

Visual recognition has become one of the essential building blocks in AI applications, from a search engine that uses images to a self-driving car. Out of the different methodologies applied to visual recognition, Zero-Shot Learning (ZSL) is one of the most appealing as it enables the model to recognize classes on which it was never trained. This blog focuses on ZSL for visual recognition and examines its history, progress, issues, and potential for the future.
What is Zero Shot Learning (ZSL)?
Zero-shot learning (ZSL) is a machine learning approach where an AI model can identify and classify objects or concepts without any prior exposure to examples from those specific categories.
 In contrast, most advanced deep learning models for classification or regression rely on supervised learning, which demands numerous labeled examples from relevant data classes. These models learn by predicting outcomes based on labeled training datasets, where the labels define both the set of possible answers and the correct answer (ground truth) for each instance. Techniques like Vision Transformers (ViTs) improve feature extraction, while Neural Architecture Search (NAS) optimizes model design. However, these models are susceptible to Robustness and Adversarial Attacks in Computer Vision.
In contrast, most advanced deep learning models for classification or regression rely on supervised learning, which demands numerous labeled examples from relevant data classes. These models learn by predicting outcomes based on labeled training datasets, where the labels define both the set of possible answers and the correct answer (ground truth) for each instance. Techniques like Vision Transformers (ViTs) improve feature extraction, while Neural Architecture Search (NAS) optimizes model design. However, these models are susceptible to Robustness and Adversarial Attacks in Computer Vision.
The learning process involves adjusting the model's weights to minimize the difference between its predictions and the ground truth. Generative Adversarial Networks (GANs) for Image Synthesis help generate additional training data, supporting areas like 3D Vision in Computer Vision and Augmented Reality (AR) and Virtual Reality (VR). Achieving this requires sufficient labeled samples to perform multiple rounds of training and refinement.
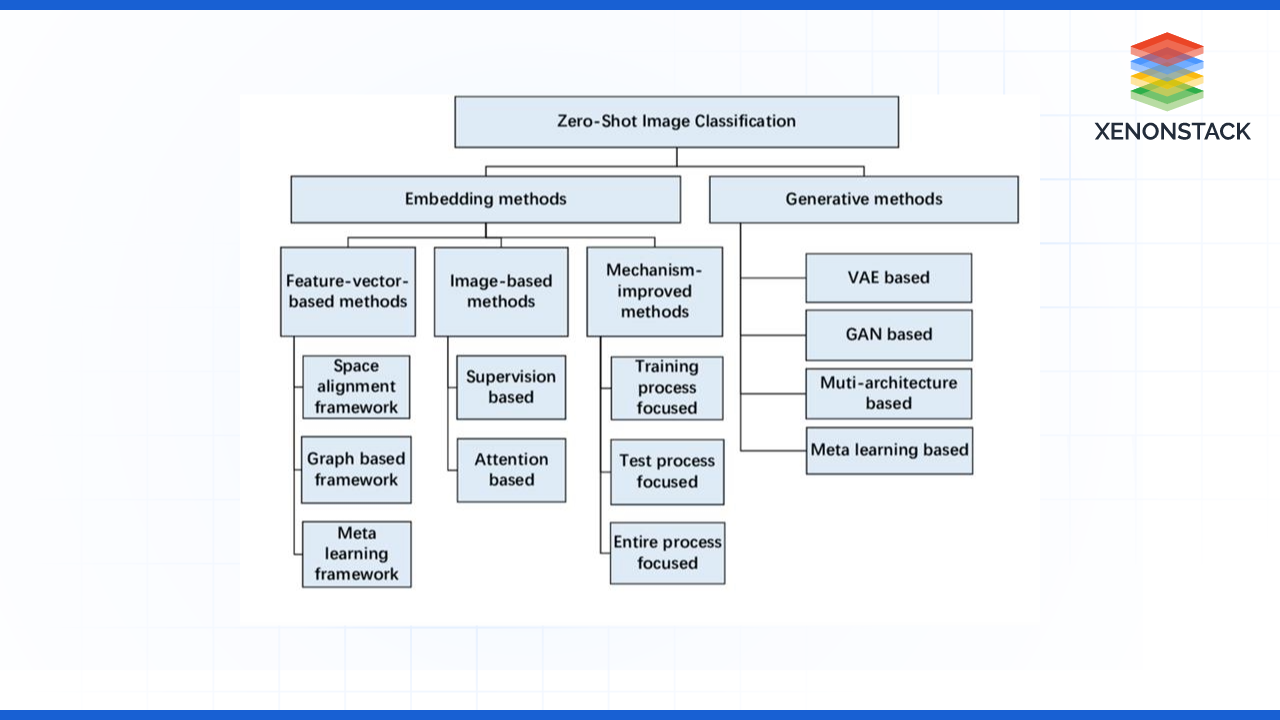
History of Zero-Shot Learning
It was only about 7-8 years ago that the idea of Zero-Shot Learning was first brought up. In the early literature, Lampert et al. (2009) used semantic attributes to try solve the problem of transferring knowledge between seen and unseen classes. The initial models utilized a two-stage approach: learning of graphics for known classes and associating these graphics to semantic spaces. It made the ground work for the future developments to take place in the field.
