

In the last few years, LLMs have emerged as some of the most influential technologies shaping several industries, ranging from customer support to analytics. Such AI-grounded systems allow for highly complex uses, including, but not limited to, chatbots, existence as content generators, and even real-time decision-making. However, the rapid adoption of LLMs also comes with major security risks.
The risks may include data invasion, interruptions of available services, or unethical results in this case. AI Security aims to enhance the security of AI systems. Familiarizing these risks is necessary to prevent situations where AI-based systems deploy features that, when exploited, result in adverse outcomes for developers, businesses, and users.
Understanding LLM Vulnerabilities
Vulnerabilities in LLMs refer to weaknesses in the model’s architecture, training, deployment, and operation that can be exploited by malicious actors or lead to unintended consequences. These vulnerabilities can stem from various sources, including insecure model design, adversarial attacks, improper handling of sensitive data, or flaws in the model’s interaction with other systems.
LLMs are complex systems that process vast amounts of data and generate human-like outputs. Because they are designed to interact with users and other systems, they become attractive targets for exploitation. With such a broad range of applications—from chatbots to virtual assistants to data analytics platforms—addressing LLM vulnerabilities is critical to maintaining trust and security. 
Defining LLM Vulnerabilities
LLMs face multiple types of vulnerabilities that can compromise their security and functionality. Some of the most common include:
-
Prompt Injection: Manipulating the LLM’s inputs to cause unintended actions or responses.
-
Insecure Output Handling: Failing to properly validate and sanitize model outputs before interacting with backend systems.
-
Training Data Poisoning: Tampering with the data used to train LLMs, introducing biases or vulnerabilities.
-
Model Denial of Service (DoS): Overloading the LLM system with excessive requests, causing service degradation or downtime.
-
Supply Chain Vulnerabilities: Security risks introduced through third-party datasets, models, or plugins.
-
Sensitive Information Disclosure: Unintentionally revealing confidential or sensitive data through model outputs.
-
Insecure Plugin Design: Exploiting insecure plugins integrated with LLMs.
-
Excessive Agency: Allowing the LLM to take action with unintended consequences due to overly broad permissions.
-
Overreliance: Relying too heavily on LLM outputs without proper oversight, leading to misinformation or miscommunication.
-
Model Theft: Unauthorized access or theft of proprietary LLM models.
AI Agent Vulnerabilities
AI agent vulnerabilities can be defined as threats related to AI systems' functionality and structural characteristics. These vulnerabilities arise out of the interaction of the agents with the user and other systems or with the external environment. Hence, these agents can be controlled, manipulated or misused. Some of these are authorization hijacking, whereby an attacker can take control of an agent’s functions, and goal manipulation, whereby an attacker can manipulate an agent’s goals to make it perform desirable actions he or she would not have been willing to do. Also, vulnerabilities such as hallucination, resource exhaustion, and knowledge base poisoning can lead to wrong outputs, crashes, or long-term system halts, respectively.
The above vulnerabilities are important to mitigate as AI agents are more important to incorporate as central components of business processes to protect system integrity, data confidentiality, and continuity. Solutions, such as role-based access control, anomaly detection, or secure communication protocols, help avoid these risks. By considering and anticipating the possible threats that need to be prevented, entities can improve the protection of their AI systems and the general concept of security and, therefore, reliability within the sphere of artificial intelligence.
The Top 10 LLM Vulnerabilities: Challenges, Solutions, and Example
Now, let’s examine each of these vulnerabilities in detail, the issues they raise, examples, and how to address risks.
Prompt Injection
Challenge:
Prompt injection vulnerabilities arise when crafted user inputs alter a language model’s behaviour in unintended ways, potentially leading to harmful outcomes. These attacks are challenging because injected prompts may be invisible to humans yet interpreted by the model. 
Example of Vulnerability:
-
Direct Injection: An attacker directly manipulates model prompts to bypass safety protocols.
-
Indirect Injection: External content contains hidden instructions that alter the model’s response.
-
Multimodal Injection: Hidden prompts in images accompanying text trigger unintended behaviour.
Solution:
To mitigate prompt injection:
-
Constrain Behavior: Hence, establish and maintain a clear line of respondent and model roles.
-
Validate Outputs: A certain format should always be followed, and the responses should always be validated.
-
Filter Inputs/Outputs: Screen content for specific items carefully for signs of bogus or wanted content.
-
Privilege Control: Restrict or disable most of the model’s features as much as possible.
