
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
What Is Data Fabric vs Data Mesh? A Complete Guide to Modern Data Architecture
Data Fabric vs Data Mesh are two modern approaches to solving enterprise data management challenges in distributed cloud environments. As organizations become information-driven and operate across cloud, IoT, and hybrid infrastructures, they require architectures that enable seamless data sharing, governance, and scalability.
In the hyper-connected world of the cloud and the Internet of Things (IoT), each processing network gadget is associated with one more through a perplexing, interconnected network. Current ventures attempt to become information-driven associations and get more business esteem from their information. However, the ascent of the cloud, the Internet of Things (IoT) development and different elements imply that notification isn't restricted to on-premises conditions. This represents a genuine test for future Data Management, as a definitive objective of Data Management is sharing business information across different stages and innovations.
The terms "data mesh" and "data fabric" are frequently utilized reciprocally to demonstrate data-access architecture in a hyper-associated Data Management world. Data fabric is more of an architectural approach to data access, whereas the mesh connects data processes and users.
Some of the core principles of data mesh architecture are:
- Domain-oriented data ownership and architecture
- Data as a product
- Self-service data platform
- Federated computational governance
Data fabric should work with various data delivery methods (including, but not limited to, ETL, streaming, replication, messaging, and data virtualization or data microservices).
Key Takeaways
- Data Fabric centralizes data access control through automation and metadata intelligence; Data Mesh decentralizes data ownership to domain teams.
- Data Fabric is technology-driven; Data Mesh is organizational-driven. They solve different root causes of the same problem.
- Data Mesh requires Data Fabric's discovery and integration principles to function at scale — they are complementary, not mutually exclusive.
- For CDOs and CAOs: Data Fabric reduces dependency on centralized IT for data pipeline management, accelerating time-to-insight across business units.
- For Chief AI Officers and VPs of Analytics: Data Mesh enables domain teams to own the data quality feeding your AI and ML models — shifting model performance accountability closer to the business.
Data fabric should work with various data delivery methods (including, but not limited to, ETL, streaming, replication, messaging, and data virtualization or data microservices).Read more about Big Data Fabric Implementations and Its Benefits
What Is the Core Difference Between Data Fabric and Data Mesh?
| Dimension | Data Fabric | Data Mesh |
|---|---|---|
| Architecture type | Centralized access layer | Decentralized domain ownership |
| Primary driver | Technology automation | Organizational structure |
| Data control | Single point of control (SPOC) | Distributed — each domain manages its own |
| Integration method | AI-driven, automated | Human domain experts drive requirements |
| Data ownership | Centralized (typically IT) | Domain-specific teams |
| Best for | Unified access across hybrid/multi-cloud | Scaling domain autonomy and data product ownership |
The terms are frequently used interchangeably — incorrectly. Data Fabric is an architectural approach to data access. Data Mesh connects data processes and the people who own them.
Centralized vs. Decentralized: What Does Each Architecture Actually Deliver?
-
Centralized (Data Fabric model): All domain data is replicated to a single location — such as a unified data lake. Centralized IT owns and governs the data. Cross-domain data models are built centrally, producing unified views across the enterprise.
-
Decentralized (Data Mesh model): Domain data stays within the domain. Each domain maintains its own data lake, its own data models, and its own ownership. Copies of datasets are created only for specific, well-defined use cases.
-
The practical implication for enterprise architects: Centralized architectures excel at governance consistency and cross-domain integration. Decentralized architectures excel at domain autonomy, agility, and scaling data operations beyond the capacity of central IT.
Is Data Mesh centralized or decentralized?
Data Mesh is decentralized, distributing ownership across domain teams instead of central IT control.
Explore more about the challenges faced by data architecture.
