
.webp?width=1921&height=622&name=usecase-banner%20(1).webp)

Introduction to DevOps: A Modern Approach to Software Development
The two terms "Big-Data" and "DevOps" are the two buzzwords in the tech - world, with large volumes of data being generated every day. It becomes challenging for data engineers to manage, deliver, and respond to changes quickly as per business requirements. On the contrary, cloud computing and DevOps practices promise automation of processes within the software development lifecycle, reducing management costs and increasing delivery frequency. Let's outline a few DevOps best practices that a data engineer must know to overcome the challenges faced while handling data.
DevOps assembly lines help us to automate and scale end-to-end workflows of application across all teams and tools, which enable continuous delivery. Click to read about DevOps Assembly Lines and CI Pipelines
What is DevOps? Understanding the Concept and Methodology
DevOps combines cultural principles, processes, and technologies that increase an organization's ability to deliver high-speed applications and services. DevOps allows for the evolution and improvement of products more quickly than traditional software development and infrastructure management methods. Organizations can serve their clients and compete as a result of their speed.
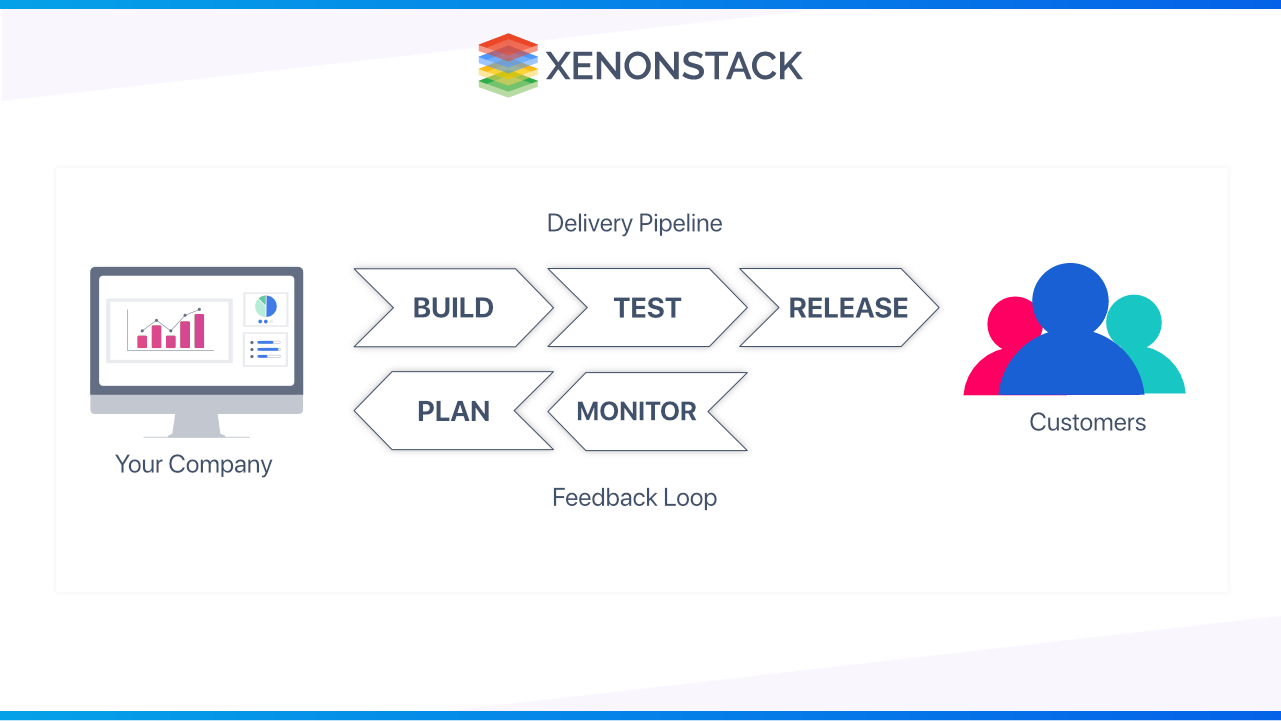
The Significance of DevOps in Today's Software Landscape
- Software and the Internet have altered the environment and sectors in which we live, from commerce to entertainment to finance. Software is no longer merely a way of sustaining a corporation; it has become an integral part of all aspects.
- Nowadays, Companies engage with their customers with software that is available as internet services or apps and may be utilized on various devices.
- They also use software to increase operational efficiencies across the whole value chain, including logistics, communications, and operations.
