
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Overview
In the rapidly changing context of the modern world, we can no longer speak only of verbal and even only of verbal and sound communication; more and more actively involved in its visual and graphic components. Since it emerged as a dominant form of writing 2.0, the need for sophisticated text and image understanding systems that can actively interpret, interact and communicate with images has similarly risen. Image chat and visual dialog systems are a much bigger step in that direction of being able to understand and create dialogues from Images, among other things, while introducing Natural Language Processing to Computer Vision.
In this highly extensive blog post, we will explore the history, need, innovation, issues, and real-world application of image chat and visual dialogue systems about social communication in today’s visually driven global society.
History of Image Chat and Visual Dialog Systems
Figure 1: Venn diagram illustrating the interconnections
Early Beginnings
The history of image chat and visual dialogue systems could or may be dated back to the mid-20th century, parallel to the birth of the major concepts of AI. The decades-old work done in natural language processing can be said to have been the basis of the development of conversational agents; in particular, Joseph Weizenbaum created ELIZA in 1966. However, these early systems were more of the traditional automated information systems, which only supported text-based interaction and did not contain any figure or image; this left a huge gap in image communication.
The Convergence of NLP and CV
NLP and computer vision are two scientific domains with distinct similarities, and just before the beginning of the twenty-first century, a new phase can be seen in the development of these disciplines. The deep learning technologies that stemmed from the early 2010s were a breakthrough in both NLP and CV and paved the way for good understanding and generating photos themselves. This led to the development of what is now known as visual dialog systems, with many researchers looking into how best to integrate the two technologies.
The first major development in this direction was the image captioning systems that appeared around the beginning of the mid-2010s. Such systems could produce descriptions in natural language, even for images, providing a crude ontological sense of multimedia content. There is a specific emphasis on how this innovation created the possibility for more complex exchanges, even with images being used.
The next major development happened in 2015 when Visual Question Answering, or VQA was introduced as one of the most important tasks. In 2016, the VQA systems provided many features to machines that allowed them to answer questions about images, which can result in machines being created to effectively dialog with customers concerning the content of pictures. For example, a VQA system can identify an image of a beach where it can answer questions like: “The weather in the image?” or “Are there people on the beach?”
Visual dialog systems: A new approach
The idea of visual dialog systems was introduced in 2018 as part of the foundation of the Visual Dialog Challenge at CVPR. This challenge sought to build models that would create meaningful conversations about an image while always referring to that image. Scientists tried to develop systems that could answer questions concerning images and be aware of the context throughout the conversation, and because of this, this line of work was progressing in this direction.
Need for Image Chat and Visual Dialog Systems

Figure 2: Output of a Visual Dialog System
Enhancing User Engagement
Since more and more internet sites, such as social networks, messaging apps, and various online communities, develop into increasingly connected images, the desire to share text-written messages sinks. In contrast, the desire to share images rises. Image chat systems contribute to interaction richness as they allow the incorporation of image transmission into interaction. Businesses, including e-commerce, can illustrate this since visual content plays a major role in influencing consumer activities. Consumers are more comfortable with products when they can communicate with interfaces for self-service with natural language-powered chat.
Accessibility and Inclusivity
Visual dialog systems also have great importance in improving the accessibility for people with differently abled systems. For instance, visually impaired users will find it useful to interact with systems that provide descriptions of images and engage the user in a dialogue regarding the visuals. Such systems enhance digital engagement, thus becoming significant enablers, especially in breaking barriers to communication and even enabling other users to acquire information they might otherwise not be able to find on their own. It would also make a lot of difference if these systems were developed to be most accessible to as many people as possible.
Personalized Interactions
Personalization and user satisfaction are always considered, and image chat systems can iterate the specific needs of the users. These systems can identify products and capture user interests and participation through the qualitative analysis of user-shared images and videos, deliver valuable responses and even construct tailor-made experiences for specific users. For instance, the user posts an image of an outfit they want to wear, and the system finds similar clothes based on colour, fashion and trends.
