
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
Computer vision is revolutionizing various industries, including healthcare, autonomous driving, security, and manufacturing. AI-driven applications such as facial recognition, medical image analysis, and real-time video processing depend heavily on deep learning models to interpret visual data. However, these tasks demand significant computational power, especially as datasets expand and models grow increasingly complex.
This is where parallel processing plays a key role. By allowing multiple computations to run simultaneously, it speeds up tasks like object detection and image segmentation. GPUs, especially those from NVIDIA, are designed to handle these high-performance computing needs, making them essential for efficient training and deploying AI-driven computer vision applications.
With advancements in hardware and software, parallel processing ensures that large-scale AI models can be processed more effectively, enabling the continued growth and impact of computer vision across industries.
Importance of Parallel Processing in AI Workloads
Artificial intelligence, particularly deep learning, involves massive computational workloads. These workloads consist of matrix operations, convolutions, and back propagation steps that demand high-speed data processing. Parallel processing allows multiple computations to be executed simultaneously, significantly reducing training and inference time.
Key advantages of parallel processing in AI include:
-
Faster Training and Inference: Distributes computations across multiple units, reducing training and prediction times.
-
Efficient Large-Scale Data Handling: Divides massive datasets into smaller chunks for simultaneous processing, speeding up data prep and model training.
-
Improved Scalability: Enables efficient scaling for large, complex models using multi-core processors, GPUs, or distributed systems.
-
Reduced Bottlenecks: Prevents delays by handling tasks concurrently, ensuring efficient processing without sequential bottlenecks.
Why GPUs are Essential for AI Workloads
Graphics Processing Units (GPUs) were originally designed for rendering graphics but have become indispensable for AI workloads due to their parallel computing capabilities. Unlike CPUs, which focus on sequential processing, GPUs are optimized for massive parallelism, allowing them to process thousands of operations simultaneously.
Key Characteristics of GPUs for AI
Understanding Parallel Processing in Computer Vision
Why Parallelism is Critical in Computer Vision
Computer vision tasks involve processing vast amounts of pixel data. Operations like convolution, pooling, and activation functions are highly parallelizable, making them ideal for GPU acceleration. For example:
-
Convolutional Neural Networks (CNNs): Feature extraction through convolution layers benefits from executing multiple filter operations in parallel.
-
Object Detection: Running multiple region proposals and classification steps simultaneously speeds up real-time applications.
-
Video Analysis: Processing multiple frames in parallel enables real-time inference for surveillance and autonomous systems.
Comparison of CPU vs. GPU Processing
|
Feature |
CPU |
GPU |
|
Architecture |
Few powerful cores |
Thousands of smaller cores optimized for parallelism |
|
Processing Style |
Sequential, ideal for single-threaded tasks |
Parallel, ideal for multi-threaded tasks |
|
AI Workload Performance |
Slower for large-scale deep learning tasks |
Optimized for high-speed AI computations |
|
Memory Bandwidth |
Limited, designed for general computation |
High bandwidth, designed to handle large AI datasets efficiently |
|
Power Efficiency |
Consumes more power per computation |
Higher efficiency for AI due to parallel execution |
|
Cost-Effectiveness for AI |
Less cost-effective for large-scale AI models |
More cost-effective for AI training and inference |
|
Scalability |
Limited scalability for AI |
Easily scales with multi-GPU setups (NVLink, PCIe) |
|
Software Optimization |
Optimized for general-purpose applications |
Optimized for AI frameworks like TensorFlow, PyTorch, and TensorRT |
|
Precision Support |
Primarily supports FP32 and FP64 |
Supports FP16, INT8, and specialized Tensor Cores for AI tasks |
|
Scalability |
Limited scalability, fewer cores per processor |
Easily scales with multi-GPU configurations for distributed computing |
NVIDIA GPUs: Powerhouse for AI Acceleration
CUDA Architecture and Tensor Cores
At the core of NVIDIA’s success in AI acceleration is the CUDA (Compute Unified Device Architecture), a parallel computing framework that allows developers to harness the full power of GPUs for a wide range of applications, including AI. Tensor Cores, introduced in modern NVIDIA GPUs, further enhance AI performance by optimizing matrix multiplications and deep learning workloads.
