
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)
The field of Computer Vision has seen significant advancements over the years, with Convolutional Neural Networks (CNNs) being the go-to architecture for most image-based tasks. However, a newer architecture known as Vision Transformers (ViTs) has been making waves in the deep learning community, offering an alternative to CNNs. In this blog, we’ll explore how ViTs compare with CNNs, their applications in image classification and segmentation, and their performance benchmarks.
Vision Transformers (ViTs) vs Convolutional Neural Networks (CNNs)
Architecture
-
CNNs: CNNs are based on convolutional layers that apply filters to small sections of an image. These layers capture spatial hierarchies (local-to-global features) by progressively combining features from smaller patches to form the entire image. This is why CNNs are highly efficient at extracting local patterns like edges, textures, and shapes.
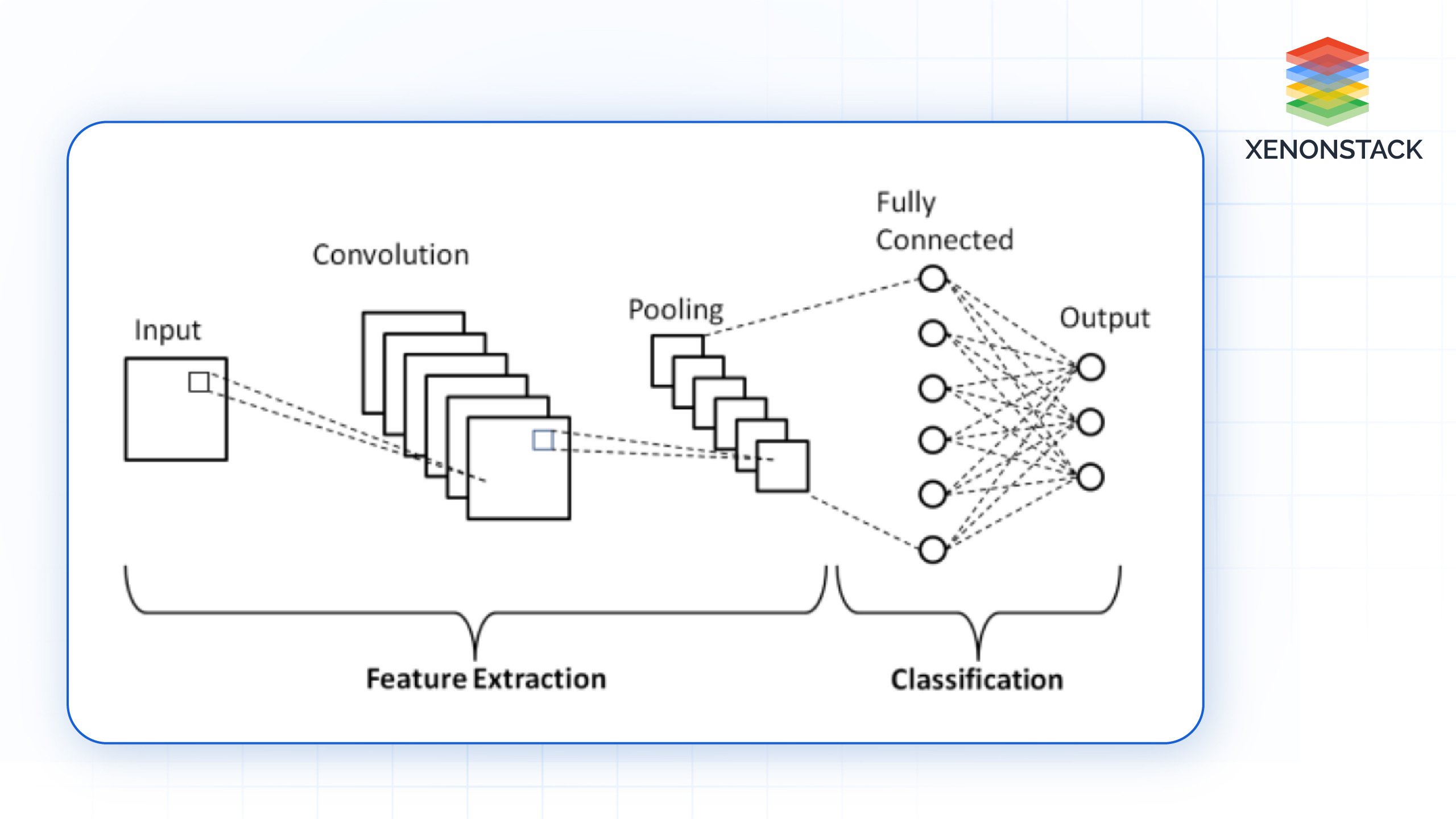
Fig 1.0: Architecture of a basic CNN
-
ViTs: Vision Transformers are based on the Transformer architecture, originally designed for Natural Language Processing (NLP). ViTs divide an image into fixed-size patches and treat each patch as a token, similar to words in NLP tasks. The patches are then passed through transformer layers where self-attention mechanisms enable long-range dependencies across the entire image.