-
Adversarial Testing: Practice on actual targets to learn their weaknesses.
Sensitive Information Disclosure
Challenge:
Data leakage using LLMs is dangerous as it violates clients' privacy and business, and proprietary information can be revealed. Two main categories of threats include improper data handling: configuration and prompt injection. 
Examples of Vulnerabilities:
-
PII Leakage: Model outputs may accidentally disclose personally identifiable information (e.g., names and addresses).
-
Proprietary Algorithm Exposure: Sensitive business algorithms or model training data may be exposed due to poor output configurations or inversion attacks.
-
Sensitive Business Data Disclosure: Confidential business data can unintentionally be included in generated responses.
Solution:
-
Sanitization: To maintain informational security, use proper input checks and clean to avoid inputting sensitive information into the model.
-
Access Controls: Since data leakage is a sure sign of an external data breach, strict access control and restriction of data source access will go a long way toward containing leakage.
-
Federated Learning & Privacy Techniques: Apply federated learning and differential privacy to make local data storage and hide particulars from everyone.
-
User Education: Give the user clear and understandable policies on the safe way of interacting with LLMs to avoid giving out sensitive information.
Data and Model Poisoning
Challenge:
Data poisoning degrades the model by feeding it with a wrong/biased data set at the training, fine-tuning, or embedding stage. This can lead to adverse outputs, backdoors, or a lower-than-expected performance decline. 
Examples of vulnerabilities:
-
Malicious data injection: Attackers utilize adversarial techniques to feed the model with data containing biased or incorrect information, thus changing its general behaviour. Examples of such techniques include “Split-View” or “Frontrunning Poisoning” regarding model training.
-
Sensitive data leakage: Some insights they reveal are proprietary but become visible through the model's output.
-
Unverified data sources: Using raw data means that the information one feeds into a machine can cause one to make wrong or even misleading decisions.
Solution:
-
Track and verify data origins using tools.
-
Use sandboxing, anomaly detection, and tailored datasets for fine-tuning.
-
Implement version control (DVC) and model monitoring for early poisoning detection.
-
Use RAG and grounding techniques during inference to reduce hallucinations and improve accuracy.
Improper Output Handling
Challenge:
Improper Output Handling occurs when outputs generated by large language models (LLMs) are not properly validated, sanitized, or managed before being passed downstream to other systems. This issue exposes systems to risks like unauthorized access and potential exploitation through vulnerabilities in LLM-generated content.

Figure 5: Case of Improper Output Handling
Example of Vulnerabilities:
-
LLM output is directly passed to system shells or executed functions, causing remote code execution.
-
JavaScript or Markdown generated by LLM, leading to cross-site scripting attacks.
-
SQL injection via unsanitized LLM-generated SQL queries.
-
Path traversal vulnerabilities from unsanitized LLM output used in file paths.
-
Phishing attacks resulting from improperly escaped LLM-generated content in email templates.
Solution:
-
Apply a zero-trust model and validate all responses from the LLM before passing them to backend systems.
-
Follow the application Security Verification Standard (ASVS) for input validation and sanitization.
-
Encode LLM outputs for the context in which they are used, such as HTML, SQL, or JavaScript.
-
Use parameterized queries for database operations and implement strict Content Security Policies (CSP) to mitigate risks.
-
Enable robust monitoring and logging to detect unusual patterns in LLM outputs that could indicate potential exploitation.
Supply Chain Vulnerabilities
Challenge:
Supply chain vulnerabilities put LLM supply chains at risk of having tainted datasets, corrupted pre-trained models, and insecure collaborative platforms, which lead to biased models, security breaches, and operational breakdowns. Unlike other software, the ML supply chain involves data, models, and tools and is vulnerable to poisoning and tampering. 
Example of Vulnerabilities:
-
Outdated Dependencies: Exploitation of outdated Python libraries, such as in attacks on PyPI and the Shadow Ray vulnerability.
-
Tampered Pre-Trained Models: PoisonGPT manipulated Hugging Face safety features by altering model parameters.
-
Vulnerable Fine-Tuning Adapters: Compromised LoRA adapters introducing backdoors during model merging.
-
CloudJacking: CloudBorne firmware attacks expose sensitive data in shared cloud infrastructures.
-
Malware in Model Repositories: Fake versions of popular models (e.g., WizardLM) containing malware.
Solution:
-
Data and Model Integrity: Check with the vet suppliers, Anomaly detection, and use the AI Red Teaming to detect acts of tampering.
