
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Let’s face it—AI and machine learning are taking over the world, and they’re hungry for data, especially images. Whether it’s training a model to spot tumors in data processing in healthcare industry, helping an e-commerce site showcase products, or analyzing satellite imagery to track climate shifts, massive image datasets are at the heart of it all. But here’s the catch: managing and automatic data processing of these mountains of images isn’t a walk in the park. It takes serious infrastructure and smart workflows to keep things running smoothly.
Why Large-Scale Image Processing Is a Big Deal for AI and ML
Large-scale image processing isn’t just a technical flex—it’s what powers real-time decisions, ramps up automation, and keeps high-performance AI systems humming. Without a solid pipeline, you’re stuck with sluggish data ingestion, clunky transformations, and ballooning costs. As AI keeps popping up everywhere, companies need scalable, budget-friendly ways to handle image data fast.
The Headaches of Working with Big Image Datasets
Anyone who’s wrestled with giant image datasets knows it’s not all smooth sailing. Here are some of the usual suspects causing trouble:
- Format chaos: One minute you’re dealing with JPEGs, the next it’s PNGs, TIFFs, or RAW files—good luck keeping it all straight.
- Metadata madness: Pulling out annotations, timestamps, or other key details can turn into a scavenger hunt.
- Compute tug-of-war: Deciding whether to lean on CPUs or GPUs without wasting resources is a balancing act.
- Scaling struggles: Processing tons of images at once without everything grinding to a halt? Easier said than done.
How Databricks Comes to the Rescue
Databricks, powered by Apache Spark Optimization, simplifies image ingestion, transformation, and ML workflows. Apache Beam and Apache Flink enhance distributed data processing in IoT, while Apache Kafka Security and Apache ZooKeeper ensure system coordination.
For real-time streaming applications with Apache Spark, scalable processing is critical. Data Processing with Presto accelerates queries over vast datasets, while Apache Hadoop Security safeguards sensitive data.
Efficient data preprocessing in ML is key to unlocking AI’s potential. The right tools ensure secure, fast, and scalable large-scale image processing, making AI truly effective.
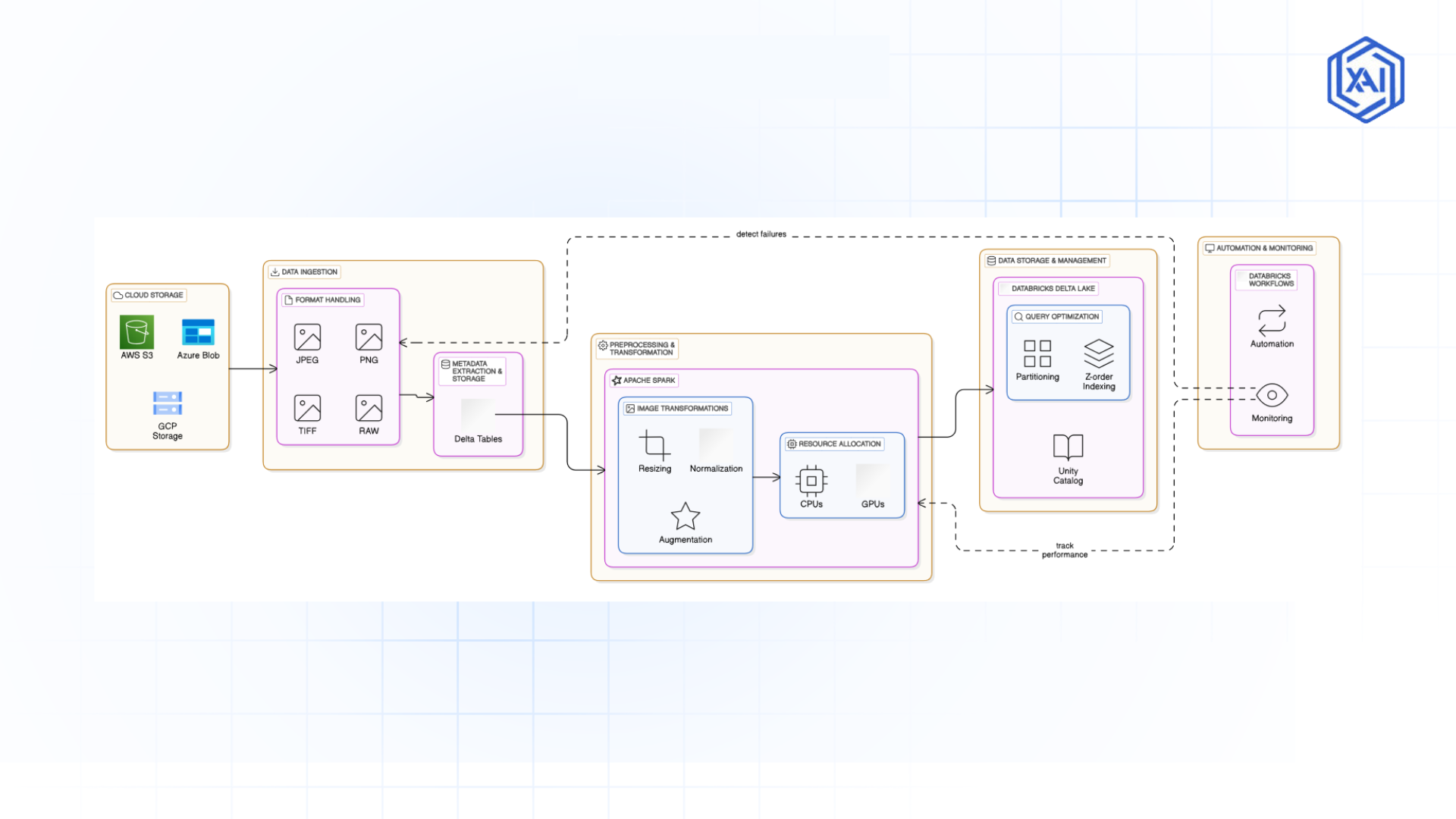 Fig 1.1: Image Data Ingestion & Preprocessing in Databricks