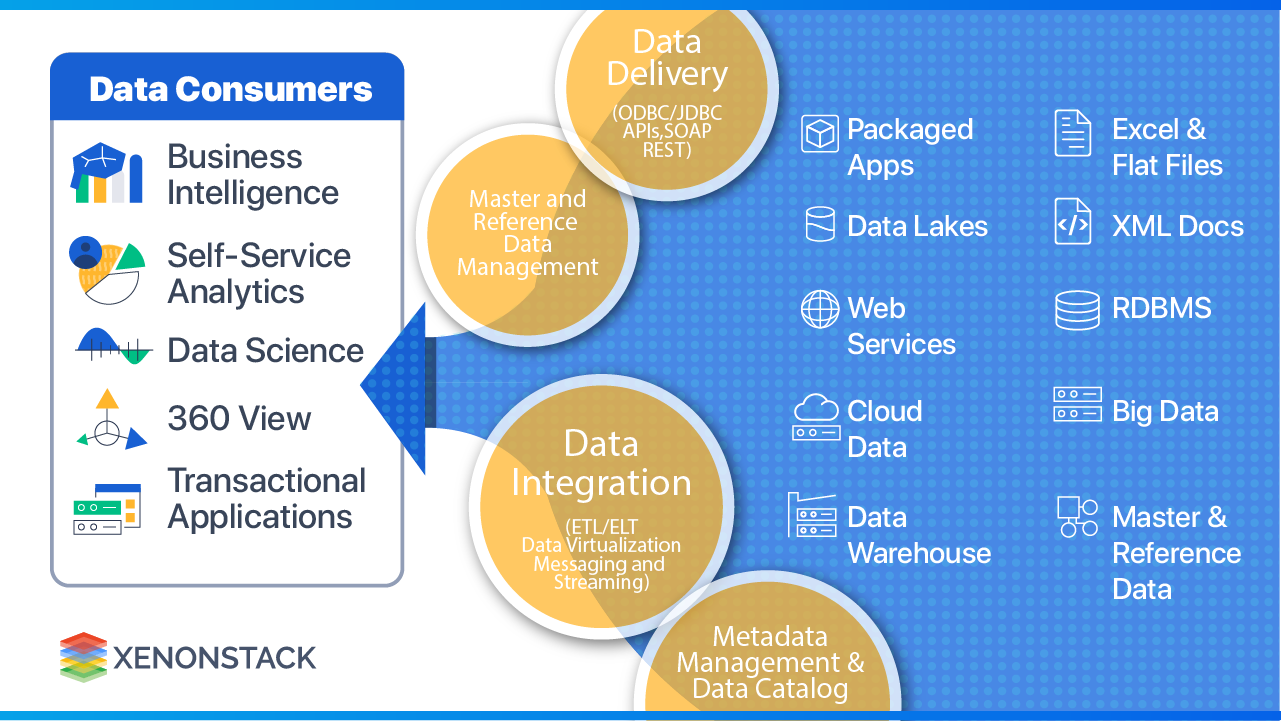
What Is Data Fabric and How Does It Work in Enterprise Environments?
Definition: A Data Fabric is an architecture that integrates technologies and services to provide unified, automated access to distributed data — regardless of where that data resides.
Data Fabric is agnostic to architectural approach, geographic location, data use case, and deployment platform. It supports all major data delivery methods including ETL, streaming, replication, messaging, data virtualization, and data microservices.
Compatible data store types: Relational databases, tagged files, flat files, graph databases, document stores.
Core technology integrations:
- Apache Kafka — real-time streaming
- ODBC — open database connectivity
- HDFS — Hadoop distributed file system
- REST APIs — service-layer integration
- POSIX / NFS — file system standards
The operational goal: Provide the right data, in real time, with end-to-end governance, at enterprise scale — without requiring domain teams to manage underlying source systems.
What is Data Fabric used for?
Data Fabric enables unified, automated access to distributed data across hybrid and multi-cloud environments.
How Does Data Fabric Support AI and ML Pipelines?
Data Fabric addresses a critical upstream dependency:
AI and ML models are only as good as the data fed into them. Data Fabric enables ML models to access accurate, real-time data without manual pipeline intervention. ML algorithms can monitor data pipelines, suggest relevant integrations, and identify associations across the full enterprise data landscape — accelerating model training cycles and improving prediction quality. Organizations can also unify customer activity data across channels to feed predictive models for churn, lifetime value, and next-best-offer decisions.
How does Data Fabric help AI and ML?
It ensures real-time access to accurate data, improving ML training and pipeline optimization.
What Is Data Mesh and How Does It Work?
Definition: Data Mesh is a decentralized architectural approach to analytical data management that distributes data ownership to domain-specific teams, who manage, own, and serve data as a product.
Example of Data Mesh

Rather than shipping data to a central lake or warehouse, Data Mesh empowers end users to query data where it resides. This eliminates the central IT bottleneck and scales data operations in proportion with business domain growth.