AI-based Video Analytics's primary goal is to detect temporal and spatial events in videos automatically. Click to explore our, AI-based Video Analytics
Advancements Over Time
Deep Learning Techniques
Recent approaches to deep learning have had a significant role in improving the module of image chat and visual dialog systems. The use of convolutional neural networks CNNs has led to the extraction of significant features in images to be understood. On the other hand, Recurrent Neural Networks (RNNs) have enhanced the capability to handle Sequential data although this has a significant value in developing string-based response patterns of the conversation.
Transformer Models
BERT and GPT, or Bidirectional Encoder Representations from Transformers and Generative Pre-trained Transformer, respectively, are a few recently added models in the field of NLP and Visual dialogue systems. The mentioned models are also great at considering context, which is helpful when trying to keep conversations connected in the context of visual dialog systems. These models have been extended for multiple modal inputs so that they can handle both image and text input at the same time. Such integration helps to involve more variety of interactions because it is possible to judge the user’s intent based on a picture and text.
Pre-trained Models and Transfer Learning
Most image chat systems have been developed with the help of pre-trained models, so the time required to create such systems has been reduced. Such models may be fine-tuned using transfer learning by researchers for a particular task, making it easier to implement models than to train them from scratch. This has facilitated increased capabilities for text-to-visual learning and converse as researchers create their real applications with the help of building upon the pre-learned concepts within these pre-trained models.
Dataset Creation
Another crucial factor has been the development of massive datasets for visual dialog applications to gain further growth in the research area. Some of the datasets available today include the Visual Dialog dataset, the COCO, which stands for Common Objects in Context, and many more, which have availed themselves of the necessary tools to enable researchers to adequately train and test their models. Such datasets entail images and relevant questions and answers so the systems can learn from practical interactions and cases.
Issues and Challenges
Uncertainty and Density of Visuality
It is a vocal issue for image chat and visual dialog generation since visual content is often ambiguous and complex. Sens, meaning is always a multi-faceted concept, and if interpretational cues are not understood, the responses generated will also be wrong. For instance, when asking about a picture of a dog, the questions depending on the user's vision may be different - what breed it is, how old it is, and what state it is in. For the system to deliver these interactions, it must be able to detect these differences.
Contextual Understanding
Another difficulty is keeping the context of the conversation during an interaction. Past questions might ask for a certain feature from object A, while the current question might ask for a feature from object B; a visual dialog system must, therefore, capture this history. This considers mechanisms with high memory usage and the ability to follow a conversational thread, which is expensive to compute. If the user goes back to an early component of the dialogue, the system needs to return to prior exchanges of the conversation. 
Limitations of Training Data
The study of training data shows that the quality and variety of the training data help determine the performance of the visual dialog systems. Several existing data sets will likely be skewed or under-sampled, resulting in poor-performing models. A key point is that for these systems to be capable of interpreting and operating with an extensive and convergent repertoire of content for a given visual genre, there is a need to have ample and quality datasets. That is why it is crucial when there is an interest in cultural interpretation of the pictures, as they may be perceived differently by different cultures.
Real-time Processing
For image chat systems, timeliness is a key parameter because the ability to handle images and generate replies on the fly is essential to guaranteeing a positive user experience. However, rich media content and participation in a conversation certainly place high loads on computational capacity and can lead to latency problems. Overcoming these performance issues is critical in designing a good user experience. Consequently, users expect fast replies to their messages, which, if unsatisfactory or delayed, can cause people to leave.
Overcoming Challenges
-
Improved Training Methodologies - Due to these two points, researchers are moving towards better training methods. Data quantization, adversarial training, and few-shot learning techniques are also useful to enhance robust representations of associated visual contents and contexts. Data generation, for example, can generate new training images like the existing images in the training set, thereby improving the diversity of the training data set and obtaining it without incurring the costs of gathering more data.
-
Advanced Memory Processes - Retaining contextual information is also important, and improving memory practices in visual dialog systems may help with this issue. This makes it possible for models to memorize previous exchanges and thus make more reasonable interactions without restarting the conversation. It lets the model decide what part of the conversation history is important and incorporate that into its context.
-
Diverse and Inclusive Datasets - Diverse and Inclusive Datasets embrace all genders, ethnicities, ages, and more in a place. Collecting a variety of representative datasets is mandatory to eliminate the problems associated with training data. Data scientists are also continuing to work to generate datasets that are more diverse in terms of demography, culture, and context. Working around such stakeholders, Sies would enable these datasets to be complete and capture real-life problems. At the same time, using user feedback directly during the training process allows for an understanding of different views and increases the chances of an appropriate response generation.