Early Approaches to Zero-Shot Learning
-
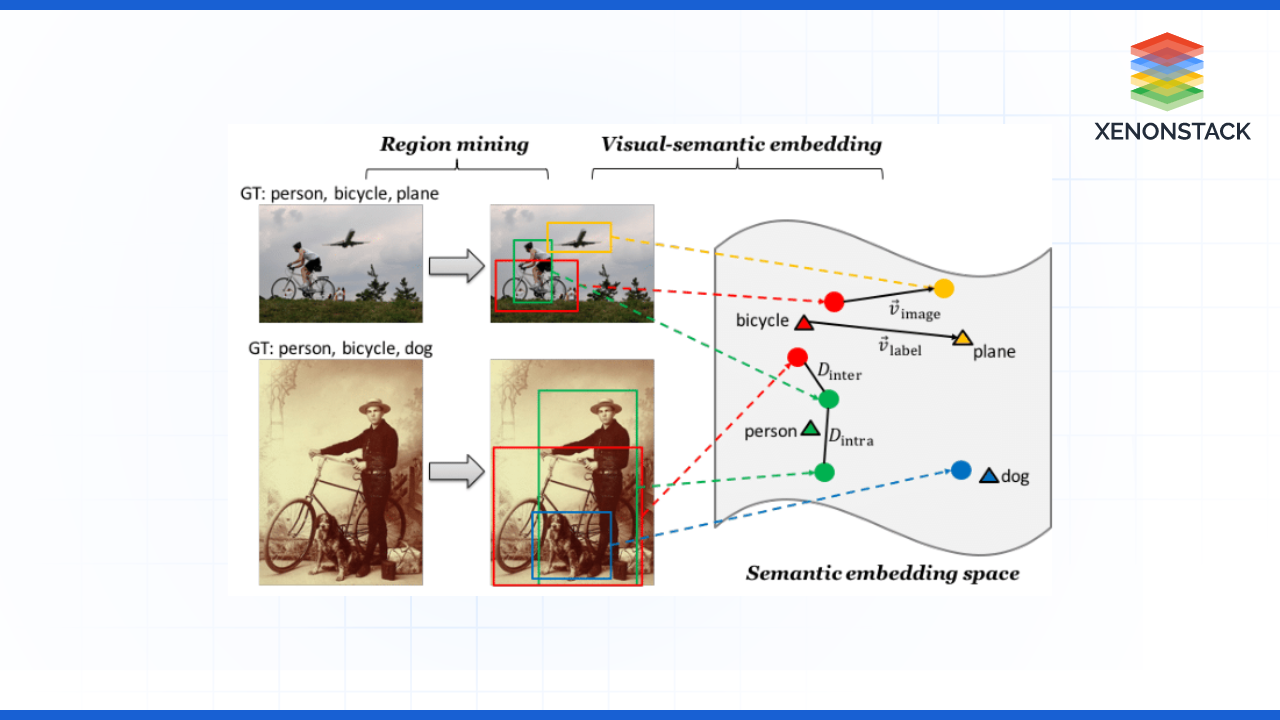
Semantic Embeddings: Of the two earlier methodologies, the first required the use of semantic attributes such as the color or shape of the objects. These attributes acted as a connector between the seen and unseen categories.
-
Heterogeneous Data: In some models, extra information – textual descriptions of the objects – was included to improve the recognition features.
Key Advancements in Zero-Shot Learning
ZSL research has been most active in the last decade due to progress in deep learning techniques and transfer learning.
Deep Learning Era
The new success story in ZSL emerged around 2012 with the advent of deep learning. The use of CNNs allowed the extraction of a massive view of features during the learning process, thus allowing the mapping of images into semantic spaces.
