
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Agriculture is moving toward data-driven decision-making, where accuracy in predicting crop yields determines both sustainability and profitability. Agentic AI for Crop Yield Prediction on Databricks combines the power of advanced AI agents with scalable cloud infrastructure to deliver precise yield forecasting. By leveraging Databricks AI in agriculture, organisations can integrate real-time data from soil health, weather conditions, and satellite imagery into a unified pipeline for actionable insights.
Traditional models often struggle to capture the spatial-temporal complexity of farming data. With agentic AI agriculture frameworks, enterprises can deploy autonomous yield modelling agents that adapt continuously to changing conditions. These models go beyond predictive accuracy, offering explainable outputs that enhance trust for farmers, agronomists, and policymakers. The integration of generative AI for agriculture supports advanced simulations, enabling proactive strategies for crop performance optimisation and resource allocation.
At XenonStack, we align precision farming AI with operational pipelines on Databricks, ensuring scalability and resilience for enterprise use cases. Our focus on autonomous agricultural forecasting and hybrid deep learning agents makes it possible to optimise yields at scale while ensuring data governance and transparency. By connecting agentic yield forecasting with Databricks’ unified analytics, organisations unlock the ability to forecast, simulate, and optimise agricultural productivity with unmatched speed and efficiency.
Importance of Crop Yield Prediction in Modern Agriculture
Accurate crop yield forecasting is a cornerstone of precision farming. It allows farmers, agribusinesses, and policymakers to make data-driven decisions on irrigation, fertilisation, harvesting, and supply chain planning. Traditional statistical models often fall short when faced with the complexity of agricultural ecosystems, where yield is influenced by dynamic factors such as climate patterns, soil properties, and crop management practices.
This is where Agentic AI for crop yield prediction stands out. By deploying autonomous agents on Databricks AI in agriculture, organisations can unify heterogeneous datasets and leverage scalable AI pipelines for better accuracy, explainability, and resilience. Unlike static models, agentic yield forecasting continuously adapts to evolving field conditions, offering near real-time insights for farmers and agricultural enterprises.

Data Sources Powering Agentic Yield Forecasting
Crop yield prediction requires more than just historical yield statistics. It demands a holistic integration of diverse datasets that reflect environmental, biological, and management variables.
The following image illustrates the flow of crop yield prediction with agentic AI:
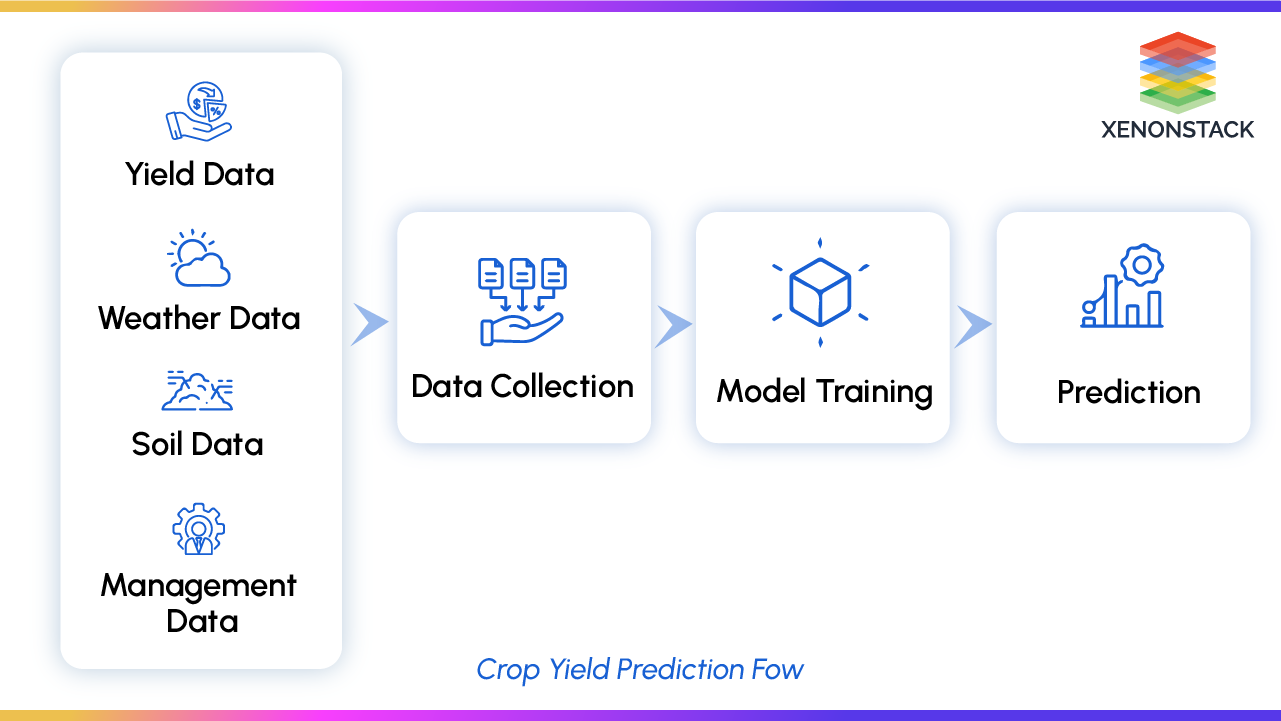
Figure : Crop Yield Prediction Flow
This Crop Yield Prediction Flow shows how different types of data are collected, processed, and transformed into predictive insights.