Fig 2.0: ViT Architecture
Strengths and Limitations
-
CNNs are particularly good at dealing with imagery data because they can compute the local dependencies fast and efficiently. Yet, they are disadvantaged at long-range dependencies because of the localized aspects of convolution operations.
-
Self-attention mechanisms make ViTs ride the benefits of visual understanding of long-range dependencies from the get-go. This makes their approach afford them a great advantage in interpreting context in images at the global level. Nevertheless, ViTs have higher accuracy compared to CNNs only in many cases, need a large amount of labeled data as well and are more computationally expensive.
Training Efficiency
-
Generally, CNN enjoys much shorter learning time. The good thing about convolutions is that they capture local patterns with a small number of parameters.
-
However, ViTs are data hungry, require large (e.g., ImageNet) training data, and perform the best. For optimal results, pretraining from a massive dataset is often required before fine-tuning from a smaller dataset.
AI-based Video Analytics's primary goal is to detect temporal and spatial events in videos automatically. Click to explore our, AI-based Video Analytics
Applications of Vision Transformers (ViTs)
Image Classification
ViTs have demonstrated strong performance in image classification tasks, competing with or even surpassing CNNs in some benchmarks. They excel at learning from large datasets and can capture complex patterns that require global context.
-
Example Application: ViTs can be used in Medical Image Analysis, where understanding the global context of an image is crucial. For instance, in radiology, a ViT can examine an X-ray or MRI scan to detect anomalies that may not be localized to a specific region.
Image Segmentation
Segmentation tasks benefit greatly from ViTs’ ability to process global information. Unlike CNNs, which may struggle with understanding large-scale structures in an image, ViTs can more easily learn long-range spatial relationships, which is critical for precise object segmentation.
-
Example Application: In autonomous driving, ViTs can assist in segmenting road scenes, identifying lanes, pedestrians, and obstacles. The self-attention mechanism in ViTs allows the model to grasp the entire scene, enabling better segmentation decisions in complex environments.
Object Detection
ViTs are increasingly being adapted for object detection tasks, where they can outperform traditional CNN-based models in scenarios where context is crucial. For instance, detecting small objects or objects that are spatially far apart can benefit from ViTs' ability to capture long-range dependencies.
-
Example Application: Surveillance systems using ViTs can track and detect objects across wide camera angles, ensuring that even objects far from the center of the frame are recognized with precision.