Fig 1.1: Image Data Ingestion & Preprocessing in Databricks Getting Started with Databricks for Image Processing
Setting Up Your Databricks Playground
Ready to dive into cloud-based image processing with Databricks? Here’s how to get started:
-
Spin up a Databricks workspace on your cloud of choice—AWS, Azure, or GCP.
-
Fire up clusters tuned for GPU-heavy image tasks (because who doesn’t love a speed boost?).
-
Load up Python libraries like OpenCV, Pillow, and TensorFlow to handle the heavy lifting.
-
Turn on Delta Lake to keep your data structured and manageable.
Databricks Features That Make Life Easier
Databricks isn’t just a pretty face—it’s packed with tools to tame your image datasets:
-
Delta Lake: Keeps things reliable with ACID transactions (think of it as a safety net for your data).
- Photon: Speeds up queries so you’re not twiddling your thumbs waiting for results.
- Workflows: Automates your image ETL pipelines like a well-oiled machine.
-
Unity Catalog: Keeps everything under control with centralized governance.
Keeping Costs in Check
No one wants to blow their budget on image processing. Here’s how to stretch those dollars:
-
Let Databricks auto scale your resources—only use what you need.
-
Store smart with Delta Tables to avoid wasteful sprawl.
-
Cache images you use a lot to save time and money.
-
Tap into spot instances for cheap GPU power.
Key Data Ingestion Strategies for Image Datasets
Importing Images from Cloud Storage (AWS S3, Azure Blob, GCP)
Databricks supports direct integration with cloud storage solutions:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("ImageProcessing").getOrCreate()
images_df = spark.read.format("binaryFile").load("s3://bucket-name/images/")
Working with Various Image Formats (JPEG, PNG, TIFF, RAW)
Databricks allows handling multiple image formats via libraries like PIL and OpenCV. It also supports image batch processing for large datasets.
Handling Metadata and Annotations for Image Datasets
Databricks facilitates image metadata extraction using structured Delta Tables:
images_df.select("path", "modificationTime", "length").show()
Efficient Image Preprocessing Techniques for Better Results
Transforming Images with Apache Spark
Apache Spark is the secret sauce behind Databricks’ ability to handle huge image workloads. It spreads tasks like resizing, normalizing, or augmenting across multiple machines, so you’re not stuck waiting around. Plus, Spark’s MLlib throws in some extra firepower for advanced preprocessing.