-
Optimized Processing Techniques - To overcome real-time processing problems, the current trends are examined for optimized processing. Methods like model pruning, quantization, and distillation can be used effectively to slice the computational load of visual dialogue systems, making the response time better without deteriorating the system's efficiency. One such simplification is Model pruning, which cuts out unneeded parameters in their structure for neural networks, making the structure much more efficient.
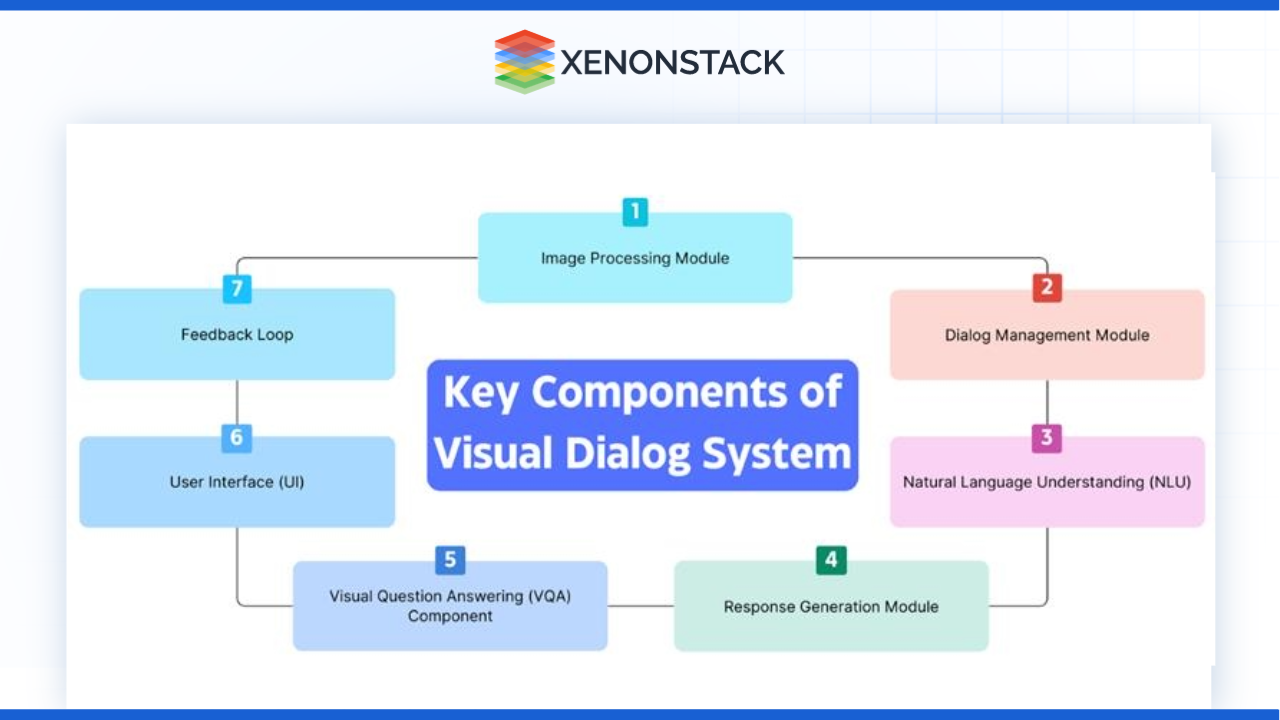
Examples of Existing Systems
Microsoft’s Seeing AI
Seeing AI by Microsoft is a good example of an image chat system developed to help people with impaired vision. With the help of this smart application, it is possible to describe surroundings, regard objects and read texts aloud. It can also be a functional way for users to discuss information displayed in the pictures. The app can also determine what currency is being used and who people are, and even give some details as to the emotions of people in the area, thus expanding the user’s knowledge of his or her locale.
Google’s Lookout
Google has a Lookout application that performs the same functions: when using AI, the user can recognize objects, read text, and navigate their surroundings. It offers voice instructions in connection with the picture or image taken by the camera, maintaining a conversation between the user and the system. Lookout has been very helpful, especially in schools, where a visually impaired student can more easily access his or her environment.