-
Yield Data: Past crop yields provide a foundation for building baseline models.
-
Weather Data: Climate factors such as rainfall, temperature, and humidity directly impact crop growth cycles.
-
Soil Data: Nutrient availability, pH balance, and soil moisture levels are crucial for accurate modelling.
-
Management Data: Details on irrigation schedules, fertiliser application, and pest control strategies enhance prediction accuracy.
The data then moves into three key stages: Data Collection, Model Training, and Prediction. This structured pipeline allows agentic AI agriculture frameworks to continuously refine outputs with every new data point ingested.
Why Agentic AI is Transforming Crop Yield Prediction
Traditional machine learning models are powerful, but they often act as black boxes with limited adaptability. Agentic AI agriculture frameworks introduce intelligence that is explainable, autonomous, and orchestrated across multiple specialised agents.
Key Differentiators of Agentic AI:
-
Autonomous Yield Modelling: Agents operate independently, adjusting forecasts as new weather, soil, or management data is integrated.
-
Explainable Outputs: Models are transparent, giving agronomists clarity on why a certain prediction was made.
-
Scalability on Databricks: Unified pipelines on Databricks AI in agriculture handle massive, multi-modal datasets without latency.
-
Generative AI for Agriculture: Enables simulation of hypothetical scenarios (e.g., drought impact or fertiliser optimisation).
-
Continuous Learning: Agents evolve with each crop season, reducing error rates and improving trust.
Building AI Pipelines on Databricks for Agriculture
Databricks offers a cloud-native environment that integrates data engineering, machine learning, and analytics into a single platform. For agricultural enterprises, this means eliminating silos and creating operational AI pipelines that scale.
Steps in Building Agentic Pipelines on Databricks:
-
Data Ingestion: Collecting structured and unstructured data from IoT sensors, satellites, weather stations, and ERP systems.
-
Data Engineering: Cleaning, enriching, and integrating datasets into a unified semantic context fabric.
-
Model Training: Deploying hybrid deep learning models with spatial-temporal awareness to capture environmental complexity.
-
Agent Orchestration: Multiple specialised agents coordinate tasks such as anomaly detection, forecasting, and simulation.
-
Prediction & Visualization: Insights are delivered through AI-augmented dashboards, enabling decision-makers to act in real time.
This end-to-end pipeline ensures that precision farming AI becomes both scalable and actionable.
Applications of Agentic AI in Crop Yield Forecasting
The integration of Agentic AI for yield prediction has far-reaching applications across the agricultural value chain.
Key Use Cases:
-
Precision Irrigation: Optimising water usage by forecasting moisture needs.
-
Fertilizer Optimization: Reducing input costs while maximising soil fertility.
-
Pest and Disease Management: Detecting anomalies and simulating outbreak scenarios with generative AI for agriculture.
-
Supply Chain Forecasting: Aligning production with market demand to minimise waste.
-
Policy and Research: Enabling governments to build predictive models for food security planning.
By combining autonomous agricultural forecasting with Databricks’ analytics, organisations unlock predictive and prescriptive intelligence.