Fig 3.0: ViT in Object Detection
Performance Benchmarks of ViTs
ImageNet Benchmark
ViTs have been tested on the ImageNet dataset, one of the most widely used datasets for image classification. Initially, ViTs struggled to match CNNs when trained on small datasets. However, when pretrained on larger datasets and fine-tuned, ViTs outperformed CNNs like ResNet and EfficientNet in terms of accuracy.
- CNNs: ResNet-50 achieves about 76% accuracy on ImageNet.
- ViTs: ViT-Large, pretrained on JFT-300M, achieves over 88% accuracy on ImageNet.
Computational Complexity
One of the challenges with ViTs is their high computational cost. While CNNs like ResNet and MobileNet are optimized for lower compute environments, ViTs require more resources, especially for large-scale image processing tasks.
-
CNNs: EfficientNet-B7 offers a strong balance between accuracy and computational efficiency.
-
ViTs: The larger ViT models require more compute and memory, making them less suitable for edge devices but extremely powerful when used in server environments with ample computational resources.
Training Time
ViTs require longer training times due to their high parameter count and need for larger datasets. However, once trained, they can generalize well to new tasks with minimal fine-tuning, especially in transfer learning scenarios.
Face Recognition uses Computer Algorithms to identify specific features of a person's face. Click to learn more about our Face Recognition and Detection solutions
Future Prospects of Vision Transformers (ViTs)
The development of Vision Transformers (ViTs) represents a significant breakthrough in computer vision, offering new opportunities that could reshape how we approach visual tasks. As these models evolve, their future potential spans various fields and applications:
Efficiency and Accessibility
-
Current Challenges: One of the main challenges of ViTs is their demand for large datasets and computational resources. However, ongoing research focuses on improving the efficiency of Vision Transformers, making them lighter and more accessible for broader use.
-
Future Optimizations: With improvements in model optimization, ViTs can become more practical for a wider range of industries, even those with limited resources. These optimizations will likely make ViTs a strong competitor to CNNs in both low-power and high-performance applications.
Broader Application Domains
As ViTs become more efficient, they are expected to outperform CNNs in a variety of new applications beyond traditional tasks like image classification. Some areas where ViTs will likely expand include:
-
Image Synthesis: For tasks in which new images need to be generated from scratch, ViTs could make a huge difference, such as generating photorealistic images, deep fake generation, or generative art.
-
Video Processing: Video tasks require understanding complex temporal dynamics, and ViTs’ ability to capture long-range dependencies makes them well-suited for video analysis, object tracking, and action recognition in dynamic scenes.
-
Multimodal Learning: ViTs can be combined with models handling other data types (e.g., text) to perform multimodal learning. For instance, by combining ViTs with NLP models, such as language models, for predicting the desired text present in an image, one can combine the strengths of both tasks for image capturing, captioning, question answering, and so on.
Potential in Complex Vision Tasks
ViTs excel at learning long-range dependencies, giving them an edge over CNNs in tasks where understanding the global context is crucial. Their ability to analyze and interpret complex spatial relationships in images makes them particularly promising for:
.png?width=512&height=512&name=brain-imaging%20(1).png)
Medical Imaging
ViTs are useful for analyzing complex medical scans, where understanding the global context is critical for diagnosing diseases or detecting patterns that cover extensive regions of an image

Autonomous Systems
ViTs will be able to understand wide ranging visual environments in fields such as autonomy driving, detecting obstacles, lane markings and pedestrians accurately even in challenging situations
Revolutionizing Vision-Language Models
ViTs have one of the most exciting potential uses because they promise a new generation of vision language models. With multimodal learning becoming increasingly popular, ViTs can be combined with BERT or GPT for the task of visual understanding combined with text reading.
This is key for:

Interactive AI
Systems that can both see and communicate, such as AI personal assistants that understand images and text together, or smart robots that can interpret visual environments and respond to verbal commands

AR & VR
Vision Transformers (ViTs) excel in understanding complex visual scenes and processing language, making them perfect for AR and VR applications where users engage with both visual and verbal information seamlessly
Conclusion
Vision Transformers (ViTs) represent a promising alternative to CNNs, especially in tasks requiring a deep understanding of global context. While they are computationally expensive and data-hungry, their superior performance in certain benchmarks highlights their potential to become the next dominant architecture in computer vision. As more efficient variants are developed and training techniques improve, ViTs will likely play an increasingly central role in image classification, segmentation, and beyond.




