- Companies in today's environment must change how they develop and distribute software in the same way that physical goods companies used industrial automation to transform how they design, build, and transport things throughout the twentieth century. How does DevOps work?
- Development and operations teams are no longer "silos" in a DevOps setup. These two teams are sometimes combined into one. The engineers have to work across the whole application lifecycle, from development to testing to deployment and operations, and successfully develop a diverse set of abilities that aren't limited to a single role.
- Now Quality assurance and security teams may become more closely linked with development and operations and throughout the application lifecycle in some DevOps models. When everyone in a DevOps team is focused on security, this is referred to as DevSecOps.
- These groups employ best practices for automating procedures that were previously manual and slow. They employ a technological stack and infrastructure to swiftly and reliably operate and evolve apps.
- These tools also assist engineers in independently completing tasks (such as deploying code or supplying infrastructure) that would ordinarily require assistance from other teams, hence increasing a team's velocity.
A data strategy is frequently thought of as a technical exercise, but a modern and comprehensive data strategy is a plan that defines people, processes, and technology. Discover more about 7 Essential Elements of Data Strategy
Best Practices for Implementing DevOps as a Data Engineer
The DevOps Best Practices for Data Engineers are explained below:
CI/CD Pipeline
- The two most integral parts of development are deployment and testing. Continuous integration (CI) is the process of building and testing the application regularly.
- In contrast, continuous delivery(CD) refers to automated bug testing, uploading code to the repository, and constantly deploying changes in the repository to the production environment.
- Adopting the CI/CD process is becoming a standard for Big data companies. It helps them plan for better software updates, Streamlines data-related processes, and continuous analytics.
Configuration Management
- Configuring and managing the environment hosting the Application is known as configuration management.
- A development pipeline requires numerous environments for jobs like load testing, integration testing, acceptance testing, and unit testing. These environments become extremely complex as the testing process moves towards the production environment.
- Proper configuration management ensures optimal configurations for these environments are maintained throughout the cycle. The three main configuration management components are Configuration Control, Configuration Identification, and Configuration Audit.
The two most prominent outcomes of configuration management are:-
- Infrastructure-as-a-code (IaaC) - Code that configures the necessary environment so that it is ready for deployment.
- Configuration-as-a-code (CaaC) - Code that can configure any computing resource like a server.
User Containers
- Containers are comparable to virtual machines in that they allow software from various systems to operate on multiple servers, and they also allow programs to run alongside libraries and dependencies.
- On the other hand, Containers convey their software system and use the core operating system as their base, whereas VMs imitate a physical system.
- The benefits of using containers are Increased portability, minimum overhead, consistent operation, Greater efficiency, and Better application development. Minimum overhead.
Cluster Management Tools (Kubernetes)
- Controlling a large number of containers has various challenges. Containers and resources must be matched. Failures must be dealt with as quickly as feasible.
- These issues have resulted in a surge in demand for cluster management and orchestration software. Let's look at one of the most popular orchestration and cluster management tools.
- Kubernetes is an open-source container orchestration technology that automates many manual procedures associated with containerized application deployment, management, and scalability.
- Kubernetes enables enterprises to deploy distributed apps in containers. This involves deploying the containerized application on the K8 cluster and maintaining the cluster.
Using Repository Manager
- With a specialized server program known as a 'repository manager,' the work of managing access to all the public repositories and components utilized by development teams can be simplified and hastened. A repository manager can proxy distant repositories and cache and host components locally.
- The strength of a public repository, such as the Maven Central Repository, is brought into the enterprise by using a repository manager.
- Some of the advantages of using a repository manager are Time-savings and increased performance, Improved build stability, Reduced build times, Better quality software, Simplified development environment.
Service Tags on Jobs and processes for cost Management
- Tags (also known as labels) are a type of custom information provided to resources that your company can use in various ways.
- Tags let you differentiate and divide costs between various components of your environment for an accurate view of your cost data in the context of cost management, filling the gap between business logic and the resource.
- This enables you to assign organizational-specific details to aid in later information processing.
Rapid Elasticity and Scalability
- Elasticity is defined as the ability to dynamically extend or decrease infrastructure resources as needed to adjust to workload changes in an autonomous manner while maximizing resource utilization.
- Scalability refers to expanding task size while maintaining performance on existing infrastructure (software/hardware).
- Some cloud services are adaptable solutions because they provide both scalability and elasticity. Opting for these services enables Big Data cloud resources to be rapidly, elastically, and automatically scaled out up, out, and down on demand.