-
Provenance Assurance: To manage and ensure the integrity of the models and datasets, SBOMs should be signed cryptographically.
-
Secure Fine-Tuning: Always ask only authorized LoRA adapters and always monitor during the merging of models.
-
Cloud Security: Store deployed models securely; check firmware integrity; watch for shared resource abuse.
-
License Management: Verify audit licenses with automated software, including open-source and other proprietary requirements.
-
User Awareness: User training on detecting the presence of those tampered apps and learning where to get them from.
Such a multiple-layer strategy reduces risks by enforcing security, openness, and compliance within LLM supply chains.
Excessive Agency
Challenge:
Excessive Agency occurs when an LLM-based system is granted too much autonomy, permissions, or functionality, enabling unintended or malicious actions. Common triggers include hallucination, poorly engineered prompts, or prompt injection attacks. This vulnerability poses risks to confidentiality, integrity, and availability.
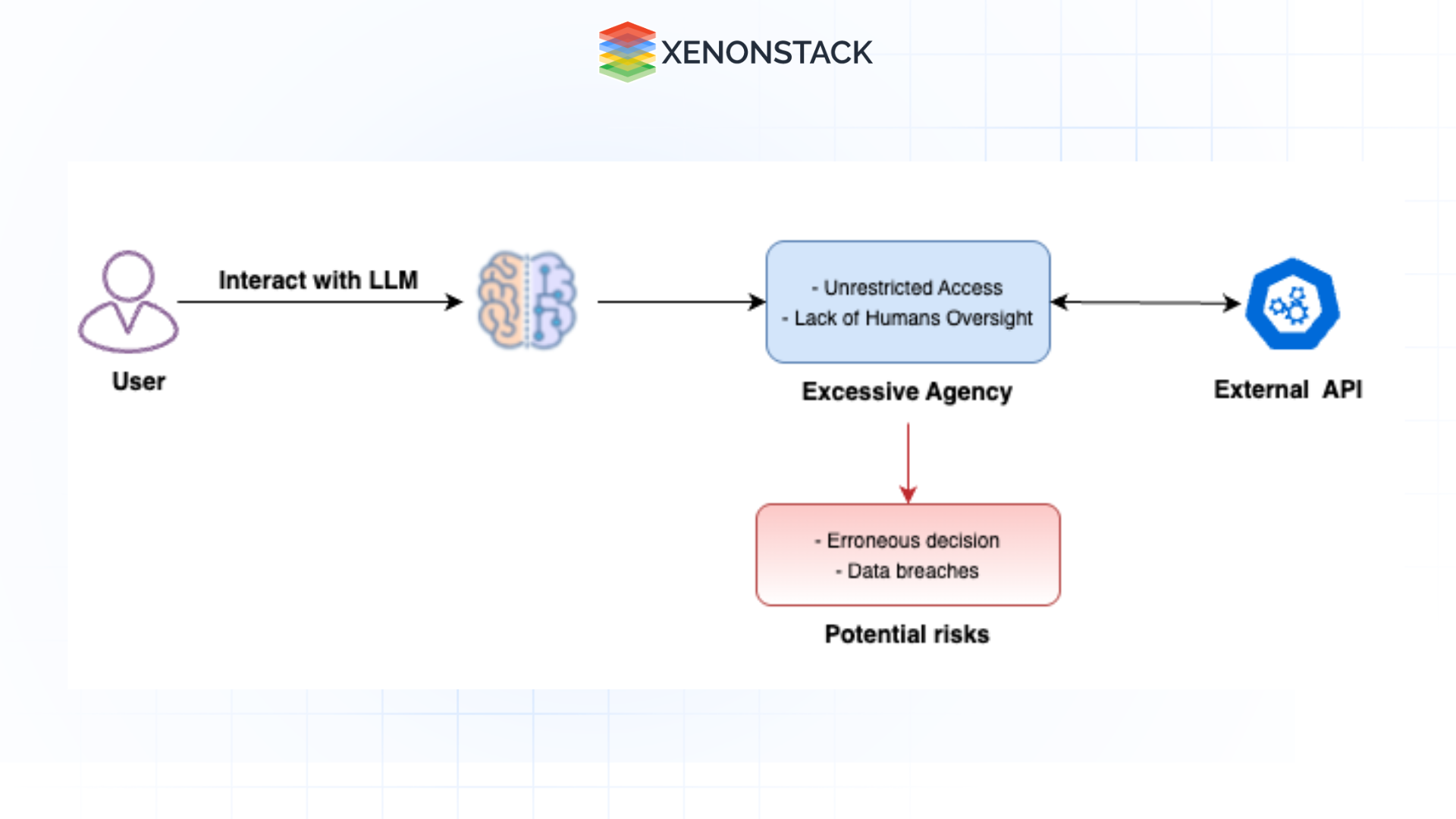 Figure 7: Flow of excessive agency as a vulnerability.