Comparison: Traditional ML vs. Agentic AI for Agriculture
| Feature | Traditional ML Models | Agentic AI on Databricks |
|---|---|---|
| Adaptability | Static models, limited updates | Continuous learning with adaptive agents |
| Explainability | Often black box | Transparent and explainable forecasts |
| Scalability | Dependent on hardware limits | Elastic scaling with Databricks |
| Data Integration | Fragmented datasets | Unified ingestion across soil, weather, and yield data |
| Simulation | Limited scenario testing | Generative simulations for multiple outcomes |
| Speed | Batch predictions | Near real-time yield forecasting |
This table highlights how agentic AI agriculture frameworks extend far beyond conventional methods.
Hybrid Deep Learning and Agent Models
A unique advantage of agentic yield forecasting is the integration of deep learning architectures with agent-based reasoning. While deep learning captures complex non-linear relationships, autonomous agents add layers of decision-making, adaptability, and transparency.
Key Techniques Applied:
-
Convolutional Neural Networks (CNNs): For analysing satellite imagery and spatial crop patterns.
-
Recurrent Neural Networks (RNNs): For modelling seasonal and temporal dependencies in climate and yield data.
-
Generative Models: For creating synthetic agricultural scenarios to test resilience.
-
Agentic Orchestration: Combining outputs from multiple models into coherent, explainable insights.
This hybrid architecture ensures that yield prediction is not only accurate but also context-aware and explainable.
Ensuring Explainability and Trust
In agriculture, decision-making affects livelihoods and food security. Blind trust in black-box predictions is risky. That’s why explainable agentic AI is critical.
On Databricks AI in agriculture, explainability is achieved through:
-
Attribution methods show which variables (rainfall, soil nutrients, etc.) influenced predictions.
-
Visual dashboards that narrate insights using AI-augmented storytelling agents.
-
Transparent data lineage ensures compliance and governance.
This transparency builds confidence among farmers, researchers, and policymakers.

Role of Generative Models within Agentic AI for Agriculture
Agentic AI frameworks often integrate generative models as part of their multi-agent orchestration. While generative AI is widely known for text and image creation, within agriculture, it powers scenario simulations, synthetic data creation, and decision support—capabilities that strengthen agentic yield forecasting.
Key Applications within Agentic Pipelines:
-
Scenario Simulation: Agentic systems use generative models to simulate yield under variable conditions, such as rainfall changes or soil nutrient loss.
-
Synthetic Data Generation: Creating representative datasets for crops and regions where historical yield data is scarce.
-
Decision Support: Empowering forecasting agents to provide proactive recommendations on irrigation, fertiliser, or pest management.
By embedding generative AI for agriculture into agentic AI pipelines, organisations move beyond static predictions toward proactive, adaptive, and explainable optimisation.
Benefits of Agentic AI on Databricks for Agriculture
-
Higher Accuracy: Multi-agent orchestration reduces error margins.
-
Scalable Infrastructure: Databricks ensures seamless scaling across geographies and crops.
-
Sustainability: Optimising water, fertiliser, and pesticide use reduces environmental impact.
-
Operational Efficiency: Automating data workflows minimises manual intervention.
-
Economic Gains: Accurate forecasting reduces risks, improves profitability, and stabilises supply chains.
These benefits highlight why agentic AI for crop yield prediction is a cornerstone of precision farming AI.
XenonStack’s Approach to Agentic AI in Agriculture
At XenonStack, we leverage agentic AI agriculture frameworks to deliver enterprise-ready solutions on Databricks. Our approach integrates:
-
Semantic Context Fabric: Ensures unified data governance and explainability.
-
Specialised Insight Agents: For forecasting, anomaly detection, and narrative insights.
-
AI-Augmented Dashboards: Allowing non-technical users to query data in natural language.
-
Responsible AI Principles: Guaranteeing fairness, transparency, and compliance.
This methodology ensures that organizations can deploy autonomous agricultural forecasting at scale with trust and confidence.
Future of Crop Yield Prediction with Agentic AI
As agricultural challenges grow with climate change, water scarcity, and rising demand, the role of agentic yield forecasting will only expand. The combination of Databricks AI in agriculture, generative modelling, and multi-agent orchestration opens the door to:
-
Regional and global food security simulations.
-
Real-time collaboration between farmers, agronomists, and governments.
-
Integration of IoT, satellite imagery, and AI-driven insights into seamless ecosystems.
The future is not just predictive—it is proactive and autonomous, ensuring resilience for the agricultural sector.



