Notable Techniques
-
Attribute-Based Learning: There were some models, such as DeViSE (Deep Visual-Semantic Embedding), proposed by Frome et al. in 2013, that were able to map directly between the features of the images and word embeddings the contribution that improves predictive performance on the unseen classes.
-
Generative Models: Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) have been pioneered in the synthesis of features for unseen classes, which improve the learning process.
-
Graph-Based Methods: In new methods, class relations are enriched through KGs, and classification performance is also augmented.
Major Challenges in Zero-Shot Learning
Despite its advancements, ZSL still faces several challenges:
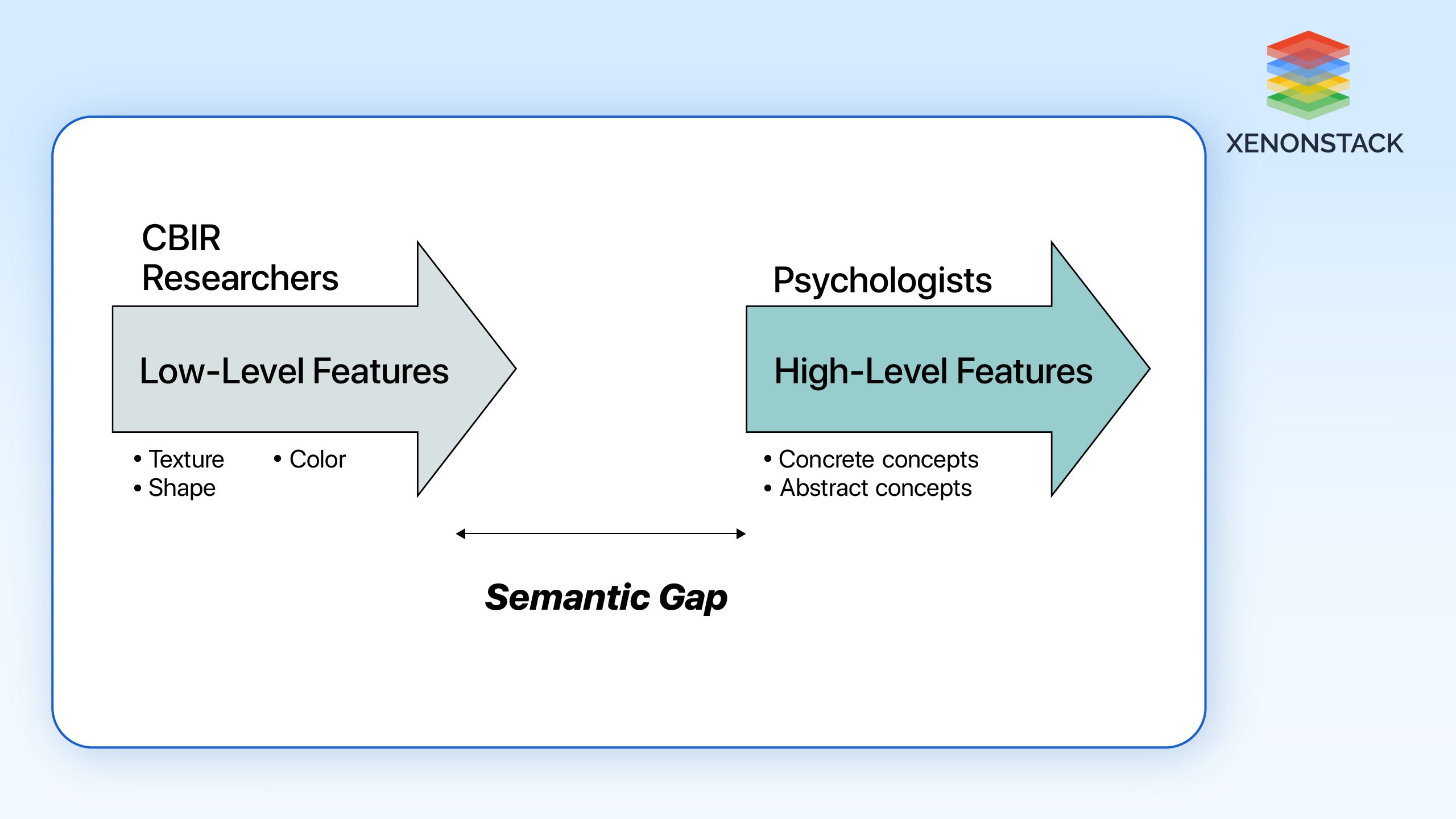
Semantic Gap
The association between the visual features and semantic attributes is not always crisp and clear, which becomes the main problem when it comes to identifying new classes.