Key Features of NVIDIA GPUs for AI
-
High-Throughput Parallel Processing: With thousands of small cores, NVIDIA GPUs can process massive data in parallel, drastically reducing training and inference times and making AI applications scalable.
-
Tensor Core Acceleration for Deep Learning: Tensor Cores are specialized for deep learning, accelerating matrix operations like tensor multiplications and speeding up model training, especially for large neural networks.
-
Multi-GPU and NVLink Support for Scalability: NVLink technology connects multiple GPUs, allowing deep learning workloads to be distributed across them, enabling efficient processing of larger models and datasets.
-
FP16 and FP32 Precision for Optimized Performance: Supporting FP32 and FP16 precision, NVIDIA GPUs enable faster computations with minimal accuracy loss, which is crucial for both speed and precision in deep learning tasks.
Popular NVIDIA GPU Series for AI Workloads
NVIDIA A100
NVIDIA RTX 4090
NVIDIA Jetson Series
NVIDIA L4 & L40

Optimizing AI Workloads with NVIDIA GPUs
Data Parallelism vs. Model Parallelism
-
Data Parallelism: Large datasets are split into smaller batches and distributed across multiple GPUs. Each GPU processes a portion of the data independently, speeding up tasks like training on large datasets. It's commonly used in tasks like image classification or natural language processing.
-
Model Parallelism: Large models are split across multiple GPUs, with each GPU handling a different layer or part of the model. This is useful for training large models that can't fit into a single GPU’s memory, such as large transformers or deep convolutional networks.
Multi-GPU Scaling Strategies
-
Multi-GPU Training: Uses multiple GPUs to train a single model faster. Tools like Horovod and PyTorch Distributed allow efficient distributed training, improving scalability and reducing training time.
-
NVLink & PCIe Communication: NVLink provides high-bandwidth, low-latency connections between GPUs for faster data transfer. PCIe Gen 4 also helps improve communication speed, ensuring smooth multi-GPU setups and avoiding bottlenecks.
Memory Management and Performance Tuning
-
Mixed Precision Training: Uses lower precision (e.g., FP16) instead of full precision (FP32) to reduce memory usage, enabling faster computation and allowing large models to fit into memory-constrained environments without sacrificing accuracy.
-
Memory Overlapping: This technique loads data into memory while executing computations on previously loaded data, minimizing idle GPU time and improving overall training and inference efficiency.
NVIDIA Software Ecosystem for AI Applications
CUDA, cuDNN, and TensorRT
-
CUDA: A parallel computing platform that allows developers to harness the full power of NVIDIA GPUs for AI, machine learning, and scientific computing. It enables fast training and inference by parallelizing tasks across the GPU.
-
cuDNN: A highly optimized library for deep learning operations (e.g., convolution, pooling). It accelerates deep neural network training and inference, particularly for frameworks like TensorFlow and PyTorch.
-
TensorRT: A high-performance inference optimizer for reducing latency and improving efficiency in real-time AI applications. It's ideal for deployment in production environments like autonomous driving and robotics.
DeepStream for Computer Vision
-
Smart Surveillance: Real-time object detection, face recognition, and behavior analysis for improved security.
-
Autonomous Driving: Real-time processing of camera and sensor data for object detection, lane tracking, and decision-making.
-
Industrial Automation: Enhances defect detection and quality control with real-time video analysis on production lines.
Integration with AI Frameworks
TensorFlow (TF-TRT)
NVIDIA’s TensorRT integration with TensorFlow optimizes inference for faster, low-latency AI applications.
PyTorch (TorchScript & NVIDIA Apex)
Optimizations like TorchScript for production-ready models and NVIDIA Apex for mixed-precision training improve performance and reduce memory usage.
ONNX Runtime
Supports cross-framework AI model execution, allowing models trained in different frameworks (like TensorFlow and PyTorch) to run efficiently on NVIDIA GPUs, enabling easy model transfer between platforms.