Imagine crunching through millions of images at once—Spark’s DataFrame API makes it happen by splitting the work across your cluster. It’s fast, efficient, and a total game-changer.
Running Parallel Processing Pipelines
With Spark DataFrames, you can process images side by side across multiple nodes. That means real-time apps—like facial recognition or medical imaging—don’t have to slow down, even with massive datasets. Every image gets its makeover at the same time, keeping your pipeline humming and your computer vision projects on track.
from pyspark.sql.functions import col
images_df.withColumn("resized", resize_image_udf (col("content")))
CPUs vs. GPUs: Picking the Right Tool
Choosing between CPUs and GPUs can make or break your efficiency:
-
CPUs: Perfect for simpler stuff like cropping, resizing, or pulling metadata. They’re solid for lightweight tasks.
-
GPUs: The go-to for heavy hitters like object detection or deep learning. They’ll blaze through complex jobs—think self-driving cars or medical diagnostics.
Mixing and matching CPU and GPU power in Databricks keeps costs down and performance up.
Organizing and Managing Image Datasets for AI Projects
Structuring Metadata with Delta Tables
Want your image data neat and tidy? Delta Tables in Databricks Delta Lake store metadata—like sizes, file types, or labels—in a way that’s easy to query. It’s like giving your images a filing cabinet with superpowers.
images_df.write.format("delta").save("/mnt/delta/images")
Versioning and Tracking Changes
Ever wish you could hit “undo” on a dataset? With Unity Catalog, you can:
-
Keep a history of changes to your images.
-
Trace how your data’s been tweaked over time.
-
Lock things down with access controls for security.
This kind of tracking keeps your datasets legit and reproducible.
Speeding Up Image Lookups
Finding the right images fast is a must. Delta Tables come with tricks like:
-
Z-order indexing to zip through metadata searches.
-
Partitioning by categories (like date or type) for quicker access.
-
Caching popular images so they’re ready when you need them.
These hacks make your ML and computer vision workflows fly.
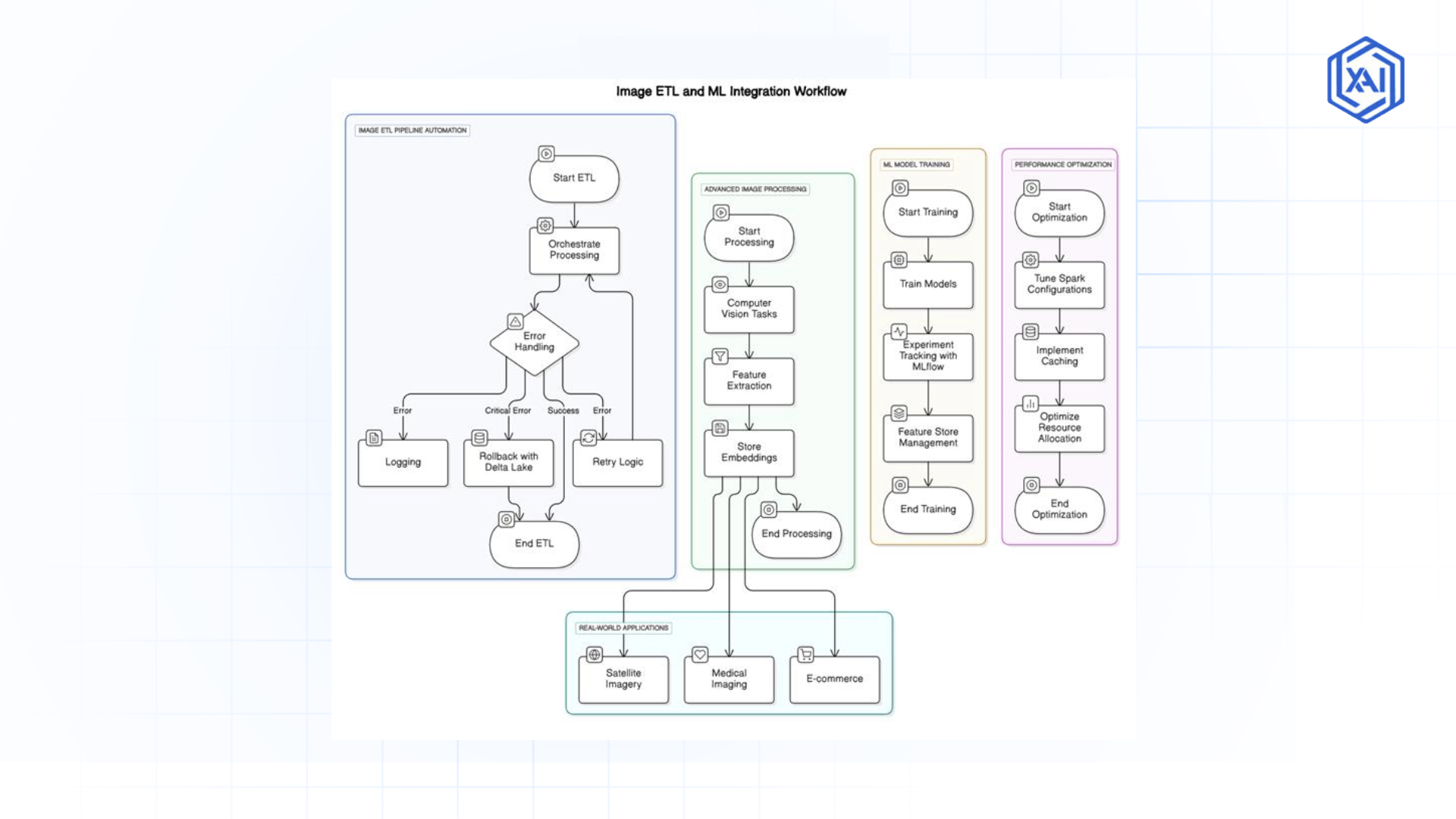 Fig 1.2: Image ETL Pipelines, Advanced Processing & ML Integration