Bias in Seen Classes
When training these models with a few seen classes, they learn biases in the categories they have been exposed to.
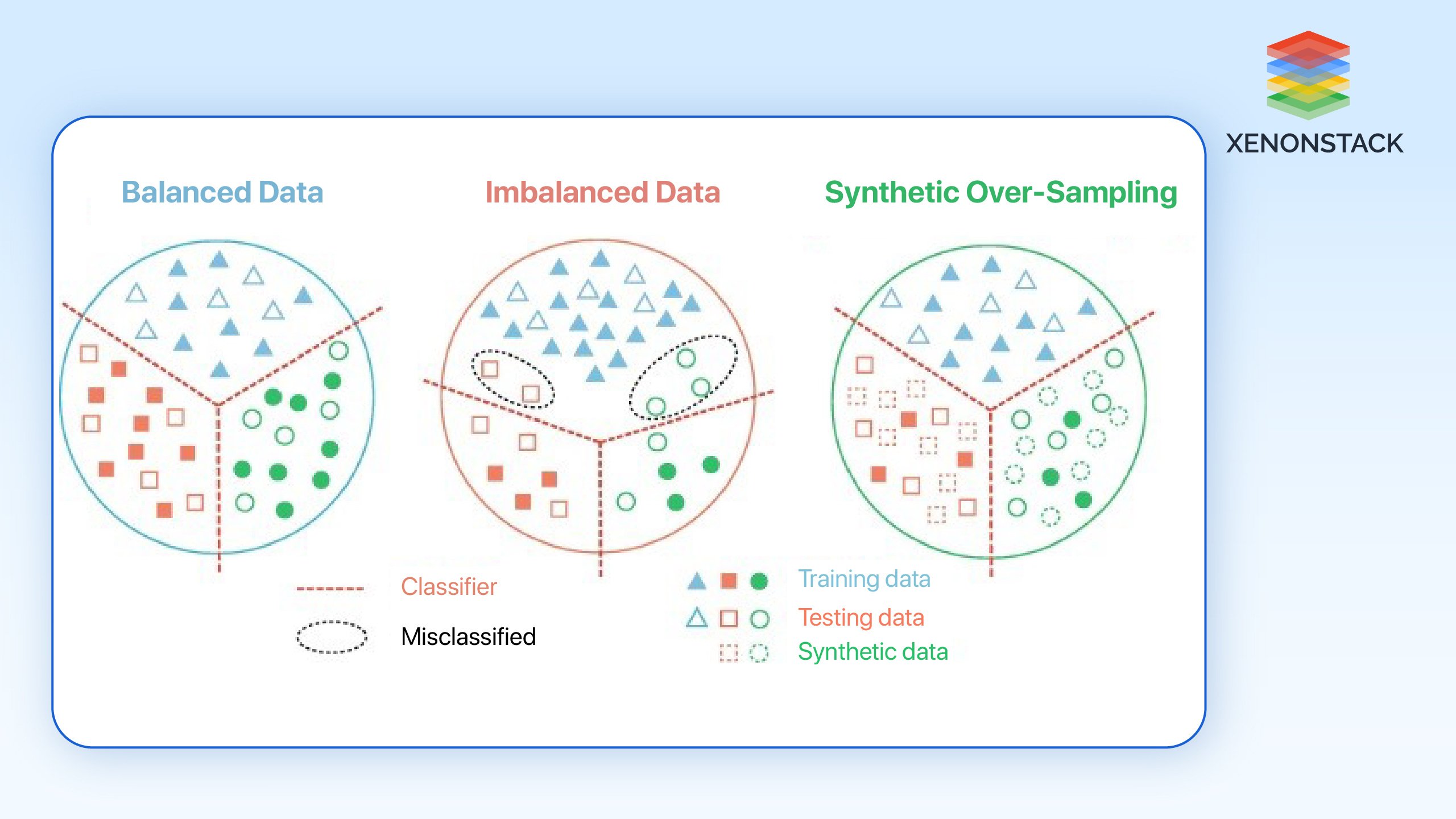
Data Imbalance
The fact that unseen classes have inputs, unlike seen classes, can pose a problem because models cannot learn as desired when the former is scarce.