Four Core Principles of Data Mesh Architecture
- Domain-oriented data ownership and architecture — each business domain owns its data end-to-end
- Data as a product — domain teams are accountable for the usability, quality, and accessibility of their data
- Self-service data platform — infrastructure enables domains to operate independently without centralized engineering support
- Federated computational governance — global standards are enforced without centralizing control
Real-World Data Mesh Use Cases
-
Customer 360 Views: Unifies customer data across systems to reduce average handle time, improve first-contact resolution, and enable predictive churn modeling and next-best-offer decisions in marketing.
-
Hyper-Segmentation: Enables marketing teams to deliver the right message to the right customer at the right time through the right channel — powered by domain-owned behavioral data.
-
Data Privacy Management: Supports compliance with regional data privacy regulations (e.g., VCDPA) by giving domain owners direct control over data access policies before data reaches business consumers.
-
Data Mesh addresses the core limitations of centralized data lakes: it gives data owners more autonomy, reduces the burden on central data teams, and enables faster experimentation and innovation at the domain level.
Data meshes address the shortcomings of data lakes by giving data owners more autonomy and flexibility, allowing for more data experimentation and innovation, and reducing the burden on data teams to meet the needs of every data consumer through a single pipeline.
When Should You Choose Data Fabric Over Data Mesh?
Choose Data Fabric when:
- Domain teams lack the expertise or capacity to manage their own data pipelines
- The organization requires a unified, automated integration layer across heterogeneous source systems
- Governance consistency across all data domains is a regulatory or compliance requirement
- AI-driven metadata management and automated data discovery are priorities
- The organization is not yet ready for the organizational transformation Data Mesh requires
Important architectural note: Data Fabric can be implemented independently of Data Mesh. It does not require a domain ownership model to deliver value.
When Should You Choose Data Mesh Over Data Fabric?
Choose Data Mesh when:
- Business domains have sufficient technical maturity to own and serve data as a product
- The organization needs to scale data operations beyond the bandwidth of a central data team
- Domain-specific context and implicit knowledge are critical to understanding dataset meaning — human experts outperform automated systems here
- Reducing data silos through domain-level incentivization is more effective than centralized enforcement
- The organization can invest in the cultural and organizational change required for federated governance
Key constraint: Data Mesh is not purely a technology decision. It requires organizational commitment to distributed ownership, which carries change management complexity that technology alone cannot resolve.
What Are the Comparative Benefits of Data Fabric and Data Mesh?
Data Fabric Benefits
| Benefit | Description |
|---|---|
| Scale and performance | Dynamically scales for both operational and analytical workloads at enterprise volume |
| Accessibility | Supports all data access modes, sources, and types — including master and transactional data at rest and in motion |
| Distribution | Deployable across multi-cloud, on-premise, and hybrid environments |
| Data integration | Automates integration between applications and source systems through AI-driven metadata |
Data Mesh Benefits
| Benefit | Description |
|---|---|
| Business agility | Decentralized operations enable independent domain performance and reduce IT backlog |
| Faster data access | Self-service model delivers faster, more accurate data delivery without centralized complexity |
| Sales and marketing | Domain-owned data enables 360-degree customer profiling, lead scoring accuracy, and lifetime value projection |
| AI/ML enablement | Domain teams can build virtual data warehouses and catalogs to feed AI models without centralizing data |
| Cost efficiency | Particularly in financial services — faster time-to-insight at lower operating and storage cost |
Which is more scalable, Data Fabric or Data Mesh?
Both scale differently—Data Fabric scales infrastructure; Data Mesh scales domain ownership.
Conclusion: Choosing the Right Architecture for Enterprise Data Strategy
Data Mesh is primarily about people, processes, and organizational structure. Data Fabric is an architectural approach that addresses the technical complexity of data and metadata management at scale.
In the near term, Data Mesh deployments are more immediately achievable because they can be implemented with existing technology. Data Fabric's full potential depends on continued maturation of AI-driven data integration capabilities — but it is deployable today in hybrid and multi-cloud environments.
For CDOs, Chief Analytics Officers, VPs of Data and Analytics, and Chief AI Officers, the decision is not binary. The question is: what combination of centralized automation and decentralized domain ownership best fits your organization's current maturity, governance requirements, and AI readiness?
Both architectures, applied appropriately, move the enterprise toward the same outcome: data that is accessible, reliable, governed, and capable of driving decisions at the speed the business requires.
Get more information related to data mesh architecture.
- Enow more about Master Data Management in Banking Sector
- Discover more about Data Quality Management
- Explore further about Data Management with Intelligent Data Agents



