Fig 1.2: Image ETL Pipelines, Advanced Processing & ML Integration Building Scalable Image ETL Pipelines with Databricks
Automating with Databricks Workflows
Databricks Workflows are like your personal assistant for image processing. They handle scheduling, dependencies, and automation, so your ingestion, preprocessing, and transformation jobs run like clockwork.
Handling Hiccups in the Pipeline
Things don’t always go perfectly, but Databricks has your back:
-
Retry failed tasks automatically.
-
Log issues so you can figure out what went wrong.
-
Use Delta Lake’s time travel to roll back if something breaks.
This keeps your pipeline tough and your data safe.
Keeping an Eye on Things
With Databricks Job Monitoring, you can watch your pipelines in action:
-
See how long jobs take and tweak slow spots.
-
Spot bottlenecks in your Spark cluster and shuffle resources around.
-
Pull reports to keep everything running smoothly.
It’s all about staying efficient and cost-effective.
Advanced Image Processing Techniques for Large Datasets
Scaling Computer Vision Tasks
Databricks teams up with tools like OpenCV, TensorFlow, and PyTorch to tackle big computer vision jobs:
-
Edge detection for spotting objects.
-
Segmentation for medical imaging.
-
Classification for huge datasets.
Pulling Features from Tons of Images
Need to extract visual goodies from a giant image collection? Deep learning models on Databricks Delta Lake can whip up embeddings for things like:
-
Finding similar images fast.
-
Spotting defects in factories.
-
Recognizing faces or biometric patterns.
Plugging in Deep Learning Frameworks
Databricks works together with TensorFlow and PyTorch, letting you:
-
Train models on GPU-powered clusters.
-
Run real-time detection and feature extraction.
-
Track experiments with MLflow.
It’s a one-stop shop for AI-driven image processing.
Performance Optimization for Large-Scale Image Workflows
Fine-Tuning Spark for Images
Get the most out of Spark with some smart tweaks:
-
Bump up memory to avoid crashes.
-
Use Photon for lightning-fast calculations.
-
Streamline data shuffling for better flow.
Caching for Speed
Cache the images you use a lot to save time:
-
Delta Cache speeds up repeat queries.