AI in Action: Case Studies on GPU Acceleration
Real-World Applications Using NVIDIA GPUs
-
Tesla’s Autopilot: NVIDIA GPUs process data from Tesla’s sensors in real-time, enabling fast object detection and decision-making for autonomous driving.
-
Healthcare AI (NVIDIA Clara): Clara uses GPUs for fast medical image processing, helping detect conditions like cancer and heart disease more efficiently.
-
Industrial Automation: GPUs power AI systems for defect detection and quality control in manufacturing, improving efficiency and reducing manual inspection.
Performance Benchmarks
A100 vs. RTX 4090 for AI Inference
The NVIDIA A100 is ideal for large-scale AI training in data centers, handling massive workloads with Tensor Cores and multiple precision support. It excels in research and production environments for large models, such as NLP, image recognition, and recommendation systems.
The RTX 4090, while not as scalable as the A100, offers excellent performance for smaller-scale AI research and training, making it a more affordable option for researchers and small enterprises.
FP16 vs. FP32 Training Speed
FP16 (16-bit floating point) enables faster training times by reducing memory usage, allowing GPUs to process more data in parallel. This is ideal for large datasets and deep neural networks. Both the A100 and RTX 4090 support FP16, making them efficient for deep learning tasks requiring both speed and memory efficiency.
FP32 (32-bit floating point) offers greater precision but results in slower training times and higher memory usage, making FP16 the preferred choice for many deep-learning applications.
Future of GPU Acceleration in AI Workloads
Emerging Technologies and Trends
-
AI-Optimized GPUs with More Tensor Cores: Next-gen NVIDIA GPUs will feature more Tensor Cores to speed up deep learning tasks, enhancing performance for complex AI models like NLP, image/video analysis, and large data processing.
-
Edge AI with Jetson Nano and Orin: Jetson platforms enable AI processing on edge devices like robots and drones, offering real-time capabilities without cloud dependency, which is ideal for industries like autonomous vehicles and healthcare.
-
NVIDIA Grace Hopper CPU-GPU Hybrid: The Grace Hopper system combines Grace CPU and Hopper GPU, optimizing AI workloads for faster, more efficient processing, which is ideal for data centers and AI industries.