Figure 7: Flow of excessive agency as a vulnerability. Examples of Vulnerabilities:
-
Excessive Functionality: An LLM agent has unnecessary access to functions like modifying or deleting documents when only read access is needed.
-
Excessive Permissions: An LLM extension with permissions to modify databases when it only needs read access.
-
Excessive Autonomy: An LLM extension that deletes documents without user confirmation.
Solutions:
-
Minimize Extensions: Disallow all other extensions to interact with LLM in any way other than allowing only those deemed necessary.
-
Limit Functionality: Make sure extensions do not include more than necessary features and do not allow open commands.
-
Enforced Permissions: The access to an extension to downstream systems should be limited to the minimum extent possible.
-
Human-in-the-Loop: The prediction suggests the user must authorize high-risk actions before implementation.
-
Complete Mediation: Authorization should be carried out downstream systems to enforce security policies.
System Prompt Leakage
Challenge:
System prompt leakage occurs when the LLM displays information that it should not or exposes the internal rules of the system prompts used within the LLMs. This can result in weaknesses, such as unauthorized access or control bypass, especially when attackers get information about the system's behaviour or impressive structure.
Examples of Vulnerabilities:
-
Exposure of Sensitive Functionality: System prompts may contain sensitive data like API keys or user tokens, which attackers can exploit for unauthorized access or targeted attacks (e.g., SQL injection).
-
Exposure of Internal Rules: System prompts can reveal information about internal decision-making or security rules, allowing attackers to bypass security mechanisms (e.g., transaction limits or loan amounts).
-
Revealing Filtering Criteria: The system prompt may disclose criteria for filtering or rejecting sensitive content, potentially helping attackers bypass content moderation measures.
-
Disclosure of Permissions and User Roles: System prompts may reveal internal role structures and permissions, facilitating privilege escalation attacks.
Solutions
-
Separate Sensitive Data: Keep sensitive information like credentials and user roles outside of system prompts and in secure storage.
-
Use External Systems for Behavior Control: Rely on external systems, rather than system prompts, to manage critical behaviour like filtering or user access control.
-
Implement Guardrails: Use independent systems to monitor and validate LLM output for compliance with security expectations.
-
Enforce Security Controls Independently: Ensure critical security controls (e.g., access control, privilege separation) are enforced outside the LLM, ensuring they are not dependent on its internal prompts.
Vector and Embedding Weaknesses
Challenge
Such Retrieval Augmented Generation (RAG) integrations with Large Language Models (LLMs) have major security implications in processing and addressing vectors and embeddings. Vulnerabilities related to the generation, storage or retrieval of the data put the data at risk of being exploited by malicious individuals, and theft and manipulation of the models used in the system put the credibility and confidentiality of the system at risk.
Examples of Vulnerabilities
-
Unauthorized Access & Data Leakage: Lacking access controls means that some names embedded in logos can be retrieved by the wrong people, who may access and release private or proprietary information. Lack of adherence to usage policies during augmentation may cause the data to have legal repercussions because of bad data management.
-
Cross-Context Information Leaks: Combining vector databases within multi-tenant scenarios causes data leakage from other unauthorized users who may focus on other contextual information. The discrepancy of knowledge learned from different federated sources also likely decreases the model’s efficiency or misguides responses.
-
Embedding Inversion Attacks: By reversing embeddings, attackers can obtain the source information, learn new things, access proprietary knowledge, or access personal details. This may open up an opportunity to unveil latent structures and other information that has to remain under wraps.
-
Data Poisoning Attacks: This data can contaminate the model’s knowledge base, influence or compromise the outputs, or even reduce model effectiveness. It is vulnerable to injection attacks from within and out and can be destroyed by inserting negative data into different paths.
Solution
Fine-Grained Access Control
-
Implement strict access permissions for vector and embedding stores to protect sensitive data.
-
Partition datasets logically to prevent unauthorized data retrieval.
Data Validation & Source Authentication
-
Ensure that only validated and trusted data sources are used for augmentation.
-
Regularly audit and sanitize data to detect and prevent poisoning.