-
Disk caching handles big collections without a hitch.
Testing and Tuning
Keep your pipelines in top shape by:
-
Comparing CPU and GPU runtimes.
-
Profiling jobs to catch slowpokes.
-
Adjusting how data’s split up.
These steps keep things fast and scalable.
Real-World Use Cases of Image Processing Technology
Satellite Imagery Made Simple
Satellite images are gold for tracking crops, weather, or disasters. Databricks makes it manageable by:
-
Using Spark to process terabytes of data in parallel.
-
Storing metadata in Delta Lake for easy lookups by location or time.
-
Running ML to spot changes—like shrinking forests or growing cities.
Workflows keep the analysis fresh and on schedule.
Prepping Medical Images
From MRIs to x-rays, medical imaging needs speed and precision. Databricks delivers:
-
Parallel preprocessing for thousands of scans.
-
GPU-powered models for spotting tumors or segmenting organs.
-
Unity Catalog for secure, compliant data handling.
Delta Lake keeps everything consistent and ready for ML.
E-commerce Image Magic
E-commerce sites live or die by their product images. Databricks helps by:
-
Enhancing pics with computer vision tricks like upscaling.
-
Removing backgrounds with deep learning models.
-
Tagging images for better search and recommendations.
Spark and Delta Lake keep it fast and smooth.
Seamless Integration with ML Workflows for Image Processing
Getting Datasets ML-Ready
ML models need clean, prepped data. MLflow in Databricks offers:
-
Versioned datasets for consistency.
-
Data tracking to see how images were processed.
-
Easy access to TensorFlow, PyTorch, and Keras.
Feature Stores for Vision Projects
Feature stores save time by:
-
Storing pre-extracted image features for quick reuse.
-
Enabling fast searches for similar images.
-
Scaling up multi-modal workflows with text and metadata.
Databricks Feature Store keeps it all high-performance.
Tracking Experiments with MLflow
MLflow keeps your image model experiments organized:
-
Logs hyperparameters and results automatically.
-
Versions models for repeatability.
-
Shows dashboards to compare setups.
It’s a seamless way to manage ML on big image datasets.
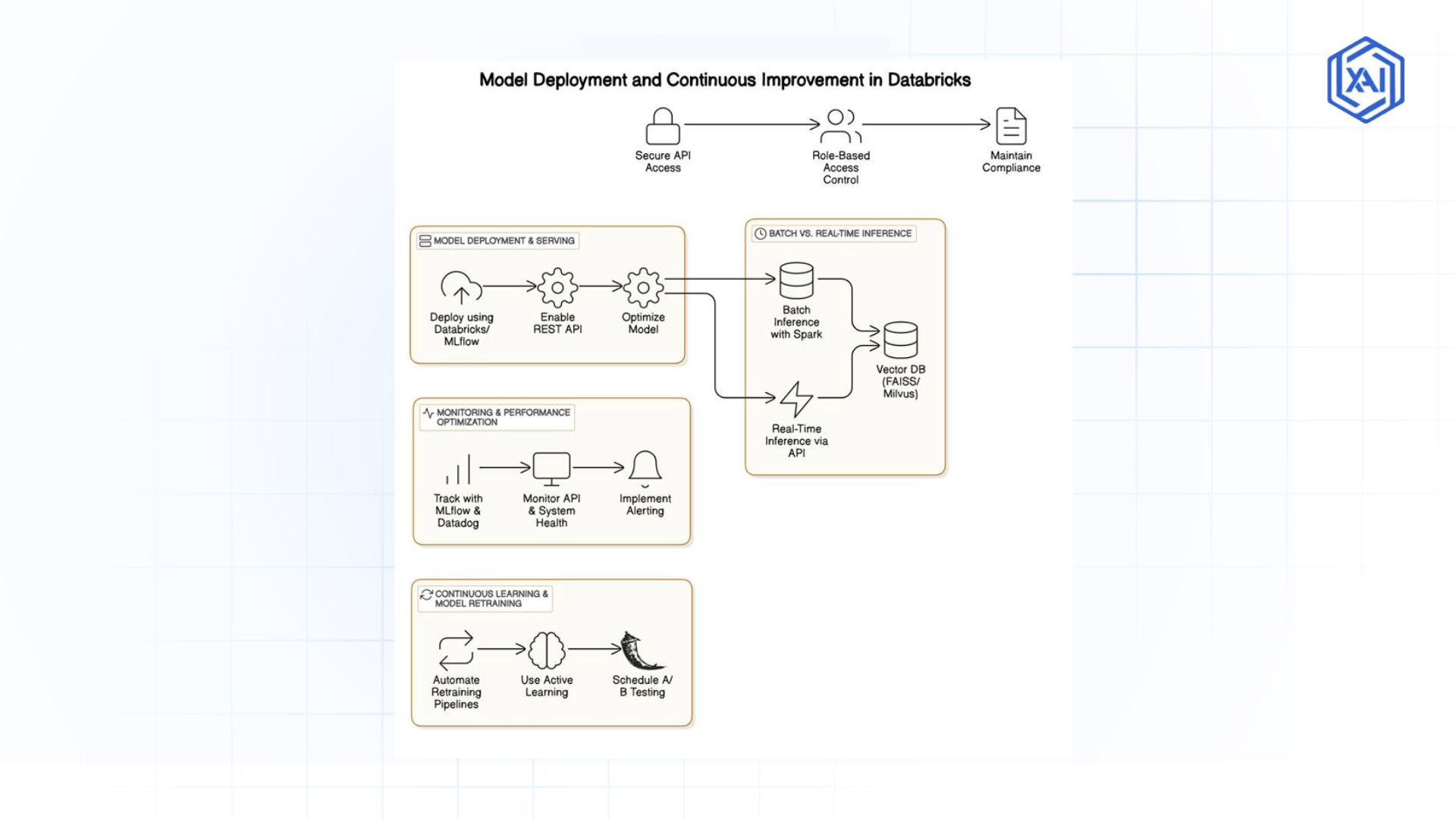 Fig 1.3: Model Deployment, Real-Time Inference & Continuous Improvement
Fig 1.3: Model Deployment, Real-Time Inference & Continuous ImprovementBest Practices and Lessons for Image Dataset Processing