Visual Chatbot Systems in E-commerce
Some e-business websites have adopted visual chat systems to ensure that customers interact. For example, Shopify and other platforms have integrated systems capable of recognizing images and answering client questions. It is possible to make pictures with products that the user is interested in, as well as receive recommendations from the chatbot based on the visual content. These systems can improve the shopping experience by allowing users to inquire about objects, for instance, “What material is this jacket made from?” or “Can you show me other items in this colour?”
Visual Question Answering Systems
Coming under the umbrella of Image Chat systems are WQA or the Visual Question Answering systems, which includes ViLT (Vision-and-Language Transformer), currently in Beta. These models can describe an image and allow users to ask questions and get responses from images as a conversation. This is only possible due to big data and the usage of deep learning algorithms, which allow systems to reply based on context. For example, it may be a case where a user posts a photo of food and the comment, “What ingredients have been used to prepare this?” Indeed, the system can analyze the image and respond, thus making the interface much more interesting.
Social Media Platforms
Other social media services, such as Instagram and Facebook, also offer services that have visual dialogue components. Such platforms enable people to use image comments and private and group messages for an actual conversation. Some websites have used chatbots to translate images users create to enhance interaction. The platform allows users to pose queries to images that appear in their feeds and get information or recommendations about similar materials.

Future Directions and Innovations
Multimodal Learning
With time, emphasis is being launched on multimodal learning in which an attempt is made to include info from texts, images and audio. This approach allows for higher types of understanding and communication, thereby clearing the path for the emergence of synchronous mixed-media systems. Subsequent generations of visual dialog systems may contain audio feedback, allowing people to engage with images and get answers directly in the form of voiced words, accelerating interactivity.
Emotion Recognition
Other potentials that can improve the features of visual dialog systems include emotional recognition. It was further suggested that by identifying a user’s facial expression, the pitch of their voice, and related context, such systems could more effectively identify the user’s emotional state processes and their respective response patterns thereto. For instance, if a user posts an image accompanied by words of frustration, the system could reply with a message understanding that and possible ways of approaching the image based on the visual content.
Improved Feedback Loops for a User
The following section explains how this enhanced feedback loop component helps improve a user’s feedback loop. Users' feedback regarding the interactions within visual dialogue systems can be incorporated into improvement and subsequent iterations. This way, users can give information about the correctness and pertinence of valuable answers to improve the matching of models to the users' requirements. This means that iterative growth is maintained so that systems will be able to change over the user expectations and user preferences.
Ethical Considerations
When the frequency of using image chat and visual dialogue systems increases, it is relevant to determine their ethical issues. Concerns about privacy, data protection, and bias must be well addressed to guarantee the responsible implementation and use of such systems. A set of standard protocols must be conceived to protect user data and ensure that visual dialog systems are open for all users. Developers and researchers must follow an ethical framework. 
Summary
Image chat and the visual dialogue system are, therefore, major leaps forward for creating an engaging interface with media content. When natural language processing is integrated with computer vision in these systems, this improves the users’ interaction and accessibility and increases personalization. Still, uncertainty, context, and data are emerging as critical barriers to achieving success. Nevertheless, continuous investigation and enhancements in existing instruments hold the promise of providing tangible solutions.
Finally, when further expanding the concept of image chat and developing more extensive visual dialogue systems, greater attention should be paid to the diversity of the dataset collected and the accessibility of the products developed. In doing this, we shall ensure that such systems will suit many users and help create an even more connected internet.
Communication of the future is unquestionably visual, and as we begin mastering AI for image recognition and subsequent answers to it, we can generate more friendly and motivating consumer experiences worldwide. As these technologies progress, they have the ability to transform how we refer to information and to one another to form a new epoch of communications that is inclusive of graphical appeal.
Therefore, technically, image chat and visual dialogue systems are not only advancements but symbolize the means of interpersonal communication. With this visual future, it is important to remember the problems and concerns accompanying them. Only if people working on creating these systems choose to act more responsibly and create an environment more tolerant of any people, no matter their origin or race, can a system succeed in the attempt to transfigure human communication for the better.




