Knowledge Base Integrity Monitoring
-
Implement robust mechanisms to review and classify data from multiple sources.
-
Flag inconsistencies and ensure proper access restrictions to prevent cross-context leaks.
Continuous Monitoring & Logging
-
Maintain detailed, immutable logs to track retrieval activity and detect suspicious behaviour.
-
Implement real-time monitoring systems to respond to potential vulnerabilities quickly.
Misinformation
Challenge
LLMs can generate misleading or entirely false information that appears credible, posing risks such as security breaches, legal complications, and reputational damage. Hallucinations, biases, and incomplete information exacerbate this issue, making it challenging to trust AI-generated content without thorough verification. 
Examples of Vulnerabilities
-
Factual Inaccuracies: Some users may make the wrong decision because the information furnished by LLMs could be erroneous. For instance, an Air Canada Chatbot interfered with a lawsuit by providing misleading information.
-
Unsupported Claims: LLMs could produce unfounded claims; this is desirable when utilized in sensitive topics such as healthcare or legal advice since people will rely on the results given by the LLM.
-
Misrepresentation of Expertise: They mask professional knowledge over the most crucial areas of learning, so those who rely on these LLMs are likely to be fed misinformation.
-
Unsafe Code Generation: AI generates insecure or nonexistent code and, if relied on blindly, can introduce insecurity into software systems.
Solution
-
Retrieval-Augmented Generation (RAG): Use verified external databases to improve model outputs and reduce hallucinations.
-
Cross-Verification and Human Oversight: Implement fact-checking and ensure human reviewers scrutinize critical content before use.
-
Secure Coding Practices: Establish protocols to prevent the introduction of security vulnerabilities through AI-suggested code.
-
User Training and Education: Educate users on the limitations of LLMs and the importance of independent verification and encourage critical thinking.
Unbounded Consumption
Challenge
Unbounded consumption is unlimited, and excessive querying of an LLM may result in resource drain, service disruption, and loss of money. This vulnerability is due to the high computational load of LLMs' siblings, particularly when implemented in a cloud environment. Thus, the attacker’s resources are used wastefully to perform the computation. 
Examples of Vulnerabilities
-
Variable-Length Input Flood: This weakness has been demonstrated when attackers submit inputs to LLMs of different sizes that are more than they can process within a limited time. This can cause high resource usage, slowing services or production disabling the service.
-
Denial of Wallet (DoW): The attackers can start by performing many operations, such as charging cloud-based AI services by cost per use. This may quickly strip the financial resources, resulting in huge losses or, in the worst case, the business offering the service provider may close.
-
Model Extraction via API: Those provoking prompt injection perform queries that produce as many output values as necessary to mimic the model. This makes it easy for them to replicate the model, hence becoming an avenue for stealing intellectual property and corrupting it.
Solutions
-
Input Validation: To avoid overloads coming from their inputs, one should set strict checks that will help to maintain inputs within given parameters.
-
Rate Limiting and Quotas: It helps limit the operations a user can manage simultaneously and gives out user quotas similarly.
-
Resource Management and Throttling: Use dynamic resource allocation to manage resources better and set timeouts for a situation where some operations might always require so many resources and would cause the system to become unstable.
-
Adversarial Robustness Training: Learn model defences to detect cases of model extraction or adversarial queries on the model.
Benefits of Specialized AI Agents
Effectively addressing these vulnerabilities offers several benefits:
-
Increased Security: Protecting against attack and breach protects the integrity of the LLM systems, thus protecting the data from unauthorized access.
-
Improved Trust: By addressing these risks, organizations can build more trust with users and guarantee that the AI system they are using is safe, secure, and ethical.
-
Compliance: Companies can follow the GDPR and CCPA to minimize the legal and financial consequences, and LLM systems should provide compliance to minimize security threats.
-
Enhanced Reputation: Some industries prove they are worthy of consumers' trust by establishing security as the top priority for AI systems, enhancing their position in the market.
Innovations in LLMs provide cutting-edge technology to industries and applications, and securing these systems is no longer a luxury but a necessity. Understanding LLM vulnerabilities in AI systems can help organizations reduce the associated risks and employ necessary security measures to prevent organizations and users from experiencing the adverse effects of malicious attacks. Good vulnerability management is not only about managing risks but also about reducing the risk of AI systems being unreliable.
More Ways to Explore Us
Developing Generative AI Solution with Private LLM
New Possibilities of Large Language Models
LLMs: Revolutionizing Data Annotation for the AI Age