NVIDIA GPU AI Workload Processing Flow
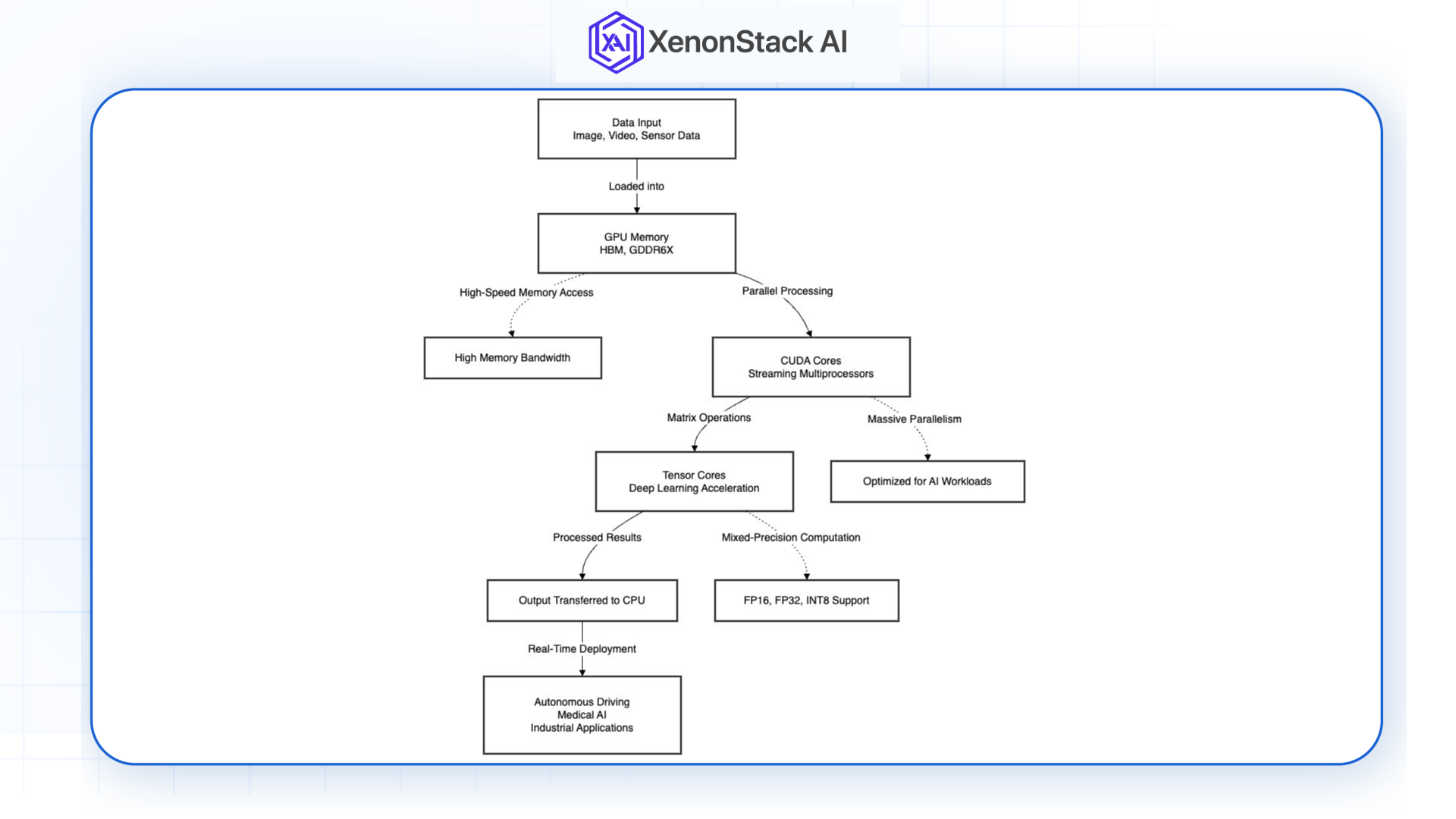 Fig 1: NVIDIA GPU AI Workload Processing Flow Architecture Diagram
Fig 1: NVIDIA GPU AI Workload Processing Flow Architecture Diagram-
Data Loaded into GPU Memory: Input data (images, videos, sensor data) is loaded into high-speed GPU memory (HBM or GDDR6X) for fast access during computations.
-
Parallel Processing Across CUDA Cores: The data is split into smaller tasks, processed simultaneously by CUDA cores, performing operations like matrix multiplications and convolutions for training and inference.
-
Tensor Cores for Matrix Operations: Tensor Cores accelerate deep learning tasks by performing high-speed matrix multiplications using mixed-precision arithmetic, boosting performance and reducing latency.
-
Output Transferred to CPU for Deployment: Once computations are complete, the results are sent back to the CPU for further processing or deployment, such as in real-time applications like autonomous systems or medical diagnostics.
How Parallel Processing is Optimized in NVIDIA Architecture
High-Speed Memory Transfer (HBM, GDDR6X)
NVIDIA GPUs use HBM and GDDR6X memory to enable fast data transfer, ensuring large datasets are handled efficiently. With high data throughput, these memory types prevent bottlenecks and accelerate training and inference by quickly fetching data for processing.
Optimized Compute Pipelines for AI Inference
NVIDIA GPUs feature compute pipelines optimized for AI tasks, including matrix multiplications, activation functions, and gradient computations. These optimizations reduce latency and boost throughput, enabling efficient real-time AI inference and supporting both training and inference phases.
NVIDIA GPUs, with their parallel computing power, accelerate AI workloads through specialized hardware like Tensor Cores and high-bandwidth memory. These GPUs help speed up complex tasks in healthcare, autonomous driving, and industrial automation, pushing AI capabilities to new limits.
Choosing the right GPU
-
A100 for enterprise-level AI and large-scale applications.
-
RTX 4090 for research and smaller-scale projects.
-
Jetson for edge AI and real-time processing in low-power environments.



