Avoiding Common Pitfalls in Large-Scale Image Processing
When dealing with big data image analysis, common pitfalls can slow down pipelines or lead to inconsistent results. Some best practices include:
-
Ensuring data consistency and completeness by validating image ingestion workflows.
-
Avoiding inefficient Spark configurations that lead to memory bottlenecks or suboptimal parallel execution.
-
Using optimized image formats such as WebP or TFRecords to reduce storage overhead and improve access times.
By following best practices, organizations can achieve high-performance and scalable image processing workflows.
Data Quality and Validation for Image Datasets
Ensuring data quality and validation is critical before using images for ML models. Databricks provides automated validation techniques, including:
-
Checking for missing or corrupted image files before processing.
-
Verifying metadata completeness, such as image resolution, labels, and timestamps.
-
Implementing outlier detection to flag misclassified or incorrectly labeled images.
By integrating automated validation into Databricks Workflows, teams can maintain high-quality image datasets suitable for ML training.
Security and Compliance Considerations for Sensitive Images
Handling sensitive images, such as medical scans or personal photographs, requires strict security and compliance measures. Databricks Unity Catalog provides:
-
Encryption at rest and in transit to secure sensitive image data.
-
Audit logging and monitoring to track data access and modifications.
By implementing enterprise-grade security, organizations can ensure compliance with industry standards, such as GDPR, HIPAA, and SOC 2.
Conclusion
The Future of Image Processing and AI Integration
Databricks are pushing the boundaries of what’s possible with image data. As AI and ML keep evolving, we expect workflows to get even smarter, cheaper, and more automated. The future’s looking bright with:
-
AI doing the grunt work of labeling and annotating.
-
Hybrid cloud setups to save on storage and compute.
-
Edge processing for real-time IoT action.
-
Federated learning to train models without compromising privacy.
With Databricks in your corner, you’re ready to tackle massive image datasets and power game-changing AI solutions across the board.



























