave in Security. Click to explore about, Artificial Intelligence in Cyber Security
AI Assembly Lines with KNative
The pipeline and workflow for models have three main components. With the help of Kubernetes, all three can be achieved. KNative supports a full assembly line from Build to Deploy, Embracing current CI Tools and making them Cloud and Framework-Agnostic. It also routes and manages traffic with blue/green or canary deployments and binds running services to eventing ecosystems.
-
Model Building - Model development is part of this stage. Data scientists must be free to choose their workbench for Building the Model. With Kubernetes, provisioning workbenches for a data scientist is possible. Workbenches like Jupyter, Zeppelin, or RStudio can be provided to data scientists who install them on the Kubernetes Cluster rather than a laptop. This will help with ad hoc experimentation much faster and support GPU acceleration during model building.
-
Model Training - Model Training is a crucial and time-consuming stage in a project. With the help of Kubernetes, frameworks like Tensorflow provide significant support to run distributed training jobs such as containers, preventing time wastage and ensuring fast training. Online Training shall also be supported in the architecture much more efficiently.
-
Model Serving - In Terms of Serving the model, With the Help of Kubernetes, The following essential features can be introduced to ML/DL Serving -Logging, Distributed Tracing, Rate Limiting, Canary Updates
GitOps for ML and DL
GitOps Flow is Kubernetes-friendly for Continuously Deploying Microservices. Regarding Machine Learning, the same GitOps Flow can provide Model Versioning. Models are stored as Docker images in an image registry. The image registry has tagged images of every code change and checkpoint. The image registry acts as an artefact repository with all the Docker images version-controlled. The Models can be version-controlled similarly with the help of the GitOps approach in development.
Emerging Technologies to WatchThe on-premises AI platform landscape is rapidly evolving, driven by several emerging technologies:
- Generative AI: This technology excels in creating new content across various domains, enhancing personalization and automation. By leveraging large language models (LLMs), organizations can generate tailored outputs, from marketing materials to complex problem-solving solutions.
- Explainable AI (XAI): As AI systems become integral to decision-making, XAI focuses on making AI decisions transparent and understandable. This fosters trust among users and ensures compliance with regulatory standards.
- Integration with IoT: The convergence of AI with Internet of Things (IoT) devices facilitates real-time data processing and analytics, allowing organizations to respond quickly to changing conditions and optimize their operations.
- Blockchain Technology: This technology enhances the security and transparency of AI applications, particularly in finance and supply chain management, ensuring data integrity and traceability.
Moving Towards NoOps with the help of AIOps and Cognitive Ops
To achieve NoOps, AIOps can help to achieve the following goals -
-
Reduced Effort - Intelligent discovery of potential issues by cognitive solutions minimizes the effort and time required by IT to make basic predictions.
-
Reactive System - With access to predictive data on demand, Infrastructure Engineers can quickly determine the best course of action before serious network or hardware consequences occur.
-
Proactive Steps - Access to the end-user experience and underlying issue data helps achieve the “Holy Grail” of dynamic IT: Problems are solved before they impact the end-user.
-
NoOps - The next step beyond technology outcomes is to assess the business impact of networking and hardware failures. This solidifies technology's place in the minds of decision-makers and provides them with relevant, actionable data to inform ongoing strategy.

A Holistic Strategy
Containerization and Microservices architecture are essential pieces in the Artificial Intelligence workflow, from the rapid development of models to serving models in production. Kubernetes is a great solution for this job by solving many challenges that a data science guy should not worry about. It has the much-needed abstraction layers, removing tedious and repetitive configuration and infrastructure tasks.
-
Explore more about Healthcare Documentation with Generative AI
-
Learn more about Marketing Campaigns with Generative AI