Effective Solutions to Zero-Shot Learning Challenges
-
Enhanced Attribute Learning: Thus, the changes made to the attributes' definitions and representation methods ensure that the models effectively overcome the challenges posed by the semantic gap.
-
Meta-Learning: We also find that methods like few-shot learning can be integrated into ZSL, improving the model's performance even with limited data.
-
Regularization Techniques: In turn, applying techniques that belong to the regularization methods group can minimize such an issue and provide a better generalization to classes that have not been seen during training and validation
Top Algorithms and Mathematical Foundations of ZSL
Zero-shot learning can be mathematically formalized using various algorithms. Below are some key models and their formulas:
Direct Attribute Prediction (DAP)
Overview: DAP revolves around identifying a set of predetermined features in every image. Once performance on the attributes is predicted, it is related to unseen classes according to its attribute representation.
Loss Function: The aim here is to reduce the error between the predicted attributes, namely, pared and ground truth attributes.
.png?width=398&height=90&name=undefined%20(5).png)
Deep Visual-Semantic Embedding (DeViSE)
Overview: This algorithm uses a deep learning architecture to map visual features directly to a semantic space defined by word embeddings. It is effective for recognizing unseen classes by utilizing their semantic descriptions.
Loss Function: The goal is to maximize the cosine similarity between the visual feature 𝑣 and the corresponding word vector 𝑤.
.png?width=316&height=86&name=undefined%20(6).png)
Attribute Classifier (AC)
Overview: The Attribute Classifier approach focuses on training classifiers separately for each attribute. The grouping of its attributes or characteristics then identifies every unseen class.
Output: The classifier’s output for an input image image 𝑥 is the probabilities of each attribute 𝐴j.
.png?width=316&height=55&name=undefined%20(7).png)
Where 𝜎 is the sigmoid function, and 𝑊j is the weights attribute 𝐴j:𝜙(𝑥) is the abstract of image x.
Generative Adversarial Networks (GANs) for ZSL
Overview: GANs can learn the distribution of attributes and generate synthetic samples for unseen classes. This is especially applicable when expanding the training data set.
Objective Function: GAN is formed using a generator, G, and a discriminator, D. The generator seeks to generate a realistic image from an attribute vector.
.png?width=591&height=50&name=undefined%20(8).png)
Graph Neural Networks (GNNs)
Overview: Although some of them do not have significant connections, GNNs can model the relationships between classes and attributes. In the construction of a graph, where nodes are considered as classes, and the edges are attributes, GNNs augment the learning of dependencies.
Node Representation Update: The vector representation of node i in tth iteration is updated based on its neighbors N(I).
.png?width=442&height=52&name=undefined%20(9).png)
AGGREGATE is a function that aggregates the features of the neighboring nodes, and W(t) is a learnable weight matrix during iteration t.
Latest Trends and Innovations in Zero-Shot Learning
The landscape of ZSL is continuously evolving, with several emerging trends:
-
Cross-Modal Learning: Combination of text, images, and audio to effectively improve the ability to recognize the scenes.
-
Transfer Learning: Applying the results of pre-training from other related fields to improve ZSL performance.
-
Attention Mechanisms: Utilizing attention models to focus on relevant parts of images or attributes, improving classification accuracy.

The Future of Zero-Shot Learning: What's Next?
There remains great potential for future application of ZSL in visual recognition. With the ongoing research, we can expect:
-
Better Generalization: Modern advances in attribute extraction and Semantic Web understanding will make it feasible to generalize effectively to unseen classes.
-
Real-World Applications: Improved efficiency in missions that involve capturing data from the outside world, where it is difficult to come across a large amount of labeled data, such as medical image analysis and wildlife tracking.
-
Integration with Other AI Disciplines: Its integration with other fields, such as reinforcement learning, may result in new uses that have not been considered.
The Impact of Zero-Shot Learning
Zero-shot learning for visual recognition is a revolutionary advancement in how machines understand the world and its objects. Since ZSL allows models to predict previously unidentified classes, new prospects are developed for different fields. There are still many unresolved issues. However, further investigation and improvements in the field contribute to continually improving its abilities.
Looking forward, we expect that Zero-Shot Learning will be one of the key tools to progress artificial intelligence further and help bring into the world a more flexible and capable model for comprehending the details of the world seen through the lens.