- Adopt microservices-based architecture and software to allow the interflow of structured & unstructured data.
- The concept behind the microservice architecture is to create your application as a collection of discrete services rather than a single huge codebase (commonly referred to as a monolith).
- Rather than relying on huge databases to access most of your data, communication is frequently handled through API calls between services, with each service having its lightweight database.
- If appropriately implemented in combination with best practices of microservices, it offers many benefits to a data engineer, such as
- Fast and easy deployment process, Use of different technology stacks and programming languages, better Failure detection, better continuous integration, and deployment.
The companies that support remote working are growing, and this new working approach had an impact on DevOps culture. Discover here about Top DevOps Trends for 2023
Cloud-Based ETL
ETL stands for extract, transform, and load, and it's a widely used method for combining data from several systems into a single database, data store, data warehouse, or data lake. ETL can store legacy data or aggregate data to analyze and drive business choices, as is more common today.
Let's take a look at how cloud-based ETL works :
- Extraction: The process of extracting data from one or more sources online or on-premises is known as extraction.
- Transformation - Transforming data entails cleaning it and converting it to a standard format stored in a database, data store, warehouse, or data lake.
- Loading: The process of loading structured data into a target database, data store, data warehouse, or data lake is known as loading.
- ETL can help the Organization in Several Ways: data warehousing, Machine learning and artificial intelligence, Marketing data integration, IoT data integration, Database replication, and Cloud migration.
Multitenancy and Resource Pooling
- Multitenancy is a software program feature that allows one instance to serve multiple customers (tenants), separated from the others.
- Multi-tenancy models, which usually rely on virtualization technologies, allow cloud providers to pool their IT resources to serve numerous cloud service clients.
- This practice enables Big Data cloud resources to serve many multi-tenant clients in a location-independent manner, allowing resources to be dynamically assigned, reassigned on-demand, and accessed through a simple abstraction.
Product Packaging
- Packages are the real updates that are released in production. Packages are discrete bits of code that supply specialized features, services, or functions to the system via containerization.
- Package managers give the code a few metadata such as a version and a name, vendor information, a program description, and checksum information. The related package's metadata ensures that the package management knows the code's dependencies and requirements.
- Package managers minimize the need for manual install and update procedures and package all of the software's dependencies, allowing it to run in any environment.
Automation and Build Management
- Build management and automation are used by developers to compile code changes before releasing them. When a new package is made available, the built environment interacts with the other software components that comprise the whole solution.
- During build automation, scripts produce documentation, conduct previously defined tests, compile the code, and distribute the associated binaries.
Monitoring
- The way of reviewing, watching, and managing the operational process in a cloud-based IT infrastructure is known as cloud monitoring. Using manual or automated management strategies, websites, servers, applications, and other cloud infrastructures are checked for availability and performance. This ongoing assessment of resource levels, server response times, and implementation foreshadow potential vulnerability to future challenges.
- A proliferation of different performance solutions and microservice applications across infrastructures and networks can make cluster performance management extremely difficult in data center and cloud deployments. Increase the visibility of cloud deployments, accelerate cloud adoption, streamline IT operations, and provide excellent customer service.
Observability
- The capacity to obtain actionable insights from monitoring tool logs is referred to as observability. It provides us with a better understanding of the health and performance of your systems, apps, and infrastructure using these insights.
- Logs, traces, and metrics are sometimes referred to as the three pillars of observability.
- Most system components and applications generate logs, which contain time-series data regarding the system's or application's operation. The flow of logic within the application is tracked through traces. CPU/RAM reservation or utilization, disc space, network connectivity, and other metrics are available.
Continuous Feedback
Continuous feedback is critical to deployment and application release because it assesses the impact of each release on the user experience and reports that assessment to the DevOps team so that future releases may be improved.
There are two ways to collect feedback.
- Structured - Questionnaires, surveys, and focus groups are used to implement the structured method.
- Unstructured - Feedback, such as that received via Twitter, Facebook, and other social media platforms.
- User feedback on specific applications is becoming increasingly important as digital technology evolves and social media grows.

Conclusion: Embracing DevOps for Enhanced Software Delivery
It takes time to turn DevOps into an organizational attitude. Top-down support is essential for it to take hold. DevOps is a natural match for corporate cultures where openness and cooperation are the norms, especially with the emergence of Big data. It may take a little longer for those with more departmental boundaries or legacy bureaucracy to accomplish the shift.



























